 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMineRL: A Large-Scale Dataset of Minecraft Demonstrations
Jul 29, 2019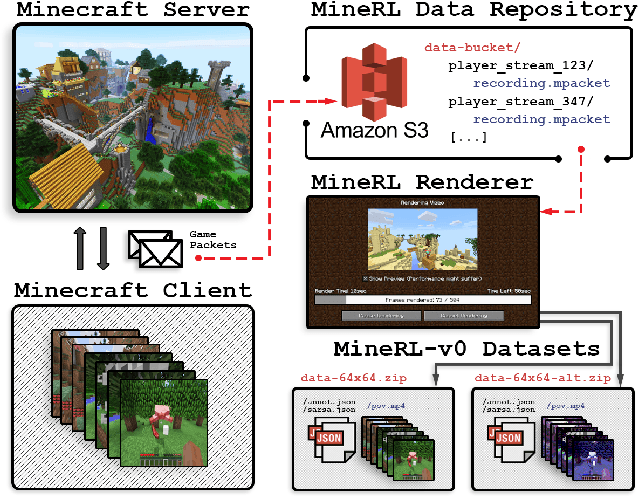
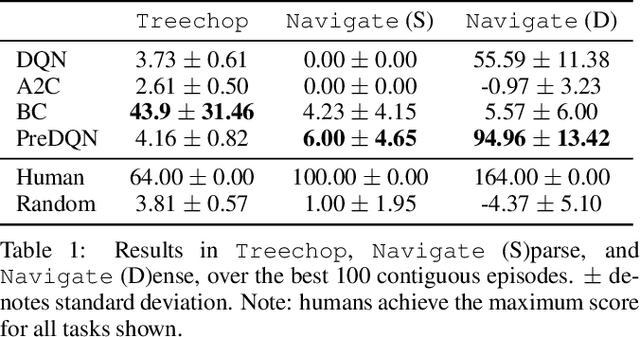
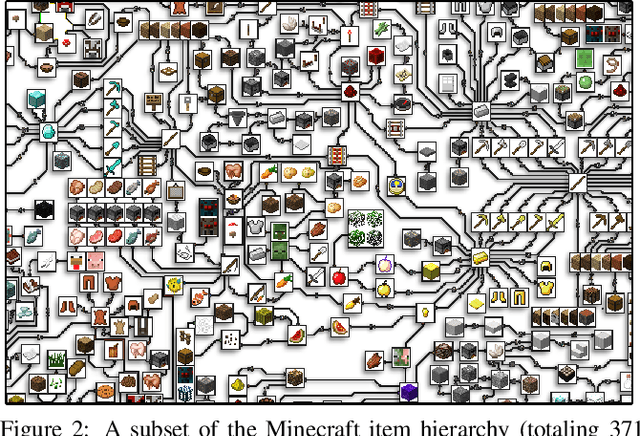

The sample inefficiency of standard deep reinforcement learning methods precludes their application to many real-world problems. Methods which leverage human demonstrations require fewer samples but have been researched less. As demonstrated in the computer vision and natural language processing communities, large-scale datasets have the capacity to facilitate research by serving as an experimental and benchmarking platform for new methods. However, existing datasets compatible with reinforcement learning simulators do not have sufficient scale, structure, and quality to enable the further development and evaluation of methods focused on using human examples. Therefore, we introduce a comprehensive, large-scale, simulator-paired dataset of human demonstrations: MineRL. The dataset consists of over 60 million automatically annotated state-action pairs across a variety of related tasks in Minecraft, a dynamic, 3D, open-world environment. We present a novel data collection scheme which allows for the ongoing introduction of new tasks and the gathering of complete state information suitable for a variety of methods. We demonstrate the hierarchality, diversity, and scale of the MineRL dataset. Further, we show the difficulty of the Minecraft domain along with the potential of MineRL in developing techniques to solve key research challenges within it.
