 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisability prediction in multiple sclerosis using performance outcome measures and demographic data
Apr 08, 2022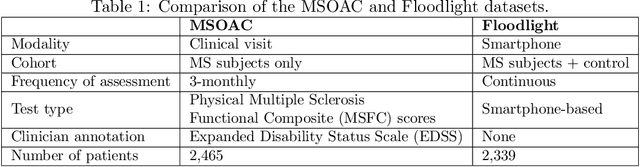
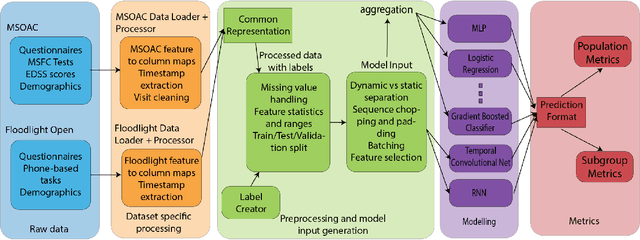
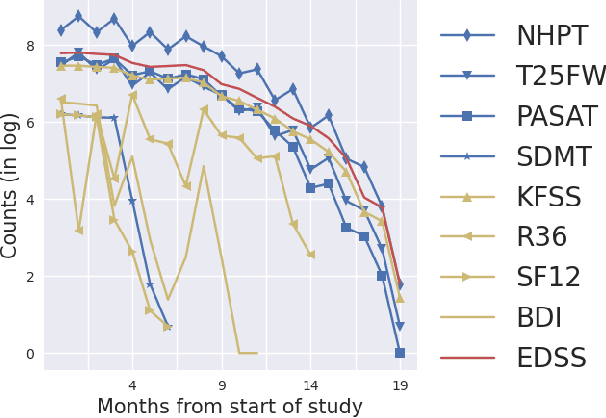
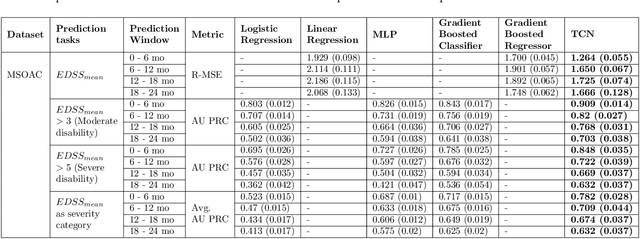
Literature on machine learning for multiple sclerosis has primarily focused on the use of neuroimaging data such as magnetic resonance imaging and clinical laboratory tests for disease identification. However, studies have shown that these modalities are not consistent with disease activity such as symptoms or disease progression. Furthermore, the cost of collecting data from these modalities is high, leading to scarce evaluations. In this work, we used multi-dimensional, affordable, physical and smartphone-based performance outcome measures (POM) in conjunction with demographic data to predict multiple sclerosis disease progression. We performed a rigorous benchmarking exercise on two datasets and present results across 13 clinically actionable prediction endpoints and 6 machine learning models. To the best of our knowledge, our results are the first to show that it is possible to predict disease progression using POMs and demographic data in the context of both clinical trials and smartphone-base studies by using two datasets. Moreover, we investigate our models to understand the impact of different POMs and demographics on model performance through feature ablation studies. We also show that model performance is similar across different demographic subgroups (based on age and sex). To enable this work, we developed an end-to-end reusable pre-processing and machine learning framework which allows quicker experimentation over disparate MS datasets.
