 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexLLM: Composable HLS Library for Flexible Hybrid LLM Accelerator Design
Jan 22, 2026We present FlexLLM, a composable High-Level Synthesis (HLS) library for rapid development of domain-specific LLM accelerators. FlexLLM exposes key architectural degrees of freedom for stage-customized inference, enabling hybrid designs that tailor temporal reuse and spatial dataflow differently for prefill and decode, and provides a comprehensive quantization suite to support accurate low-bit deployment. Using FlexLLM, we build a complete inference system for the Llama-3.2 1B model in under two months with only 1K lines of code. The system includes: (1) a stage-customized accelerator with hardware-efficient quantization (12.68 WikiText-2 PPL) surpassing SpinQuant baseline, and (2) a Hierarchical Memory Transformer (HMT) plug-in for efficient long-context processing. On the AMD U280 FPGA at 16nm, the accelerator achieves 1.29$\times$ end-to-end speedup, 1.64$\times$ higher decode throughput, and 3.14$\times$ better energy efficiency than an NVIDIA A100 GPU (7nm) running BF16 inference; projected results on the V80 FPGA at 7nm reach 4.71$\times$, 6.55$\times$, and 4.13$\times$, respectively. In long-context scenarios, integrating the HMT plug-in reduces prefill latency by 23.23$\times$ and extends the context window by 64$\times$, delivering 1.10$\times$/4.86$\times$ lower end-to-end latency and 5.21$\times$/6.27$\times$ higher energy efficiency on the U280/V80 compared to the A100 baseline. FlexLLM thus bridges algorithmic innovation in LLM inference and high-performance accelerators with minimal manual effort.
SYQ: Learning Symmetric Quantization For Efficient Deep Neural Networks
Jul 01, 2018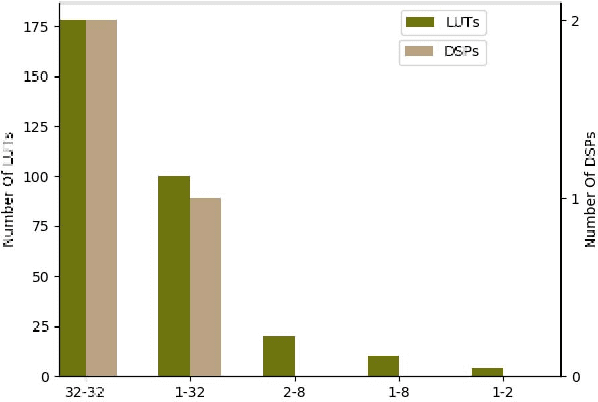
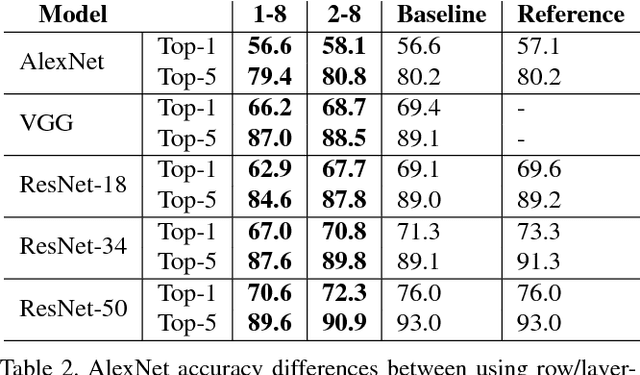
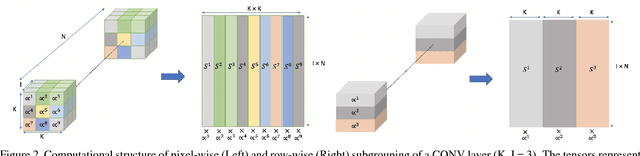
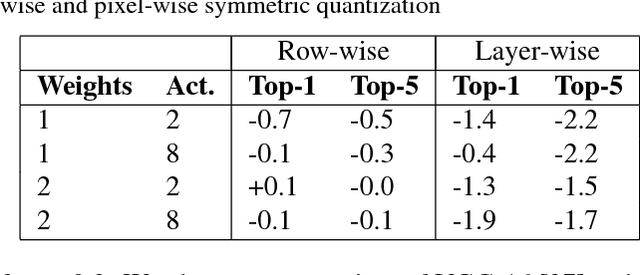
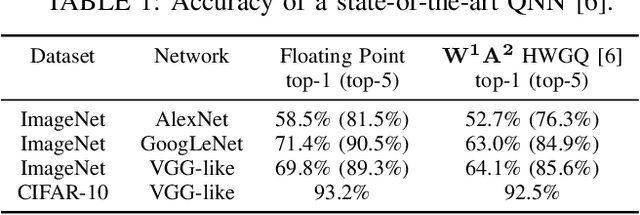
Inference for state-of-the-art deep neural networks is computationally expensive, making them difficult to deploy on constrained hardware environments. An efficient way to reduce this complexity is to quantize the weight parameters and/or activations during training by approximating their distributions with a limited entry codebook. For very low-precisions, such as binary or ternary networks with 1-8-bit activations, the information loss from quantization leads to significant accuracy degradation due to large gradient mismatches between the forward and backward functions. In this paper, we introduce a quantization method to reduce this loss by learning a symmetric codebook for particular weight subgroups. These subgroups are determined based on their locality in the weight matrix, such that the hardware simplicity of the low-precision representations is preserved. Empirically, we show that symmetric quantization can substantially improve accuracy for networks with extremely low-precision weights and activations. We also demonstrate that this representation imposes minimal or no hardware implications to more coarse-grained approaches. Source code is available at https://www.github.com/julianfaraone/SYQ.
