 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeTF: One-stop Transformer Library for State-of-the-art Code LLM
May 31, 2023



Code intelligence plays a key role in transforming modern software engineering. Recently, deep learning-based models, especially Transformer-based large language models (LLMs), have demonstrated remarkable potential in tackling these tasks by leveraging massive open-source code data and programming language features. However, the development and deployment of such models often require expertise in both machine learning and software engineering, creating a barrier for the model adoption. In this paper, we present CodeTF, an open-source Transformer-based library for state-of-the-art Code LLMs and code intelligence. Following the principles of modular design and extensible framework, we design CodeTF with a unified interface to enable rapid access and development across different types of models, datasets and tasks. Our library supports a collection of pretrained Code LLM models and popular code benchmarks, including a standardized interface to train and serve code LLMs efficiently, and data features such as language-specific parsers and utility functions for extracting code attributes. In this paper, we describe the design principles, the architecture, key modules and components, and compare with other related library tools. Finally, we hope CodeTF is able to bridge the gap between machine learning/generative AI and software engineering, providing a comprehensive open-source solution for developers, researchers, and practitioners.
CodeT5+: Open Code Large Language Models for Code Understanding and Generation
May 20, 2023



Large language models (LLMs) pretrained on vast source code have achieved prominent progress in code intelligence. However, existing code LLMs have two main limitations in terms of architecture and pretraining tasks. First, they often adopt a specific architecture (encoder-only or decoder-only) or rely on a unified encoder-decoder network for different downstream tasks. The former paradigm is limited by inflexibility in applications while in the latter, the model is treated as a single system for all tasks, leading to suboptimal performance on a subset of tasks. Secondly, they often employ a limited set of pretraining objectives which might not be relevant to some downstream tasks and hence result in substantial performance degrade. To address these limitations, we propose ``CodeT5+'', a family of encoder-decoder LLMs for code in which component modules can be flexibly combined to suit a wide range of downstream code tasks. Such flexibility is enabled by our proposed mixture of pretraining objectives to mitigate the pretrain-finetune discrepancy. These objectives cover span denoising, contrastive learning, text-code matching, and causal LM pretraining tasks, on both unimodal and bimodal multilingual code corpora. Furthermore, we propose to initialize CodeT5+ with frozen off-the-shelf LLMs without training from scratch to efficiently scale up our models, and explore instruction-tuning to align with natural language instructions. We extensively evaluate CodeT5+ on over 20 code-related benchmarks in different settings, including zero-shot, finetuning, and instruction-tuning. We observe state-of-the-art (SoTA) model performance on various code-related tasks, such as code generation and completion, math programming, and text-to-code retrieval tasks. Particularly, our instruction-tuned CodeT5+ 16B achieves new SoTA results on HumanEval code generation task against other open code LLMs.
The Vault: A Comprehensive Multilingual Dataset for Advancing Code Understanding and Generation
May 09, 2023We present The Vault, an open-source, large-scale code-text dataset designed to enhance the training of code-focused large language models (LLMs). Existing open-source datasets for training code-based LLMs often face challenges in terms of size, quality (due to noisy signals), and format (only containing code function and text explanation pairings). The Vault overcomes these limitations by providing 40 million code-text pairs across 10 popular programming languages, thorough cleaning for 10+ prevalent issues, and various levels of code-text pairings, including class, function, and line levels. Researchers and practitioners can utilize The Vault for training diverse code-focused LLMs or incorporate the provided data cleaning methods and scripts to improve their datasets. By employing The Vault as the training dataset for code-centric LLMs, we anticipate significant advancements in code understanding and generation tasks, fostering progress in both artificial intelligence research and software development practices.
Class based Influence Functions for Error Detection
May 02, 2023



Influence functions (IFs) are a powerful tool for detecting anomalous examples in large scale datasets. However, they are unstable when applied to deep networks. In this paper, we provide an explanation for the instability of IFs and develop a solution to this problem. We show that IFs are unreliable when the two data points belong to two different classes. Our solution leverages class information to improve the stability of IFs. Extensive experiments show that our modification significantly improves the performance and stability of IFs while incurring no additional computational cost.
Better Language Models of Code through Self-Improvement
Apr 02, 2023



