 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsolved Problems in ML Safety
Sep 28, 2021
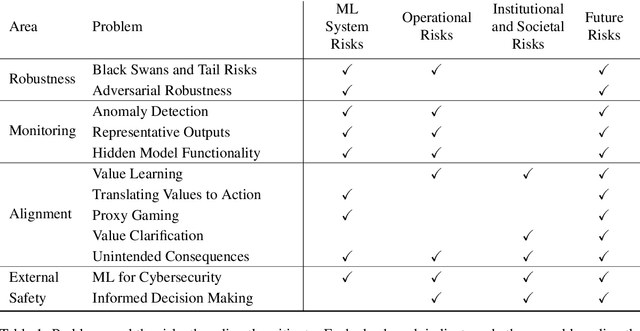

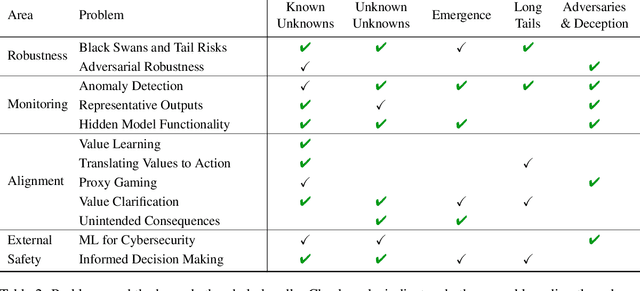
Machine learning (ML) systems are rapidly increasing in size, are acquiring new capabilities, and are increasingly deployed in high-stakes settings. As with other powerful technologies, safety for ML should be a leading research priority. In response to emerging safety challenges in ML, such as those introduced by recent large-scale models, we provide a new roadmap for ML Safety and refine the technical problems that the field needs to address. We present four problems ready for research, namely withstanding hazards ("Robustness"), identifying hazards ("Monitoring"), steering ML systems ("Alignment"), and reducing risks to how ML systems are handled ("External Safety"). Throughout, we clarify each problem's motivation and provide concrete research directions.
Deduplicating Training Data Makes Language Models Better
Jul 14, 2021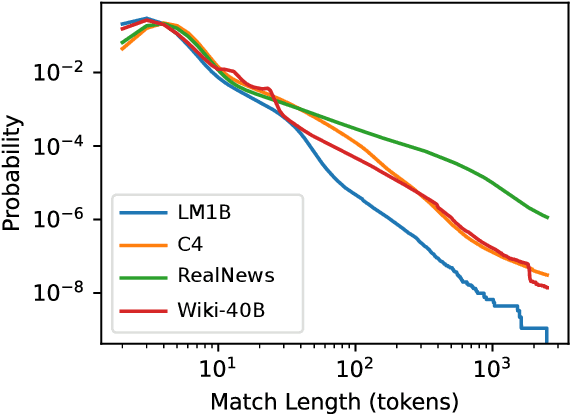
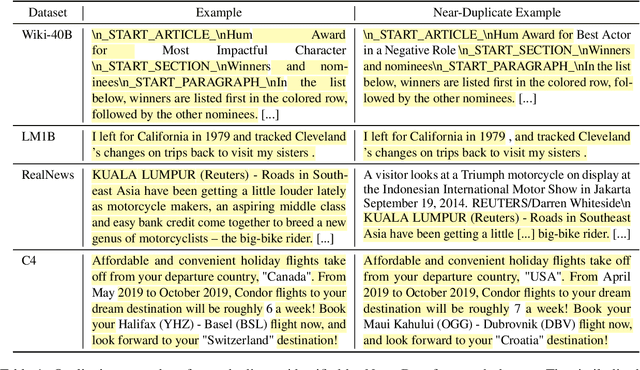
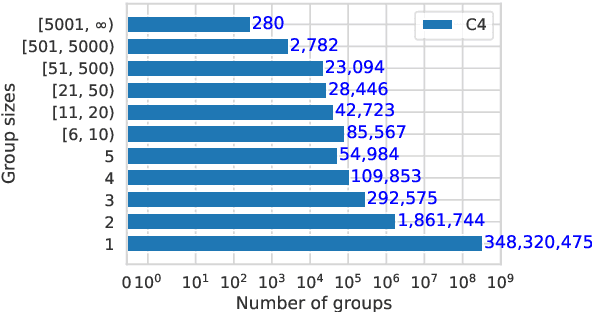
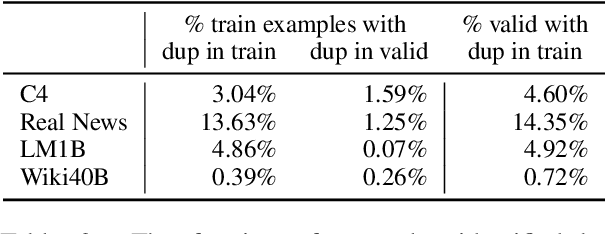
We find that existing language modeling datasets contain many near-duplicate examples and long repetitive substrings. As a result, over 1% of the unprompted output of language models trained on these datasets is copied verbatim from the training data. We develop two tools that allow us to deduplicate training datasets -- for example removing from C4 a single 61 word English sentence that is repeated over 60,000 times. Deduplication allows us to train models that emit memorized text ten times less frequently and require fewer train steps to achieve the same or better accuracy. We can also reduce train-test overlap, which affects over 4% of the validation set of standard datasets, thus allowing for more accurate evaluation. We release code for reproducing our work and performing dataset deduplication at https://github.com/google-research/deduplicate-text-datasets.