Conservative Q-Improvement: Reinforcement Learning for an Interpretable Decision-Tree Policy
Jul 02, 2019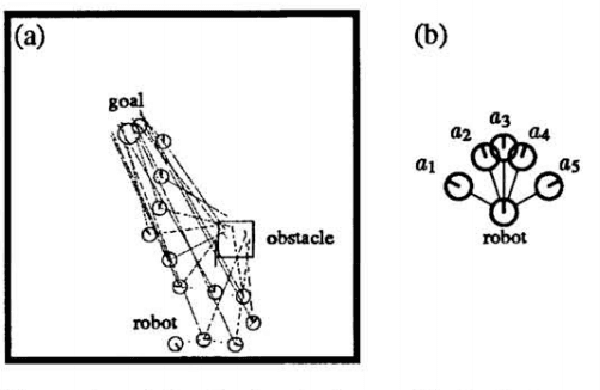
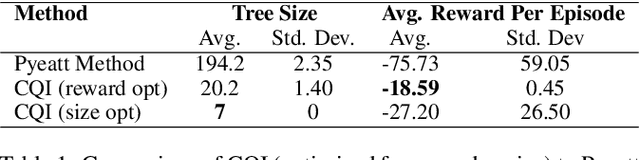
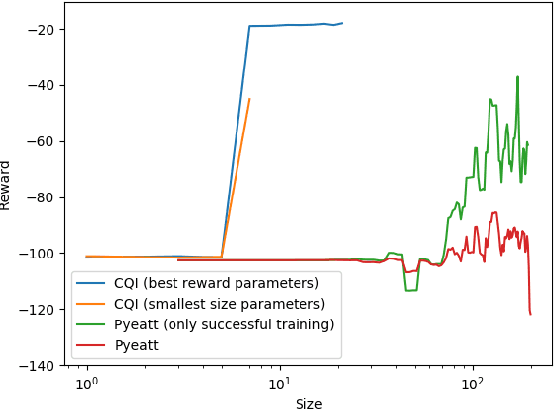
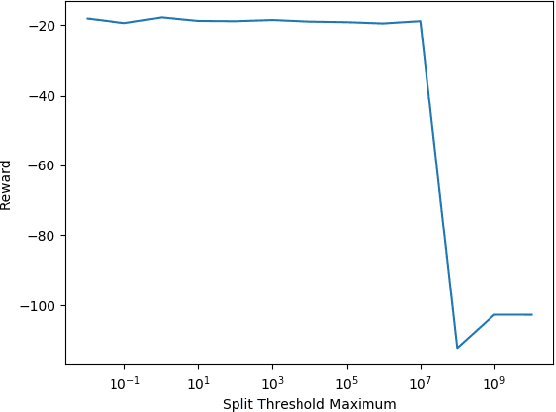
There is a growing desire in the field of reinforcement learning (and machine learning in general) to move from black-box models toward more "interpretable AI." We improve interpretability of reinforcement learning by increasing the utility of decision tree policies learned via reinforcement learning. These policies consist of a decision tree over the state space, which requires fewer parameters to express than traditional policy representations. Existing methods for creating decision tree policies via reinforcement learning focus on accurately representing an action-value function during training, but this leads to much larger trees than would otherwise be required. To address this shortcoming, we propose a novel algorithm which only increases tree size when the estimated discounted future reward of the overall policy would increase by a sufficient amount. Through evaluation in a simulated environment, we show that its performance is comparable or superior to traditional tree-based approaches and that it yields a more succinct policy. Additionally, we discuss tuning parameters to control the tradeoff between optimizing for smaller tree size or for overall reward.
Generation of Policy-Level Explanations for Reinforcement Learning
May 28, 2019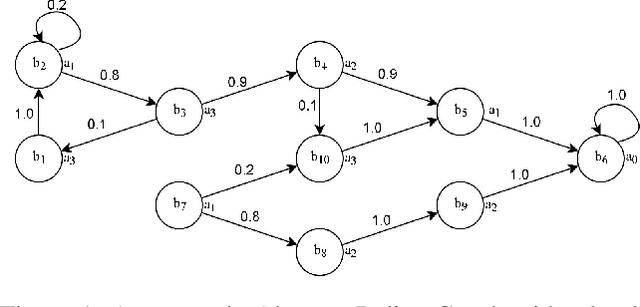
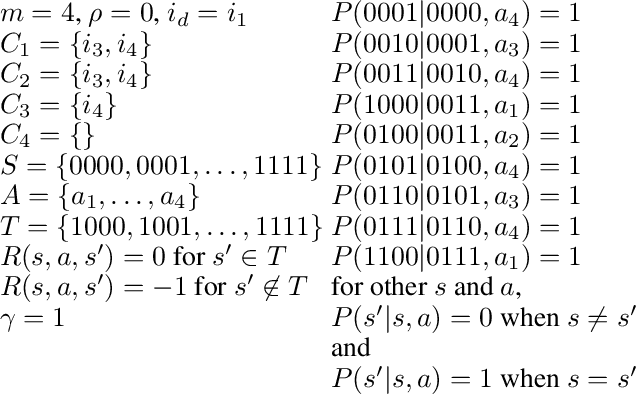
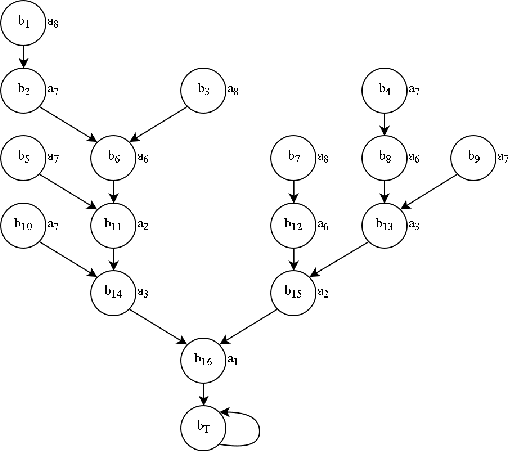
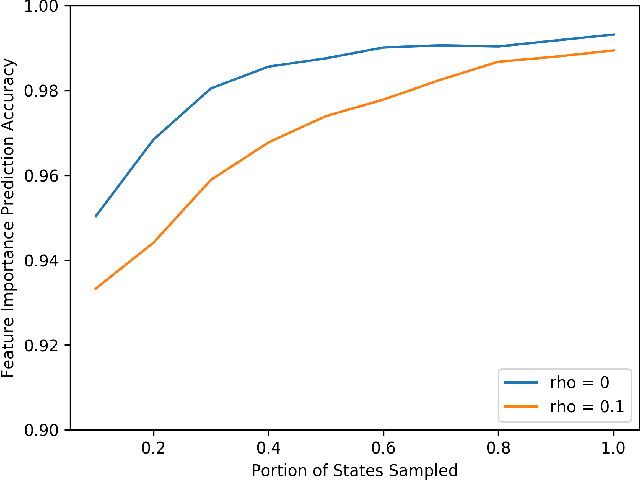
Though reinforcement learning has greatly benefited from the incorporation of neural networks, the inability to verify the correctness of such systems limits their use. Current work in explainable deep learning focuses on explaining only a single decision in terms of input features, making it unsuitable for explaining a sequence of decisions. To address this need, we introduce Abstracted Policy Graphs, which are Markov chains of abstract states. This representation concisely summarizes a policy