Healthsheet: Development of a Transparency Artifact for Health Datasets
Feb 26, 2022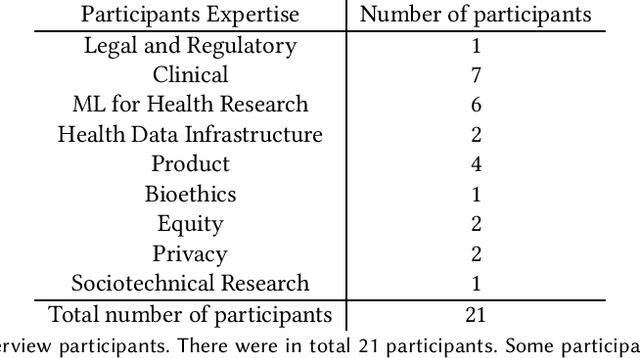
Machine learning (ML) approaches have demonstrated promising results in a wide range of healthcare applications. Data plays a crucial role in developing ML-based healthcare systems that directly affect people's lives. Many of the ethical issues surrounding the use of ML in healthcare stem from structural inequalities underlying the way we collect, use, and handle data. Developing guidelines to improve documentation practices regarding the creation, use, and maintenance of ML healthcare datasets is therefore of critical importance. In this work, we introduce Healthsheet, a contextualized adaptation of the original datasheet questionnaire ~\cite{gebru2018datasheets} for health-specific applications. Through a series of semi-structured interviews, we adapt the datasheets for healthcare data documentation. As part of the Healthsheet development process and to understand the obstacles researchers face in creating datasheets, we worked with three publicly-available healthcare datasets as our case studies, each with different types of structured data: Electronic health Records (EHR), clinical trial study data, and smartphone-based performance outcome measures. Our findings from the interviewee study and case studies show 1) that datasheets should be contextualized for healthcare, 2) that despite incentives to adopt accountability practices such as datasheets, there is a lack of consistency in the broader use of these practices 3) how the ML for health community views datasheets and particularly \textit{Healthsheets} as diagnostic tool to surface the limitations and strength of datasets and 4) the relative importance of different fields in the datasheet to healthcare concerns.
se-Shweshwe Inspired Fashion Generation
Feb 25, 2022
Fashion is one of the ways in which we show ourselves to the world. It is a reflection of our personal decisions and one of the ways in which people distinguish and represent themselves. In this paper, we focus on the fashion design process and expand computer vision for fashion beyond its current focus on western fashion. We discuss the history of Southern African se-Shweshwe fabric fashion, the collection of a se-Shweshwe dataset, and the application of sketch-to-design image generation for affordable fashion-design. The application to fashion raises both technical questions of training with small amounts of data, and also important questions for computer vision beyond fairness, in particular ethical considerations on creating and employing fashion datasets, and how computer vision supports cultural representation and might avoid algorithmic cultural appropriation.
Ethics and Creativity in Computer Vision
Dec 06, 2021This paper offers a retrospective of what we learnt from organizing the workshop *Ethical Considerations in Creative applications of Computer Vision* at CVPR 2021 conference and, prior to that, a series of workshops on *Computer Vision for Fashion, Art and Design* at ECCV 2018, ICCV 2019, and CVPR 2020. We hope this reflection will bring artists and machine learning researchers into conversation around the ethical and social dimensions of creative applications of computer vision.
* Neural Information Processing System 2021 workshop on Machine Learning for Creativity and Design
Thinking Beyond Distributions in Testing Machine Learned Models
Dec 06, 2021Testing practices within the machine learning (ML) community have centered around assessing a learned model's predictive performance measured against a test dataset, often drawn from the same distribution as the training dataset. While recent work on robustness and fairness testing within the ML community has pointed to the importance of testing against distributional shifts, these efforts also focus on estimating the likelihood of the model making an error against a reference dataset/distribution. We argue that this view of testing actively discourages researchers and developers from looking into other sources of robustness failures, for instance corner cases which may have severe undesirable impacts. We draw parallels with decades of work within software engineering testing focused on assessing a software system against various stress conditions, including corner cases, as opposed to solely focusing on average-case behaviour. Finally, we put forth a set of recommendations to broaden the view of machine learning testing to a rigorous practice.
