 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopyright Infringement Risk Reduction via Chain-of-Thought and Task Instruction Prompting
Dec 17, 2025Large scale text-to-image generation models can memorize and reproduce their training dataset. Since the training dataset often contains copyrighted material, reproduction of training dataset poses a copyright infringement risk, which could result in legal liabilities and financial losses for both the AI user and the developer. The current works explores the potential of chain-of-thought and task instruction prompting in reducing copyrighted content generation. To this end, we present a formulation that combines these two techniques with two other copyright mitigation strategies: a) negative prompting, and b) prompt re-writing. We study the generated images in terms their similarity to a copyrighted image and their relevance of the user input. We present numerical experiments on a variety of models and provide insights on the effectiveness of the aforementioned techniques for varying model complexity.
Safer Prompts: Reducing IP Risk in Visual Generative AI
May 06, 2025Visual Generative AI models have demonstrated remarkable capability in generating high-quality images from simple inputs like text prompts. However, because these models are trained on images from diverse sources, they risk memorizing and reproducing specific content, raising concerns about intellectual property (IP) infringement. Recent advances in prompt engineering offer a cost-effective way to enhance generative AI performance. In this paper, we evaluate the effectiveness of prompt engineering techniques in mitigating IP infringement risks in image generation. Our findings show that Chain of Thought Prompting and Task Instruction Prompting significantly reduce the similarity between generated images and the training data of diffusion models, thereby lowering the risk of IP infringement.
Quantifying Correlations of Machine Learning Models
Feb 06, 2025Machine Learning models are being extensively used in safety critical applications where errors from these models could cause harm to the user. Such risks are amplified when multiple machine learning models, which are deployed concurrently, interact and make errors simultaneously. This paper explores three scenarios where error correlations between multiple models arise, resulting in such aggregated risks. Using real-world data, we simulate these scenarios and quantify the correlations in errors of different models. Our findings indicate that aggregated risks are substantial, particularly when models share similar algorithms, training datasets, or foundational models. Overall, we observe that correlations across models are pervasive and likely to intensify with increased reliance on foundational models and widely used public datasets, highlighting the need for effective mitigation strategies to address these challenges.