so that individual decisions can be explained in the context of expected future transitions. Additionally, we propose a method to generate these Abstracted Policy Graphs for deterministic policies given a learned value function and a set of observed transitions, potentially off-policy transitions used during training. Since no restrictions are placed on how the value function is generated, our method is compatible with many existing reinforcement learning methods. We prove that the worst-case time complexity of our method is quadratic in the number of features and linear in the number of provided transitions, $O(|F|^2 |tr\_samples|)$. By applying our method to a family of domains, we show that our method scales well in practice and produces Abstracted Policy Graphs which reliably capture relationships within these domains.
The MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors
Apr 22, 2019
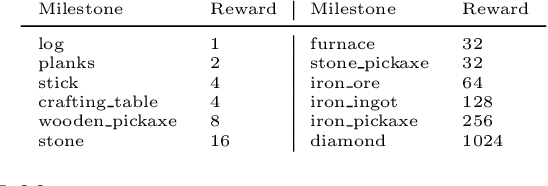
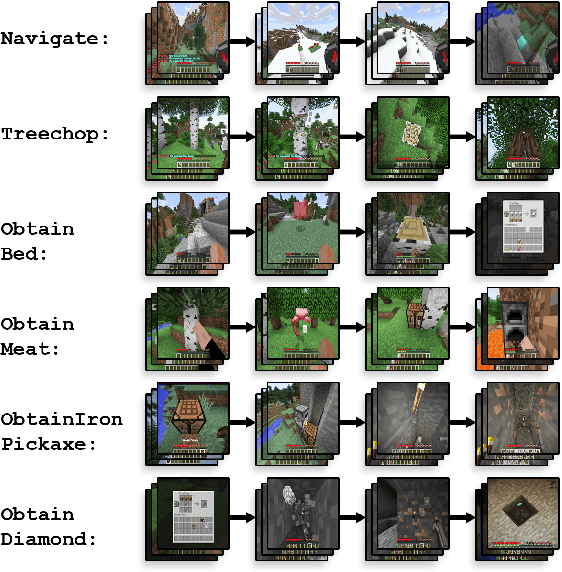
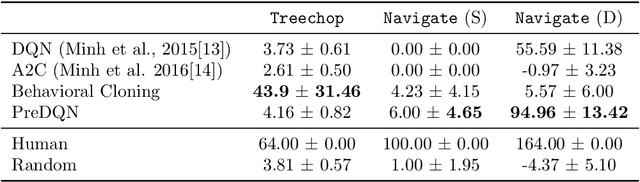
Though deep reinforcement learning has led to breakthroughs in many difficult domains, these successes have required an ever-increasing number of samples. As state-of-the-art reinforcement learning (RL) systems require an exponentially increasing number of samples, their development is restricted to a continually shrinking segment of the AI community. Likewise, many of these systems cannot be applied to real-world problems, where environment samples are expensive. Resolution of these limitations requires new, sample-efficient methods. To facilitate research in this direction, we introduce the MineRL Competition on Sample Efficient Reinforcement Learning using Human Priors. The primary goal of the competition is to foster the development of algorithms which can efficiently leverage human demonstrations to drastically reduce the number of samples needed to solve complex, hierarchical, and sparse environments. To that end, we introduce: (1) the Minecraft ObtainDiamond task, a sequential decision making environment requiring long-term planning, hierarchical control, and efficient exploration methods; and (2) the MineRL-v0 dataset, a large-scale