Evading Adversarial Example Detection Defenses with Orthogonal Projected Gradient Descent
Jun 28, 2021
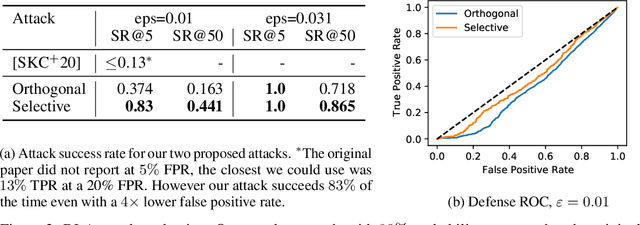
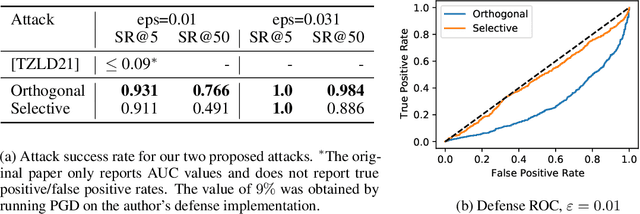
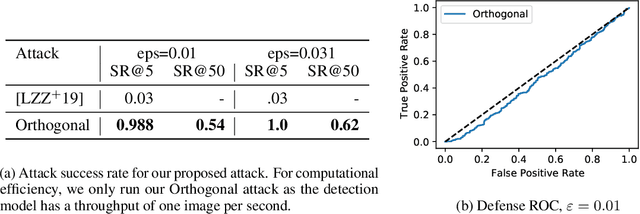
Evading adversarial example detection defenses requires finding adversarial examples that must simultaneously (a) be misclassified by the model and (b) be detected as non-adversarial. We find that existing attacks that attempt to satisfy multiple simultaneous constraints often over-optimize against one constraint at the cost of satisfying another. We introduce Orthogonal Projected Gradient Descent, an improved attack technique to generate adversarial examples that avoids this problem by orthogonalizing the gradients when running standard gradient-based attacks. We use our technique to evade four state-of-the-art detection defenses, reducing their accuracy to 0% while maintaining a 0% detection rate.