Pre-trained language models for code (PLMCs) have gained attention in recent research. These models are pre-trained on large-scale datasets using multi-modal objectives. However, fine-tuning them requires extensive supervision and is limited by the size of the dataset provided. We aim to improve this issue by proposing a simple data augmentation framework. Our framework utilizes knowledge gained during the pre-training and fine-tuning stage to generate pseudo data, which is then used as training data for the next step. We incorporate this framework into the state-of-the-art language models, such as CodeT5, CodeBERT, and UnixCoder. The results show that our framework significantly improves PLMCs' performance in code-related sequence generation tasks, such as code summarization and code generation in the CodeXGLUE benchmark.
Detect-Localize-Repair: A Unified Framework for Learning to Debug with CodeT5
Dec 22, 2022



Automated software debugging is a crucial task for improving the productivity of software developers. Many neural-based techniques have been proven effective for debugging-related tasks such as bug localization and program repair (or bug fixing). However, these techniques often focus only on either one of them or approach them in a stage-wise manner, ignoring the mutual benefits between them. In this work, we propose a novel unified \emph{Detect-Localize-Repair} framework based on a pretrained programming language model CodeT5 to seamlessly address these tasks, named CodeT5-DLR. Specifically, we propose three objectives to adapt the generic CodeT5 for debugging: a bug detection objective to determine whether a given code snippet is buggy or not, a bug localization objective to identify the buggy lines, and a program repair objective to translate the buggy code to its fixed version. We evaluate it on each of these tasks and their combined setting on two newly collected line-level debugging datasets in Java and Python. Extensive results show that our model significantly outperforms existing baselines from both NLP and software engineering domains.
Learning to Represent Programs with Code Hierarchies
May 31, 2022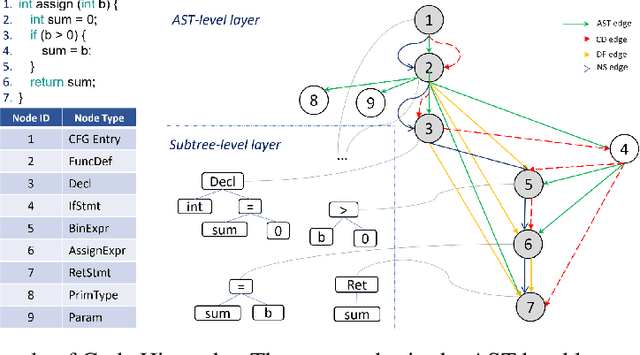
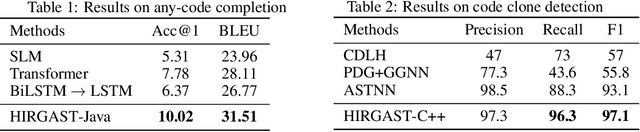
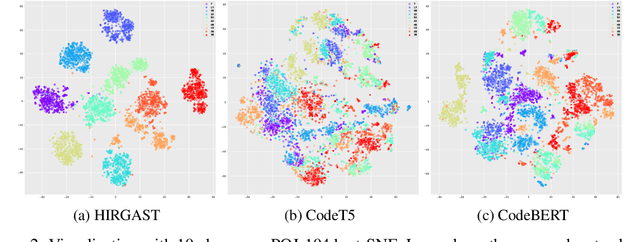
When used to process source code, graph neural networks have been shown to produce impressive results for a wide range of software engineering tasks. Existing techniques, however, still have two issues: (1) long-term dependency and (2) different code components are treated as equals when they should not be. To address these issues, we propose a method for representing code as a hierarchy (Code Hierarchy), in which different code components are represented separately at various levels of granularity. Then, to process each level of representation, we design a novel network architecture, HIRGAST, which combines the strengths of Heterogeneous Graph Transformer Networks and Tree-based Convolutional Neural Networks to learn Abstract Syntax Trees enriched with code dependency information. We also propose a novel pretraining objective called Missing Subtree Prediction to complement our Code Hierarchy. The evaluation results show that our method significantly outperforms other baselines in three downstream tasks: any-code completion, code classification, and code clone detection.
Energy-bounded Learning for Robust Models of Code
Dec 20, 2021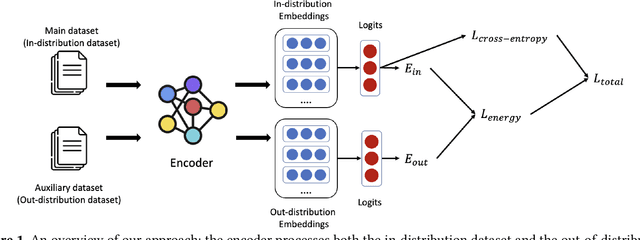
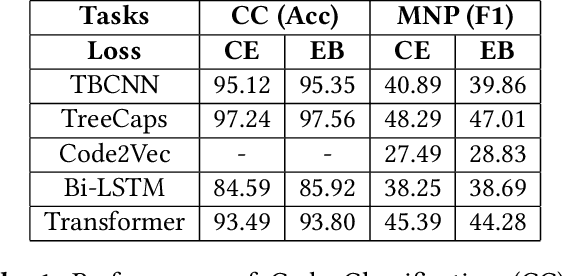
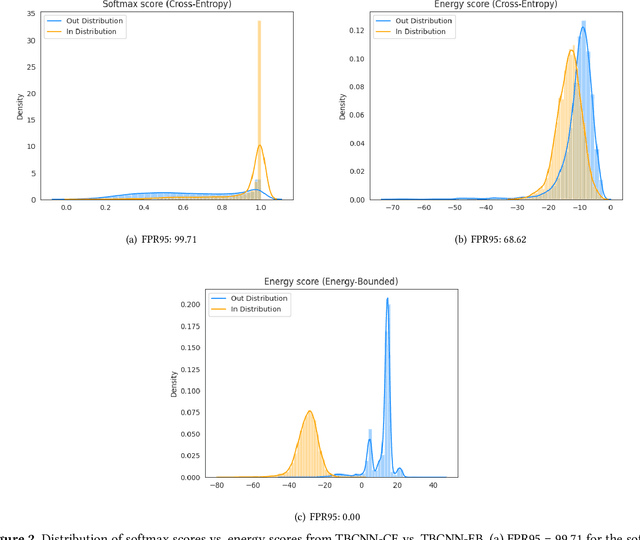