collection of over 60 million state-action pairs of human demonstrations that can be resimulated into embodied trajectories with arbitrary modifications to game state and visuals. Participants will compete to develop systems which solve the ObtainDiamond task with a limited number of samples from the environment simulator, Malmo. The competition is structured into two rounds in which competitors are provided several paired versions of the dataset and environment with different game textures. At the end of each round, competitors will submit containerized versions of their learning algorithms and they will then be trained/evaluated from scratch on a hold-out dataset-environment pair for a total of 4-days on a prespecified hardware platform.
Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates
May 17, 2018In this paper, we describe a phenomenon, which we named "super-convergence", where neural networks can be trained an order of magnitude faster than with standard training methods. The existence of super-convergence is relevant to understanding why deep networks generalize well. One of the key elements of super-convergence is training with one learning rate cycle and a large maximum learning rate. A primary insight that allows super-convergence training is that large learning rates regularize the training, hence requiring a reduction of all other forms of regularization in order to preserve an optimal regularization balance. We also derive a simplification of the Hessian Free optimization method to compute an estimate of the optimal learning rate. Experiments demonstrate super-convergence for Cifar-10/100, MNIST and Imagenet datasets, and resnet, wide-resnet, densenet, and inception architectures. In addition, we show that super-convergence provides a greater boost in performance relative to standard training when the amount of labeled training data is limited. The architectures and code to replicate the figures in this paper are available at github.com/lnsmith54/super-convergence. See http://www.fast.ai/2018/04/30/dawnbench-fastai/ for an application of super-convergence to win the DAWNBench challenge (see https://dawn.cs.stanford.edu/benchmark/).