Scaling Neural Network Performance through Customized Hardware Architectures on Reconfigurable Logic
Jun 26, 2018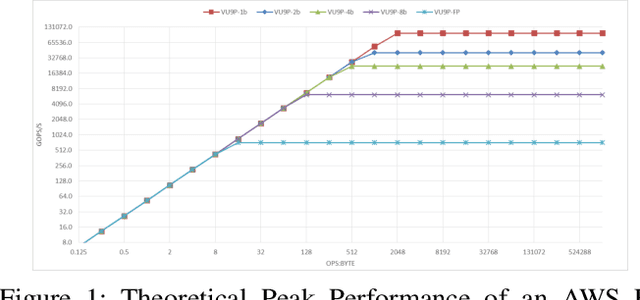

Convolutional Neural Networks have dramatically improved in recent years, surpassing human accuracy on certain problems and performance exceeding that of traditional computer vision algorithms. While the compute pattern in itself is relatively simple, significant compute and memory challenges remain as CNNs may contain millions of floating-point parameters and require billions of floating-point operations to process a single image. These computational requirements, combined with storage footprints that exceed typical cache sizes, pose a significant performance and power challenge for modern compute architectures. One of the promising opportunities to scale performance and power efficiency is leveraging reduced precision representations for all activations and weights as this allows to scale compute capabilities, reduce weight and feature map buffering requirements as well as energy consumption. While a small reduction in accuracy is encountered, these Quantized Neural Networks have been shown to achieve state-of-the-art accuracy on standard benchmark datasets, such as MNIST, CIFAR-10, SVHN and even ImageNet, and thus provide highly attractive design trade-offs. Current research has focused mainly on the implementation of extreme variants with full binarization of weights and or activations, as well typically smaller input images. Within this paper, we investigate the scalability of dataflow architectures with respect to supporting various precisions for both weights and activations, larger image dimensions, and increasing numbers of feature map channels. Key contributions are a formalized approach to understanding the scalability of the existing hardware architecture with cost models and a performance prediction as a function of the target device size. We provide validating experimental results for an ImageNet classification on a server-class platform, namely the AWS F1 node.