In programming, learning code representations has a variety of applications, including code classification, code search, comment generation, bug prediction, and so on. Various representations of code in terms of tokens, syntax trees, dependency graphs, code navigation paths, or a combination of their variants have been proposed, however, existing vanilla learning techniques have a major limitation in robustness, i.e., it is easy for the models to make incorrect predictions when the inputs are altered in a subtle way. To enhance the robustness, existing approaches focus on recognizing adversarial samples rather than on the valid samples that fall outside a given distribution, which we refer to as out-of-distribution (OOD) samples. Recognizing such OOD samples is the novel problem investigated in this paper. To this end, we propose to first augment the in=distribution datasets with out-of-distribution samples such that, when trained together, they will enhance the model's robustness. We propose the use of an energy-bounded learning objective function to assign a higher score to in-distribution samples and a lower score to out-of-distribution samples in order to incorporate such out-of-distribution samples into the training process of source code models. In terms of OOD detection and adversarial samples detection, our evaluation results demonstrate a greater robustness for existing source code models to become more accurate at recognizing OOD data while being more resistant to adversarial attacks at the same time. Furthermore, the proposed energy-bounded score outperforms all existing OOD detection scores by a large margin, including the softmax confidence score, the Mahalanobis score, and ODIN.
InferCode: Self-Supervised Learning of Code Representations by Predicting Subtrees
Dec 15, 2020

