 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFadeMem: Biologically-Inspired Forgetting for Efficient Agent Memory
Jan 26, 2026Large language models deployed as autonomous agents face critical memory limitations, lacking selective forgetting mechanisms that lead to either catastrophic forgetting at context boundaries or information overload within them. While human memory naturally balances retention and forgetting through adaptive decay processes, current AI systems employ binary retention strategies that preserve everything or lose it entirely. We propose FadeMem, a biologically-inspired agent memory architecture that incorporates active forgetting mechanisms mirroring human cognitive efficiency. FadeMem implements differential decay rates across a dual-layer memory hierarchy, where retention is governed by adaptive exponential decay functions modulated by semantic relevance, access frequency, and temporal patterns. Through LLM-guided conflict resolution and intelligent memory fusion, our system consolidates related information while allowing irrelevant details to fade. Experiments on Multi-Session Chat, LoCoMo, and LTI-Bench demonstrate superior multi-hop reasoning and retrieval with 45\% storage reduction, validating the effectiveness of biologically-inspired forgetting in agent memory systems.
Abstractive Summarization Improved by WordNet-based Extractive Sentences
Aug 04, 2018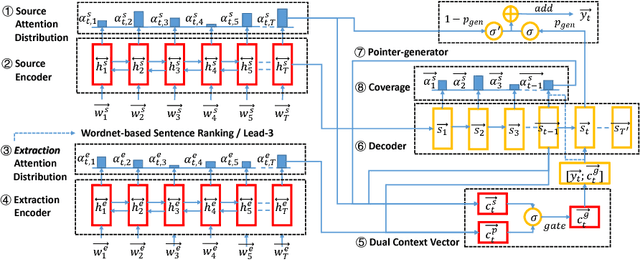

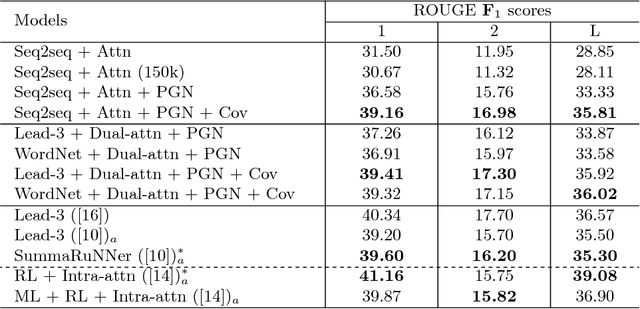

Recently, the seq2seq abstractive summarization models have achieved good results on the CNN/Daily Mail dataset. Still, how to improve abstractive methods with extractive methods is a good research direction, since extractive methods have their potentials of exploiting various efficient features for extracting important sentences in one text. In this paper, in order to improve the semantic relevance of abstractive summaries, we adopt the WordNet based sentence ranking algorithm to extract the sentences which are most semantically to one text. Then, we design a dual attentional seq2seq framework to generate summaries with consideration of the extracted information. At the same time, we combine pointer-generator and coverage mechanisms to solve the problems of out-of-vocabulary (OOV) words and duplicate words which exist in the abstractive models. Experiments on the CNN/Daily Mail dataset show that our models achieve competitive performance with the state-of-the-art ROUGE scores. Human evaluations also show that the summaries generated by our models have high semantic relevance to the original text.