* Neural Information Processing System, NeurIPS 2021 workshop on Distribution Shifts
Deep Cox Mixtures for Survival Regression
Jan 16, 2021

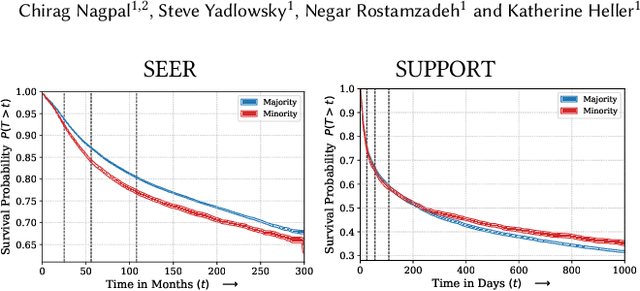

Survival analysis is a challenging variation of regression modeling because of the presence of censoring, where the outcome measurement is only partially known, due to, for example, loss to follow up. Such problems come up frequently in medical applications, making survival analysis a key endeavor in biostatistics and machine learning for healthcare, with Cox regression models being amongst the most commonly employed models. We describe a new approach for survival analysis regression models, based on learning mixtures of Cox regressions to model individual survival distributions. We propose an approximation to the Expectation Maximization algorithm for this model that does hard assignments to mixture groups to make optimization efficient. In each group assignment, we fit the hazard ratios within each group using deep neural networks, and the baseline hazard for each mixture component non-parametrically. We perform experiments on multiple real world datasets, and look at the mortality rates of patients across ethnicity and gender. We emphasize the importance of calibration in healthcare settings and demonstrate that our approach outperforms classical and modern survival analysis baselines, both in terms of discriminative performance and calibration, with large gains in performance on the minority demographics.
A Few-Shot Sequential Approach for Object Counting
Jul 07, 2020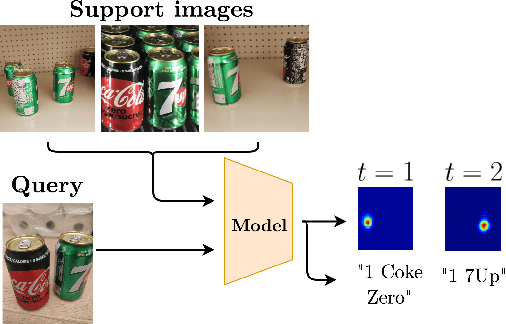
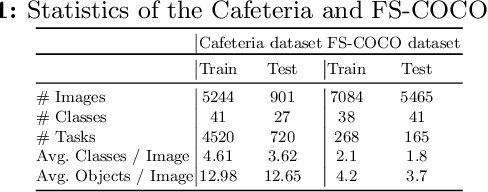
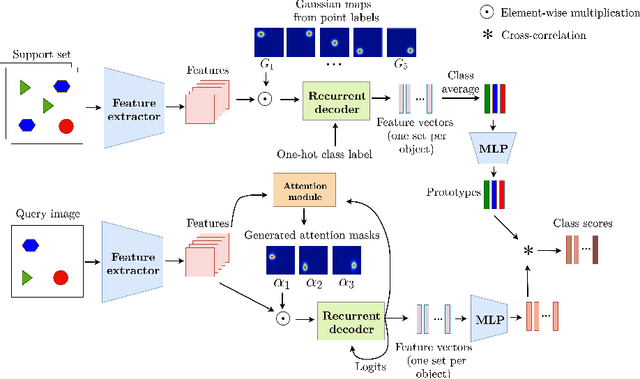
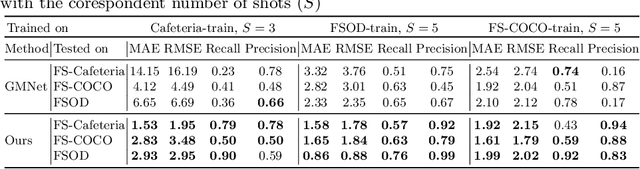
In this work, we address the problem of few-shot multi-class object counting with point-level annotations. The proposed technique leverages a class agnostic attention mechanism that sequentially attends to objects in the image and extracts their relevant features. This process is employed on an adapted prototypical-based few-shot approach that uses the extracted features to classify each one either as one of the classes present in the support set images or as background. The proposed technique is trained on point-level annotations and uses a novel loss function that disentangles class-dependent and class-agnostic aspects of the model to help with the task of few-shot object counting. We present our results on a variety of object-counting/detection datasets, including FSOD and MS COCO. In addition, we introduce a new dataset that is specifically designed for weakly supervised multi-class object counting/detection and contains considerably different classes and distribution of number of classes/instances per image compared to the existing datasets. We demonstrate the robustness of our approach by testing our system on a totally different distribution of classes from what it has been trained on.