Indicators of Attack Failure: Debugging and Improving Optimization of Adversarial Examples
Jun 18, 2021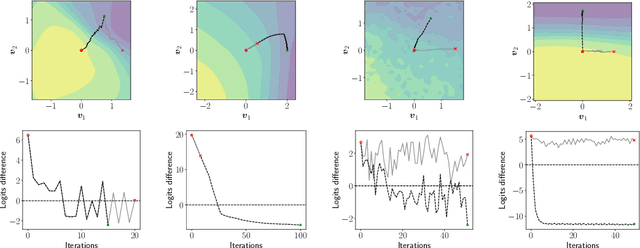
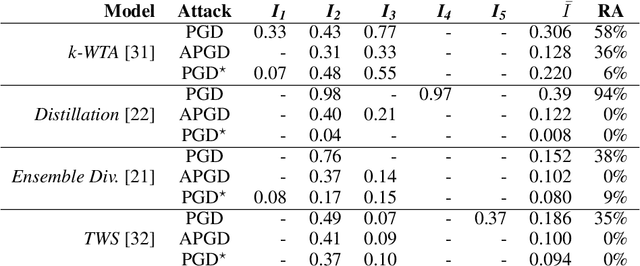
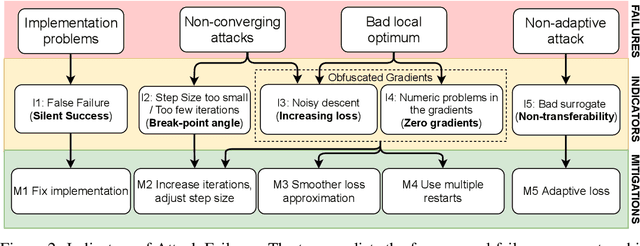
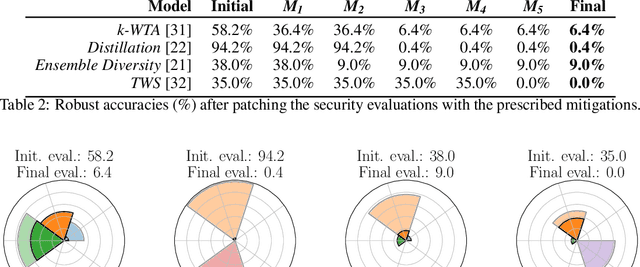
Evaluating robustness of machine-learning models to adversarial examples is a challenging problem. Many defenses have been shown to provide a false sense of security by causing gradient-based attacks to fail, and they have been broken under more rigorous evaluations. Although guidelines and best practices have been suggested to improve current adversarial robustness evaluations, the lack of automatic testing and debugging tools makes it difficult to apply these recommendations in a systematic manner. In this work, we overcome these limitations by (i) defining a set of quantitative indicators which unveil common failures in the optimization of gradient-based attacks, and (ii) proposing specific mitigation strategies within a systematic evaluation protocol. Our extensive experimental analysis shows that the proposed indicators of failure can be used to visualize, debug and improve current adversarial robustness evaluations, providing a first concrete step towards automatizing and systematizing current adversarial robustness evaluations. Our open-source code is available at: https://github.com/pralab/IndicatorsOfAttackFailure.
Poisoning and Backdooring Contrastive Learning
Jun 17, 2021
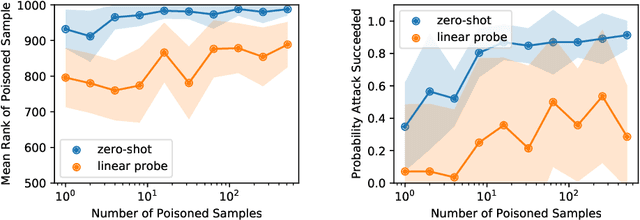
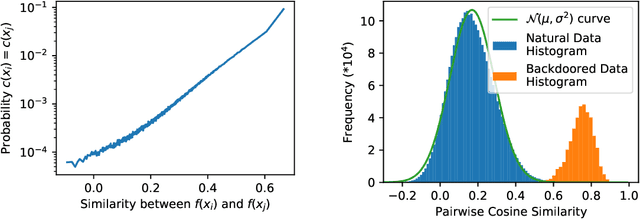
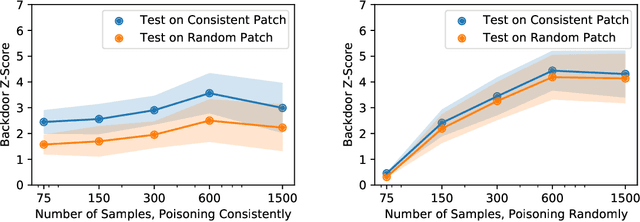
Contrastive learning methods like CLIP train on noisy and uncurated training datasets. This is cheaper than labeling datasets manually, and even improves out-of-distribution robustness. We show that this practice makes backdoor and poisoning attacks a significant threat. By poisoning just 0.005% of a dataset (e.g., just 150 images of the 3 million-example Conceptual Captions dataset), we can cause the model to misclassify test images by overlaying a small patch. Targeted poisoning attacks, whereby the model misclassifies a particular test input with an adversarially-desired label, are even easier requiring control of less than 0.0001% of the dataset (e.g., just two out of the 3 million images). Our attacks call into question whether training on noisy and uncurated Internet scrapes is desirable.
