 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Pre-training Across Domains for Few-Shot Surgical Skill Assessment
Sep 11, 2025



Automated surgical skill assessment (SSA) is a central task in surgical computer vision. Developing robust SSA models is challenging due to the scarcity of skill annotations, which are time-consuming to produce and require expert consensus. Few-shot learning (FSL) offers a scalable alternative enabling model development with minimal supervision, though its success critically depends on effective pre-training. While widely studied for several surgical downstream tasks, pre-training has remained largely unexplored in SSA. In this work, we formulate SSA as a few-shot task and investigate how self-supervised pre-training strategies affect downstream few-shot SSA performance. We annotate a publicly available robotic surgery dataset with Objective Structured Assessment of Technical Skill (OSATS) scores, and evaluate various pre-training sources across three few-shot settings. We quantify domain similarity and analyze how domain gap and the inclusion of procedure-specific data into pre-training influence transferability. Our results show that small but domain-relevant datasets can outperform large scale, less aligned ones, achieving accuracies of 60.16%, 66.03%, and 73.65% in the 1-, 2-, and 5-shot settings, respectively. Moreover, incorporating procedure-specific data into pre-training with a domain-relevant external dataset significantly boosts downstream performance, with an average gain of +1.22% in accuracy and +2.28% in F1-score; however, applying the same strategy with less similar but large-scale sources can instead lead to performance degradation. Code and models are available at https://github.com/anastadimi/ssa-fsl.
Boosted Training of Convolutional Neural Networks for Multi-Class Segmentation
Jul 06, 2018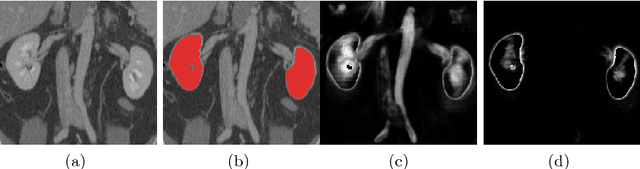
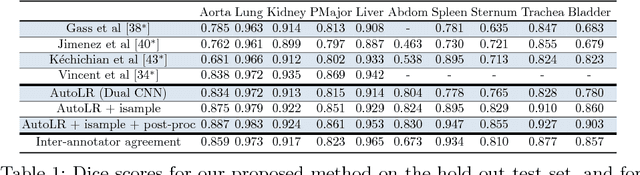
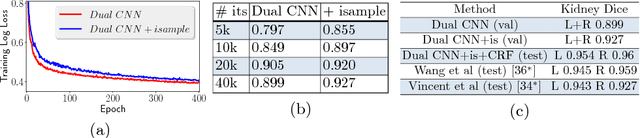
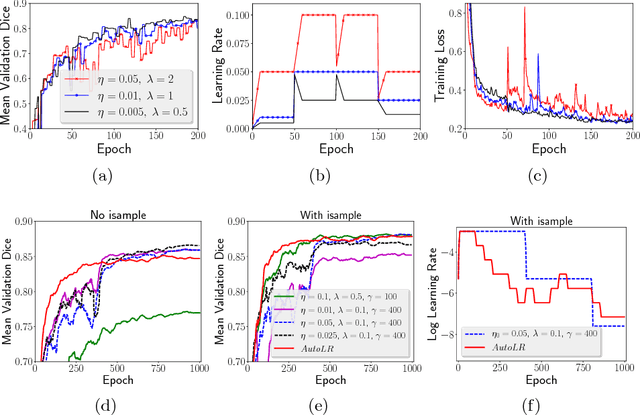
Training deep neural networks on large and sparse datasets is still challenging and can require large amounts of computation and memory. In this work, we address the task of performing semantic segmentation on large volumetric data sets, such as CT scans. Our contribution is threefold: 1) We propose a boosted sampling scheme that uses a-posterior error maps, generated throughout training, to focus sampling on difficult regions, resulting in a more informative loss. This results in a significant training speed up and improves learning performance for image segmentation. 2) We propose a novel algorithm for boosting the SGD learning rate schedule by adaptively increasing and lowering the learning rate, avoiding the need for extensive hyperparameter tuning. 3) We show that our method is able to attain new state-of-the-art results on the VISCERAL Anatomy benchmark.