Reinforced active learning for image segmentation
Feb 16, 2020
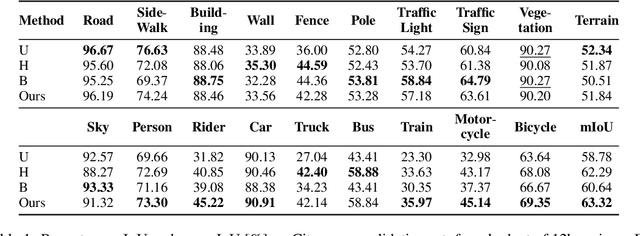
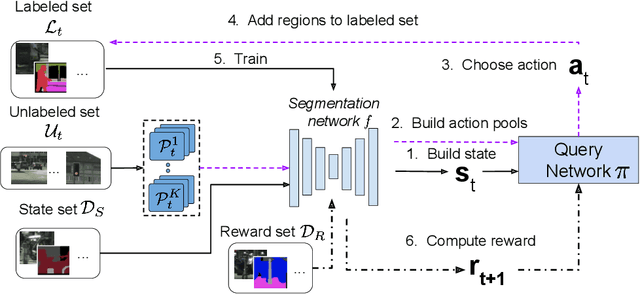
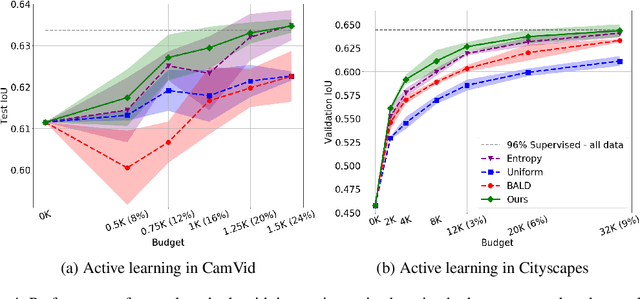
Learning-based approaches for semantic segmentation have two inherent challenges. First, acquiring pixel-wise labels is expensive and time-consuming. Second, realistic segmentation datasets are highly unbalanced: some categories are much more abundant than others, biasing the performance to the most represented ones. In this paper, we are interested in focusing human labelling effort on a small subset of a larger pool of data, minimizing this effort while maximizing performance of a segmentation model on a hold-out set. We present a new active learning strategy for semantic segmentation based on deep reinforcement learning (RL). An agent learns a policy to select a subset of small informative image regions -- opposed to entire images -- to be labeled, from a pool of unlabeled data. The region selection decision is made based on predictions and uncertainties of the segmentation model being trained. Our method proposes a new modification of the deep Q-network (DQN) formulation for active learning, adapting it to the large-scale nature of semantic segmentation problems. We test the proof of concept in CamVid and provide results in the large-scale dataset Cityscapes. On Cityscapes, our deep RL region-based DQN approach requires roughly 30% less additional labeled data than our most competitive baseline to reach the same performance. Moreover, we find that our method asks for more labels of under-represented categories compared to the baselines, improving their performance and helping to mitigate class imbalance.
Neural Multisensory Scene Inference
Nov 08, 2019
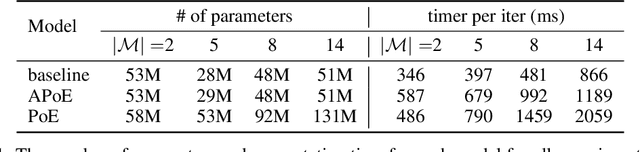
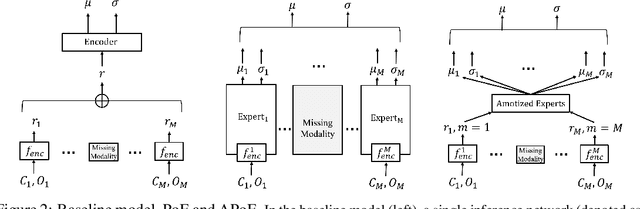
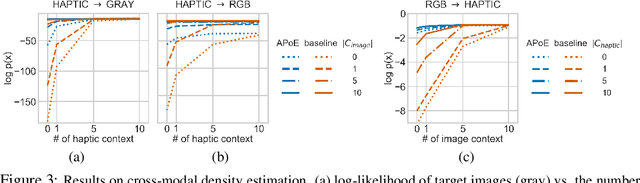
For embodied agents to infer representations of the underlying 3D physical world they inhabit, they should efficiently combine multisensory cues from numerous trials, e.g., by looking at and touching objects. Despite its importance, multisensory 3D scene representation learning has received less attention compared to the unimodal setting. In this paper, we propose the Generative Multisensory Network (GMN) for learning latent representations of 3D scenes which are partially observable through multiple sensory modalities. We also introduce a novel method, called the Amortized Product-of-Experts, to improve the computational efficiency and the robustness to unseen combinations of modalities at test time. Experimental results demonstrate that the proposed model can efficiently infer robust modality-invariant 3D-scene representations from arbitrary combinations of modalities and perform accurate cross-modal generation. To perform this exploration, we also develop the Multisensory Embodied 3D-Scene Environment (MESE).