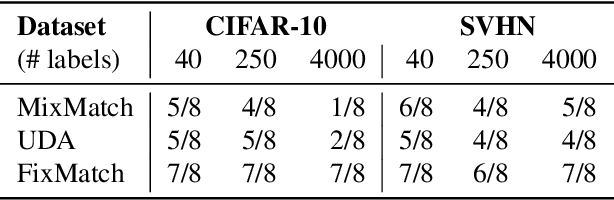
AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation
Jun 08, 2021
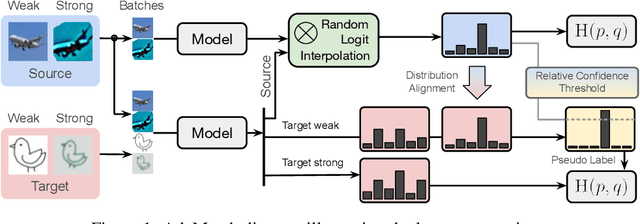

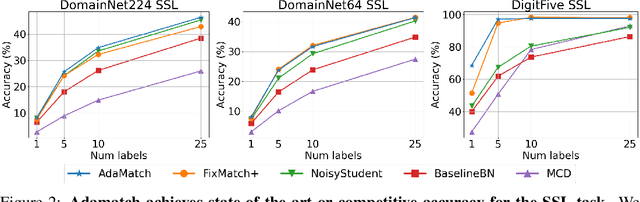
We extend semi-supervised learning to the problem of domain adaptation to learn significantly higher-accuracy models that train on one data distribution and test on a different one. With the goal of generality, we introduce AdaMatch, a method that unifies the tasks of unsupervised domain adaptation (UDA), semi-supervised learning (SSL), and semi-supervised domain adaptation (SSDA). In an extensive experimental study, we compare its behavior with respective state-of-the-art techniques from SSL, SSDA, and UDA on vision classification tasks. We find AdaMatch either matches or significantly exceeds the state-of-the-art in each case using the same hyper-parameters regardless of the dataset or task. For example, AdaMatch nearly doubles the accuracy compared to that of the prior state-of-the-art on the UDA task for DomainNet and even exceeds the accuracy of the prior state-of-the-art obtained with pre-training by 6.4% when AdaMatch is trained completely from scratch. Furthermore, by providing AdaMatch with just one labeled example per class from the target domain (i.e., the SSDA setting), we increase the target accuracy by an additional 6.1%, and with 5 labeled examples, by 13.6%.
Handcrafted Backdoors in Deep Neural Networks
Jun 08, 2021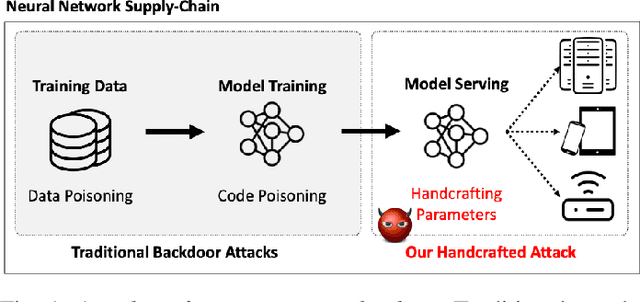
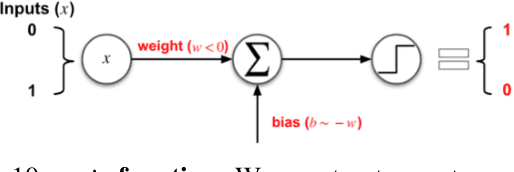
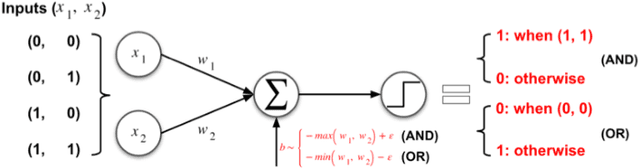
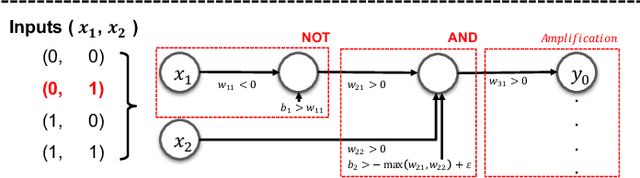
Deep neural networks (DNNs), while accurate, are expensive to train. Many practitioners, therefore, outsource the training process to third parties or use pre-trained DNNs. This practice makes DNNs vulnerable to $backdoor$ $attacks$: the third party who trains the model may act maliciously to inject hidden behaviors into the otherwise accurate model. Until now, the mechanism to inject backdoors has been limited to $poisoning$. We argue that such a supply-chain attacker has more attack techniques available. To study this hypothesis, we introduce a handcrafted attack that directly manipulates the parameters of a pre-trained model to inject backdoors. Our handcrafted attacker has more degrees of freedom