An In-Depth Examination of Risk Assessment in Multi-Class Classification Algorithms
Dec 05, 2024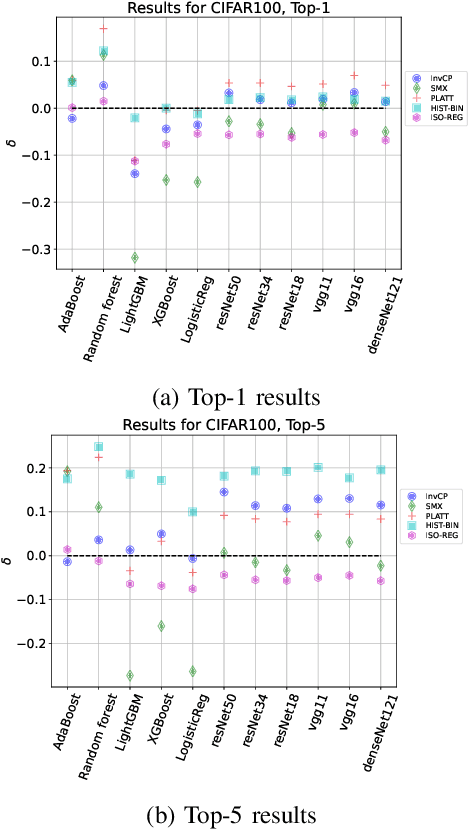
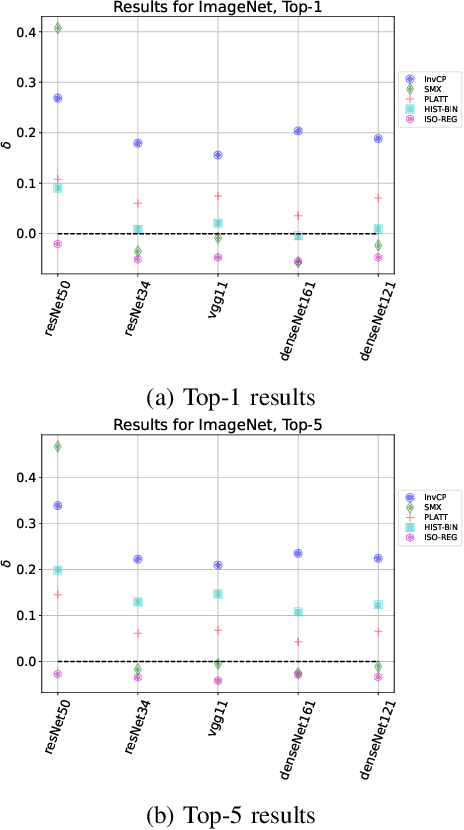
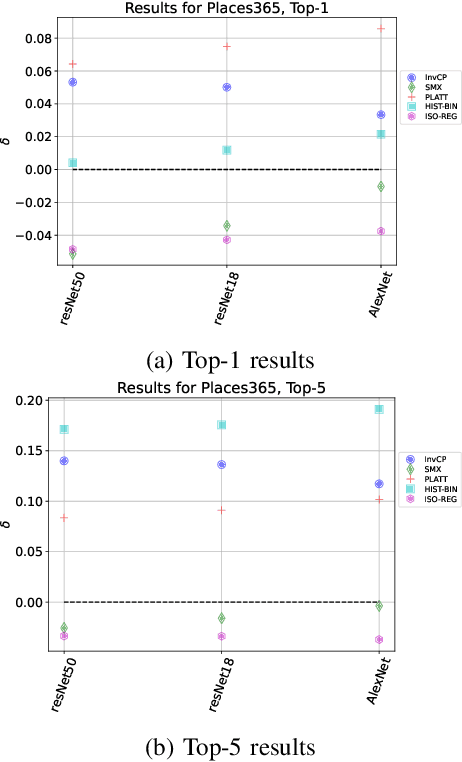
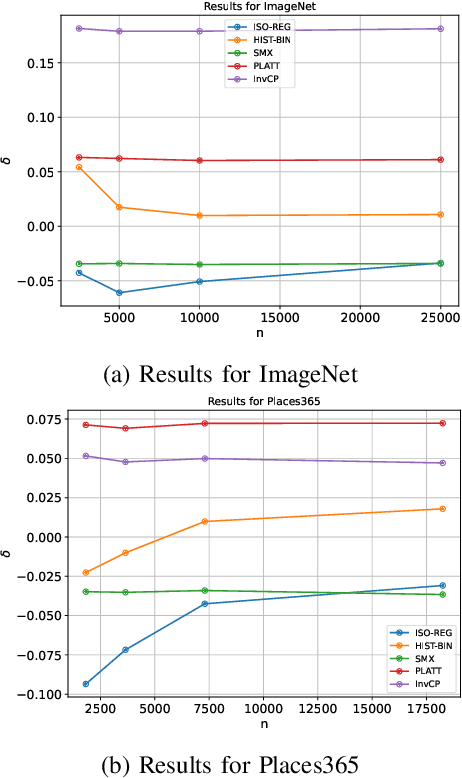
Advanced classification algorithms are being increasingly used in safety-critical applications like health-care, engineering, etc. In such applications, miss-classifications made by ML algorithms can result in substantial financial or health-related losses. To better anticipate and prepare for such losses, the algorithm user seeks an estimate for the probability that the algorithm miss-classifies a sample. We refer to this task as the risk-assessment. For a variety of models and datasets, we numerically analyze the performance of different methods in solving the risk-assessment problem. We consider two solution strategies: a) calibration techniques that calibrate the output probabilities of classification models to provide accurate probability outputs; and b) a novel approach based upon the prediction interval generation technique of conformal prediction. Our conformal prediction based approach is model and data-distribution agnostic, simple to implement, and provides reasonable results for a variety of use-cases. We compare the different methods on a broad variety of models and datasets.
Distribution-free risk assessment of regression-based machine learning algorithms
Oct 05, 2023



Machine learning algorithms have grown in sophistication over the years and are increasingly deployed for real-life applications. However, when using machine learning techniques in practical settings, particularly in high-risk applications such as medicine and engineering, obtaining the failure probability of the predictive model is critical. We refer to this problem as the risk-assessment task. We focus on regression algorithms and the risk-assessment task of computing the probability of the true label lying inside an interval defined around the model's prediction. We solve the risk-assessment problem using the conformal prediction approach, which provides prediction intervals that are guaranteed to contain the true label with a given probability. Using this coverage property, we prove that our approximated failure probability is conservative in the sense that it is not lower than the true failure probability of the ML algorithm. We conduct extensive experiments to empirically study the accuracy of the proposed method for problems with and without covariate shift. Our analysis focuses on different modeling regimes, dataset sizes, and conformal prediction methodologies.