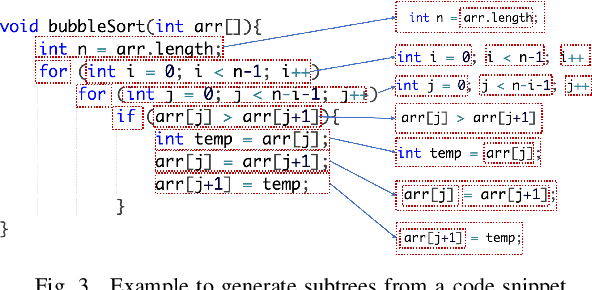
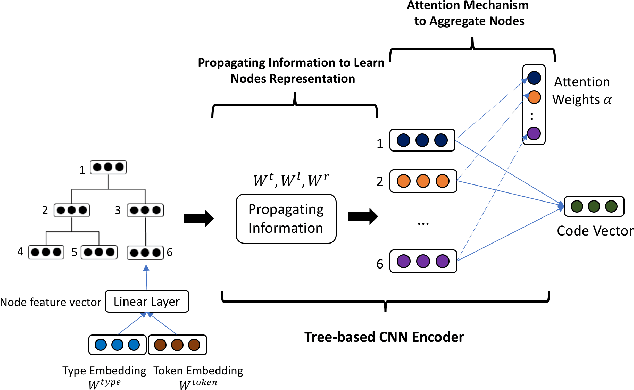
Building deep learning models on source code has found many successful software engineering applications, such as code search, code comment generation, bug detection, code migration, and so on. Current learning techniques, however, have a major drawback that these models are mostly trained on datasets labeled for particular downstream tasks, and code representations may not be suitable for other tasks. While some techniques produce representations from unlabeled code, they are far from satisfactory when applied to downstream tasks. Although certain techniques generate representations from unlabeled code when applied to downstream tasks they are far from satisfactory. This paper proposes InferCode to overcome the limitation by adapting the self-supervised learning mechanism to build source code model. The key novelty lies in training code representations by predicting automatically identified subtrees from the context of the ASTs. Subtrees in ASTs are treated with InferCode as the labels for training code representations without any human labeling effort or the overhead of expensive graph construction, and the trained representations are no longer tied to any specific downstream tasks or code units. We trained an InferCode model instance using the Tree-based CNN as the encoder of a large set of Java code and applied it to downstream unsupervised tasks such as code clustering, code clone detection, cross-language code search or reused under a transfer learning scheme to continue training the model weights for supervised tasks such as code classification and method name prediction. Compared to previous code learning techniques applied to the same downstream tasks, such as Code2Vec, Code2Seq, ASTNN, higher performance results are achieved using our pre-trained InferCode model with a significant margin for most tasks including those involving different programming languages.
Efficient Framework for Learning Code Representations through Semantic-Preserving Program Transformations
Oct 09, 2020
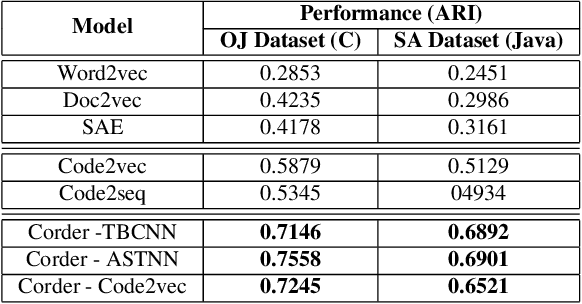
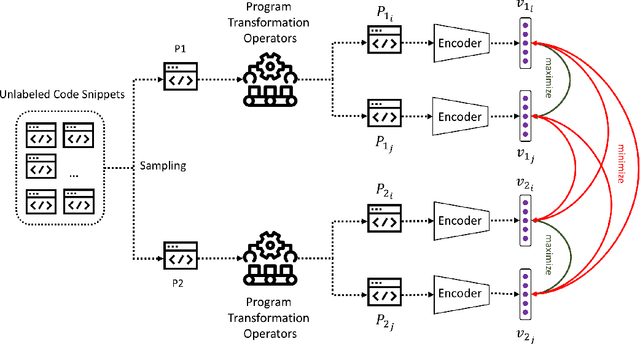
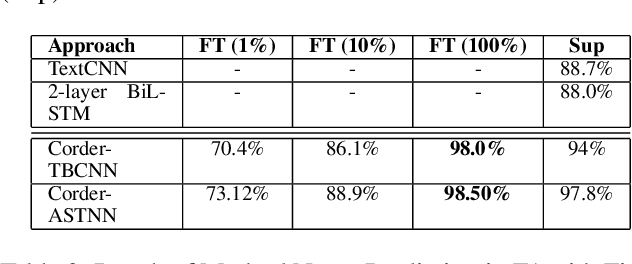
Recent learning techniques for the representation of code depend mostly on human-annotated (labeled) data. In this work, we are proposing Corder, a self-supervised learning system that can learn to represent code without having to label data. The key innovation is that we train the source code model by asking it to recognize similar and dissimilar code snippets through a contrastive learning paradigm. We use a set of semantic-preserving transformation operators to generate snippets that are syntactically diverse but semantically equivalent. The contrastive learning objective, at the same time, maximizes agreement between different views of the same snippets and minimizes agreement between transformed views of different snippets. We train different instances of Corder on 3 neural network encoders, which are Tree-based CNN, ASTNN, and Code2vec over 2.5 million unannotated Java methods mined from GitHub. Our result shows that the Corder pre-training improves code classification and method name prediction with large margins. Furthermore, the code vectors generated by Corder are adapted to code clustering which has been shown to significantly beat the other baselines.