in manipulating model parameters than poisoning. This makes it difficult for a defender to identify or remove the manipulations with straightforward methods, such as statistical analysis, adding random noises to model parameters, or clipping their values within a certain range. Further, our attacker can combine the handcrafting process with additional techniques, $e.g.$, jointly optimizing a trigger pattern, to inject backdoors into complex networks effectively$-$the meet-in-the-middle attack. In evaluations, our handcrafted backdoors remain effective across four datasets and four network architectures with a success rate above 96%. Our backdoored models are resilient to both parameter-level backdoor removal techniques and can evade existing defenses by slightly changing the backdoor attack configurations. Moreover, we demonstrate the feasibility of suppressing unwanted behaviors otherwise caused by poisoning. Our results suggest that further research is needed for understanding the complete space of supply-chain backdoor attacks.
Poisoning the Unlabeled Dataset of Semi-Supervised Learning
May 04, 2021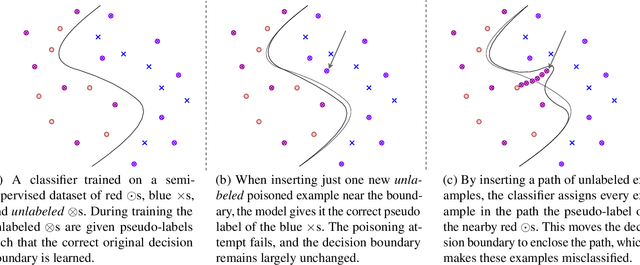

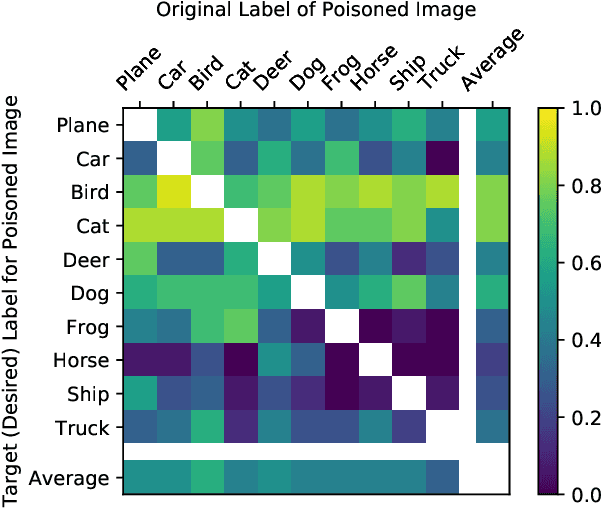
Semi-supervised machine learning models learn from a (small) set of labeled training examples, and a (large) set of unlabeled training examples. State-of-the-art models can reach within a few percentage points of fully-supervised training, while requiring 100x less labeled data. We study a new class of vulnerabilities: poisoning attacks that modify the unlabeled dataset. In order to be useful, unlabeled datasets are given strictly less review than labeled datasets, and adversaries can therefore poison them easily. By inserting maliciously-crafted unlabeled examples totaling just 0.1% of the dataset size, we can manipulate a model trained on this poisoned dataset to misclassify arbitrary examples at test time (as any desired label). Our attacks are highly effective across datasets and semi-supervised learning methods. We find that more accurate methods (thus more likely to be used) are significantly more vulnerable to poisoning attacks, and as such better training methods are unlikely to prevent this attack. To counter this we explore the space of defenses, and propose two methods that mitigate our attack.