Exploring loss function topology with cyclical learning rates
Feb 14, 2017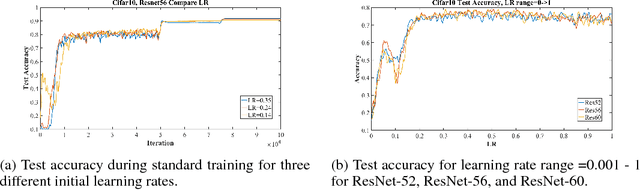
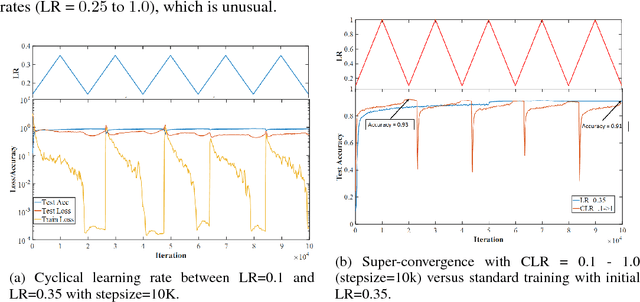
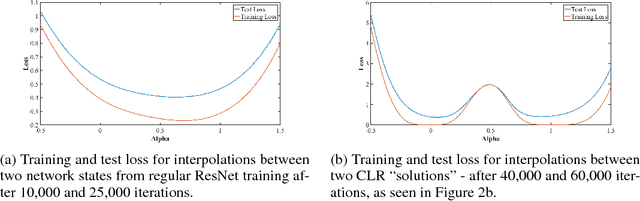
We present observations and discussion of previously unreported phenomena discovered while training residual networks. The goal of this work is to better understand the nature of neural networks through the examination of these new empirical results. These behaviors were identified through the application of Cyclical Learning Rates (CLR) and linear network interpolation. Among these behaviors are counterintuitive increases and decreases in training loss and instances of rapid training. For example, we demonstrate how CLR can produce greater testing accuracy than traditional training despite using large learning rates. Files to replicate these results are available at https://github.com/lnsmith54/exploring-loss
Deep Convolutional Neural Network Design Patterns
Nov 14, 2016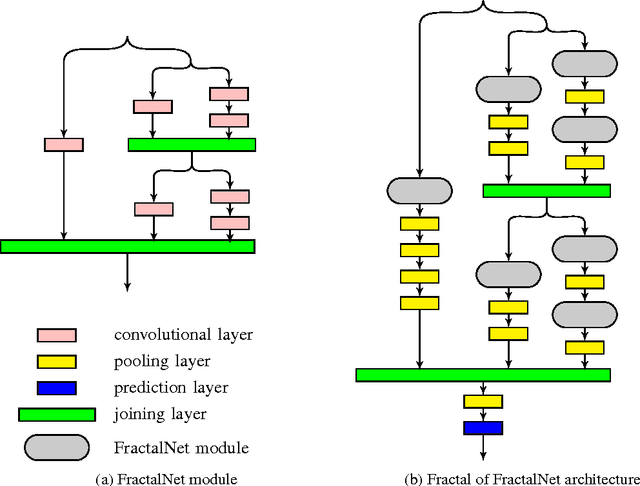
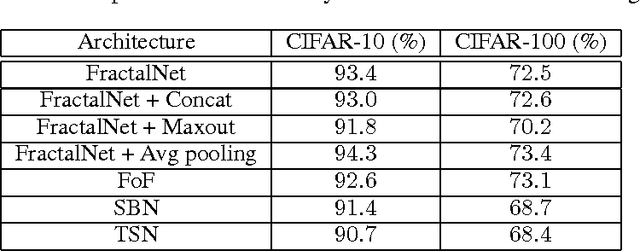
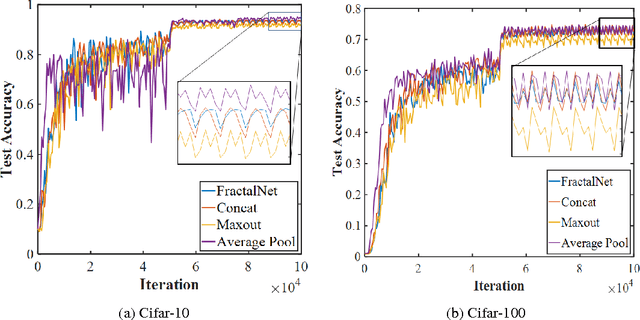
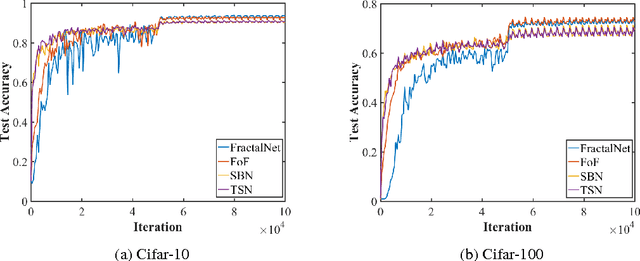
Recent research in the deep learning field has produced a plethora of new architectures. At the same time, a growing number of groups are applying deep learning to new applications. Some of these groups are likely to be composed of inexperienced deep learning practitioners who are baffled by the dizzying array of architecture choices and therefore opt to use an older architecture (i.e., Alexnet). Here we attempt to bridge this gap by mining the collective knowledge contained in recent deep learning research to discover underlying principles for designing neural network architectures. In addition, we describe several architectural innovations, including Fractal of FractalNet network, Stagewise Boosting Networks, and Taylor Series Networks (our Caffe code and prototxt files is available at https://github.com/iPhysicist/CNNDesignPatterns). We hope others are inspired to build on our preliminary work.