Inference of Quantized Neural Networks on Heterogeneous All-Programmable Devices
Jun 21, 2018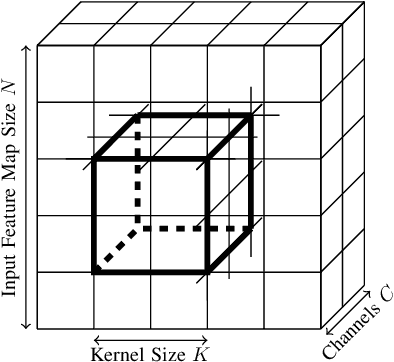
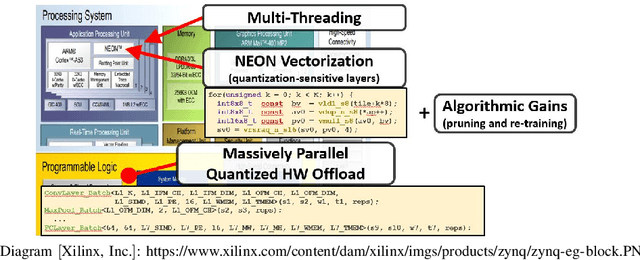

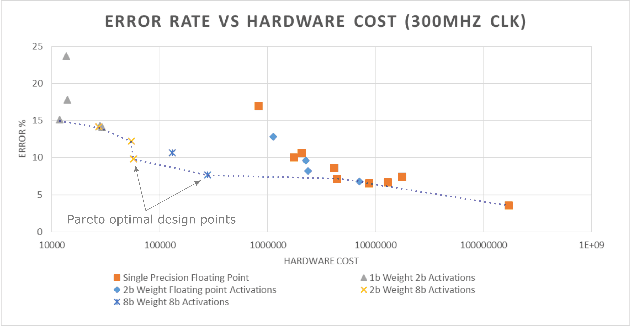
Neural networks have established as a generic and powerful means to approach challenging problems such as image classification, object detection or decision making. Their successful employment foots on an enormous demand of compute. The quantization of network parameters and the processed data has proven a valuable measure to reduce the challenges of network inference so effectively that the feasible scope of applications is expanded even into the embedded domain. This paper describes the making of a real-time object detection in a live video stream processed on an embedded all-programmable device. The presented case illustrates how the required processing is tamed and parallelized across both the CPU cores and the programmable logic and how the most suitable resources and powerful extensions, such as NEON vectorization, are leveraged for the individual processing steps. The crafted result is an extended Darknet framework implementing a fully integrated, end-to-end solution from video capture over object annotation to video output applying neural network inference at different quantization levels running at 16~frames per second on an embedded Zynq UltraScale+ (XCZU3EG) platform.
Quantizing Convolutional Neural Networks for Low-Power High-Throughput Inference Engines
May 21, 2018
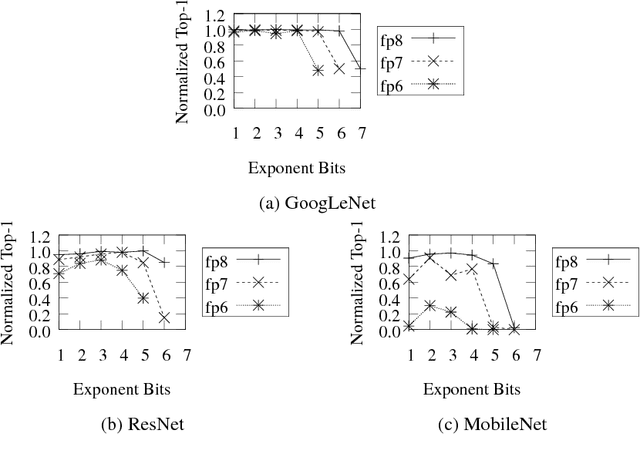
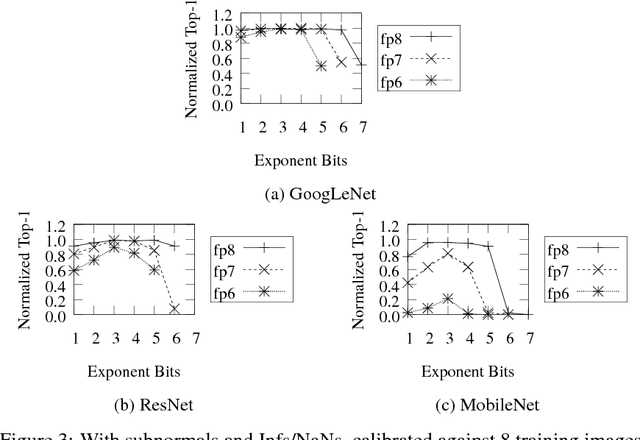
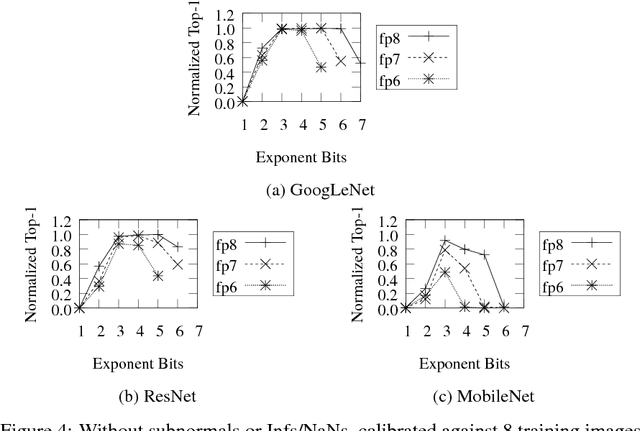
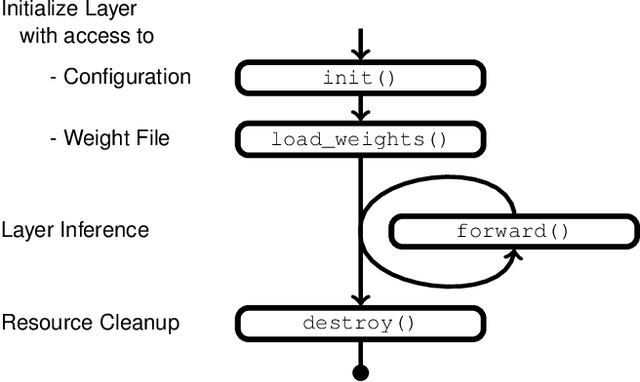