Adversary Instantiation: Lower Bounds for Differentially Private Machine Learning
Jan 11, 2021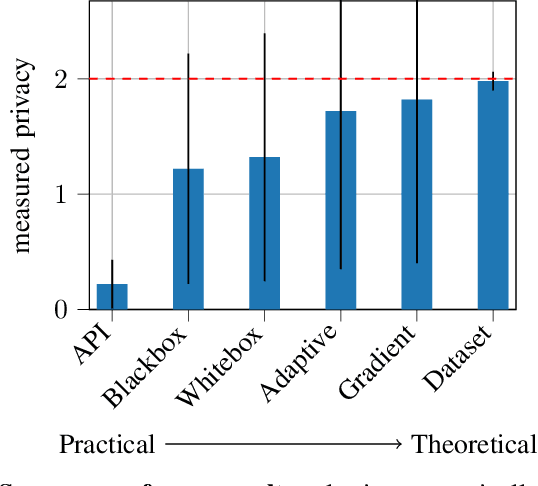
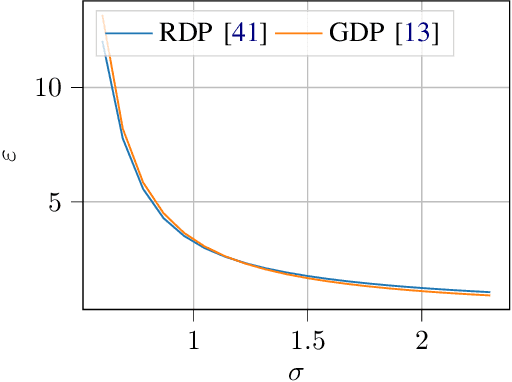
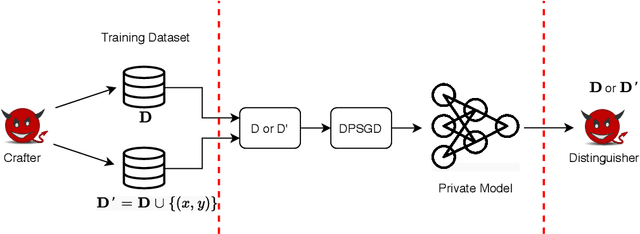
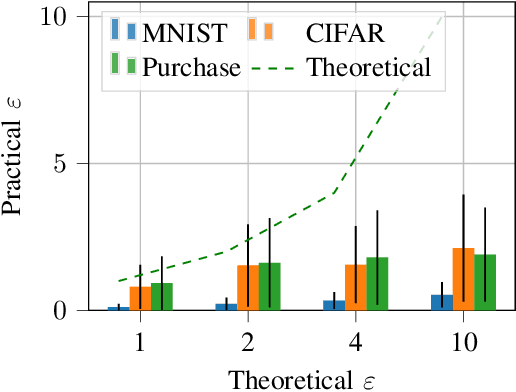
Differentially private (DP) machine learning allows us to train models on private data while limiting data leakage. DP formalizes this data leakage through a cryptographic game, where an adversary must predict if a model was trained on a dataset D, or a dataset D' that differs in just one example.If observing the training algorithm does not meaningfully increase the adversary's odds of successfully guessing which dataset the model was trained on, then the algorithm is said to be differentially private. Hence, the purpose of privacy analysis is to upper bound the probability that any adversary could successfully guess which dataset the model was trained on.In our paper, we instantiate this hypothetical adversary in order to establish lower bounds on the probability that this distinguishing game can be won. We use this adversary to evaluate the importance of the adversary capabilities allowed in the privacy analysis of DP training algorithms.For DP-SGD, the most common method for training neural networks with differential privacy, our lower bounds are tight and match the theoretical upper bound. This implies that in order to prove better upper bounds, it will be necessary to make use of additional assumptions. Fortunately, we find that our attacks are significantly weaker when additional (realistic)restrictions are put in place on the adversary's capabilities.Thus, in the practical setting common to many real-world deployments, there is a gap between our lower bounds and the upper bounds provided by the analysis: differential privacy is conservative and adversaries may not be able to leak as much information as suggested by the theoretical bound.