Instance Segmentation with Point Supervision
Jun 14, 2019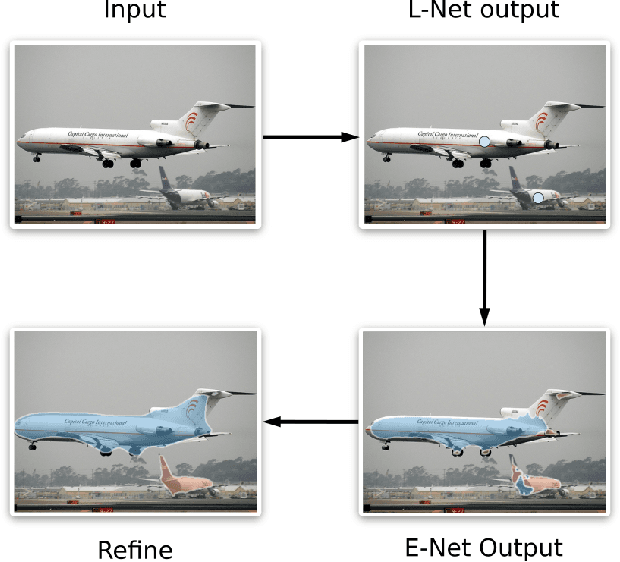
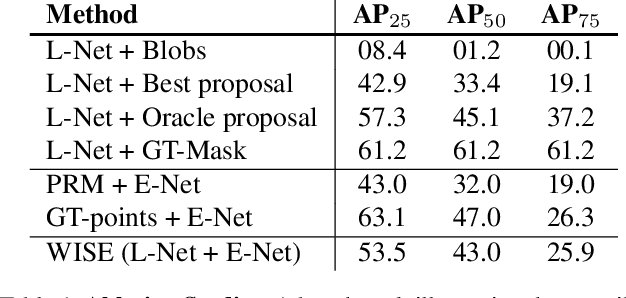

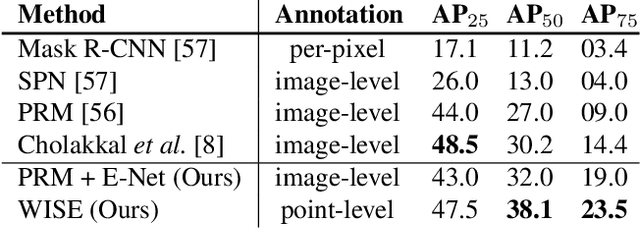
Instance segmentation methods often require costly per-pixel labels. We propose a method that only requires point-level annotations. During training, the model only has access to a single pixel label per object, yet the task is to output full segmentation masks. To address this challenge, we construct a network with two branches: (1) a localization network (L-Net) that predicts the location of each object; and (2) an embedding network (E-Net) that learns an embedding space where pixels of the same object are close. The segmentation masks for the located objects are obtained by grouping pixels with similar embeddings. At training time, while L-Net only requires point-level annotations, E-Net uses pseudo-labels generated by a class-agnostic object proposal method. We evaluate our approach on PASCAL VOC, COCO, KITTI and CityScapes datasets. The experiments show that our method (1) obtains competitive results compared to fully-supervised methods in certain scenarios; (2) outperforms fully- and weakly- supervised methods with a fixed annotation budget; and (3) is a first strong baseline for instance segmentation with point-level supervision.