Deep learning as a means to inferencing has proliferated thanks to its versatility and ability to approach or exceed human-level accuracy. These computational models have seemingly insatiable appetites for computational resources not only while training, but also when deployed at scales ranging from data centers all the way down to embedded devices. As such, increasing consideration is being made to maximize the computational efficiency given limited hardware and energy resources and, as a result, inferencing with reduced precision has emerged as a viable alternative to the IEEE 754 Standard for Floating-Point Arithmetic. We propose a quantization scheme that allows inferencing to be carried out using arithmetic that is fundamentally more efficient when compared to even half-precision floating-point. Our quantization procedure is significant in that we determine our quantization scheme parameters by calibrating against its reference floating-point model using a single inference batch rather than (re)training and achieve end-to-end post quantization accuracies comparable to the reference model.
Compressing Low Precision Deep Neural Networks Using Sparsity-Induced Regularization in Ternary Networks
Oct 10, 2017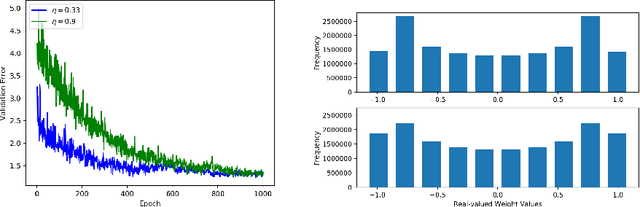
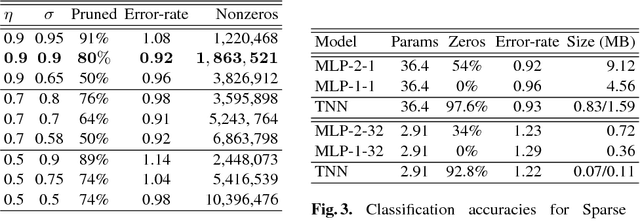
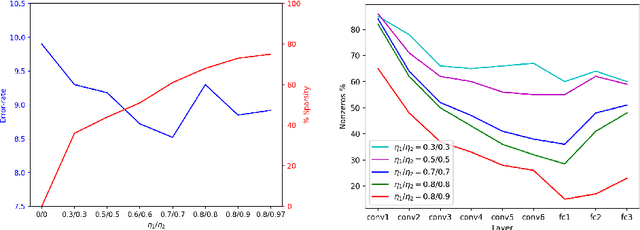
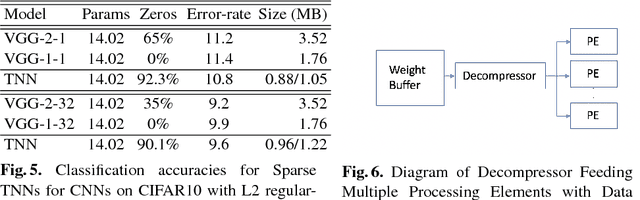
A low precision deep neural network training technique for producing sparse, ternary neural networks is presented. The technique incorporates hard- ware implementation costs during training to achieve significant model compression for inference. Training involves three stages: network training using L2 regularization and a quantization threshold regularizer, quantization pruning, and finally retraining. Resulting networks achieve improved accuracy, reduced memory footprint and reduced computational complexity compared with conventional methods, on MNIST and CIFAR10 datasets. Our networks are up to 98% sparse and 5 & 11 times smaller than equivalent binary and ternary models, translating to significant resource and speed benefits for hardware implementations.