Extracting Training Data from Large Language Models
Dec 14, 2020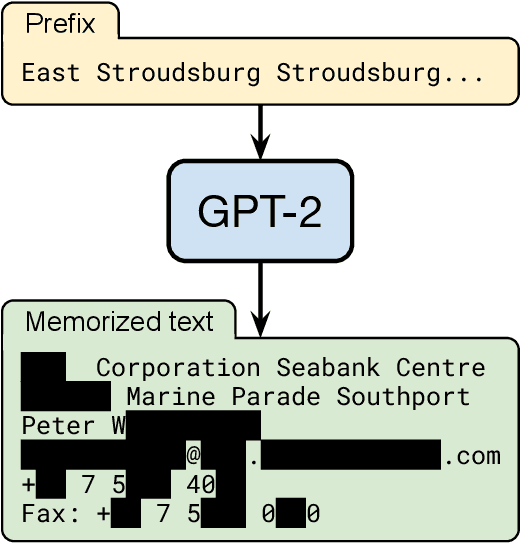
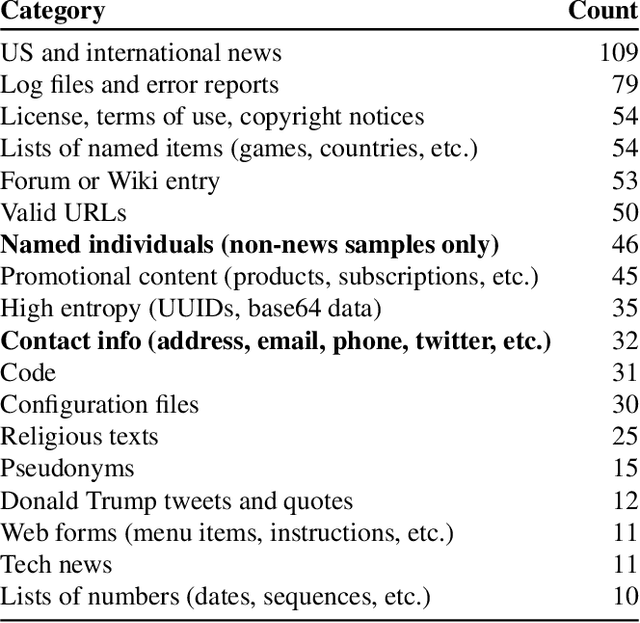
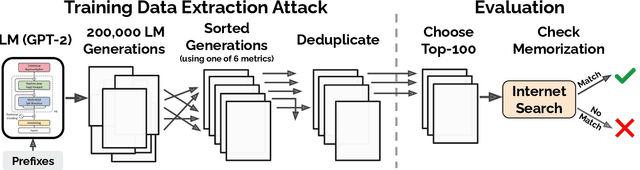
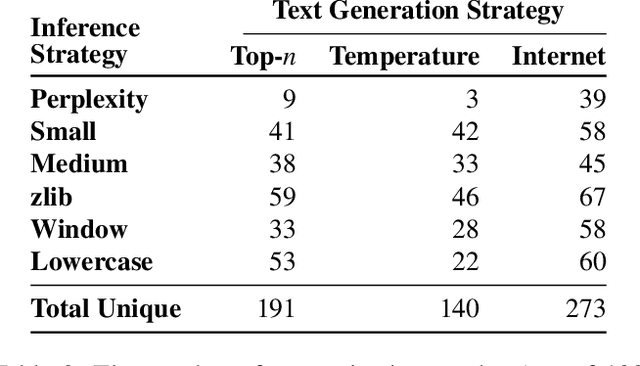
It has become common to publish large (billion parameter) language models that have been trained on private datasets. This paper demonstrates that in such settings, an adversary can perform a training data extraction attack to recover individual training examples by querying the language model. We demonstrate our attack on GPT-2, a language model trained on scrapes of the public Internet, and are able to extract hundreds of verbatim text sequences from the model's training data. These extracted examples include (public) personally identifiable information (names, phone numbers, and email addresses), IRC conversations, code, and 128-bit UUIDs. Our attack is possible even though each of the above sequences are included in just one document in the training data. We comprehensively evaluate our extraction attack to understand the factors that contribute to its success. For example, we find that larger models are more vulnerable than smaller models. We conclude by drawing lessons and discussing possible safeguards for training large language models.