 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePORTER: Language-Grounded Event Representations for Portable Structured EHR Foundation Models
Jun 23, 2026Most electronic health record (EHR) foundation models encode clinical events as discrete event tokens from a fixed vocabulary and therefore cannot directly represent events containing unseen concepts or new combinations of concepts and attributes such as numeric values. This limits transfer across institutions and even across deployment pipelines within the same institution. We introduce PORTER, a language-grounded structured EHR foundation model that decouples event representation from this fixed vocabulary. PORTER represents events through their descriptions using a frozen text encoder, integrates numeric values through a dedicated pathway, and learns clinical dynamics over patient timelines with an autoregressively pretrained temporal backbone. Across 74 clinical prediction tasks at a pediatric hospital, PORTER matched the mean AUROC of a fixed-vocabulary model with the same temporal backbone and pretraining objective. When the same patient timelines were rendered using event descriptions not seen during pretraining, PORTER transferred without retraining or vocabulary mapping, recovering 97.1% of the mean AUROC of a model trained directly on the target vocabulary. When transferred to MIMIC, PORTER outperformed the fixed-vocabulary model, which dropped 69% of events because their tokens were unseen. Mechanistic analyses showed cross-vocabulary transfer tracked preservation of patient-level representation geometry rather than the scale of the text encoder, and the numeric pathway improved sensitivity to magnitude without disrupting clinical concept identity. PORTER also achieved higher AUROC than a task-specific text serialization comparator, at 329-fold lower amortized compute. PORTER is a step toward vocabulary-independent EHR foundation models that reduce the need for vocabulary harmonization while preserving in-domain performance and enabling efficient cross-task reuse.
Understanding challenges to the interpretation of disaggregated evaluations of algorithmic fairness
Jun 04, 2025Disaggregated evaluation across subgroups is critical for assessing the fairness of machine learning models, but its uncritical use can mislead practitioners. We show that equal performance across subgroups is an unreliable measure of fairness when data are representative of the relevant populations but reflective of real-world disparities. Furthermore, when data are not representative due to selection bias, both disaggregated evaluation and alternative approaches based on conditional independence testing may be invalid without explicit assumptions regarding the bias mechanism. We use causal graphical models to predict metric stability across subgroups under different data generating processes. Our framework suggests complementing disaggregated evaluations with explicit causal assumptions and analysis to control for confounding and distribution shift, including conditional independence testing and weighted performance estimation. These findings have broad implications for how practitioners design and interpret model assessments given the ubiquity of disaggregated evaluation.
A Multi-Center Study on the Adaptability of a Shared Foundation Model for Electronic Health Records
Nov 20, 2023Foundation models hold promise for transforming AI in healthcare by providing modular components that are easily adaptable to downstream healthcare tasks, making AI development more scalable and cost-effective. Structured EHR foundation models, trained on coded medical records from millions of patients, demonstrated benefits including increased performance with fewer training labels, and improved robustness to distribution shifts. However, questions remain on the feasibility of sharing these models across different hospitals and their performance for local task adaptation. This multi-center study examined the adaptability of a recently released structured EHR foundation model ($FM_{SM}$), trained on longitudinal medical record data from 2.57M Stanford Medicine patients. Experiments were conducted using EHR data at The Hospital for Sick Children and MIMIC-IV. We assessed both adaptability via continued pretraining on local data, and task adaptability compared to baselines of training models from scratch at each site, including a local foundation model. We evaluated the performance of these models on 8 clinical prediction tasks. In both datasets, adapting the off-the-shelf $FM_{SM}$ matched the performance of GBM models locally trained on all data while providing a 13% improvement in settings with few task-specific training labels. With continued pretraining on local data, label efficiency substantially improved, such that $FM_{SM}$ required fewer than 1% of training examples to match the fully trained GBM's performance. Continued pretraining was also 60 to 90% more sample-efficient than training local foundation models from scratch. Our findings show that adapting shared EHR foundation models across hospitals provides improved prediction performance at less cost, underscoring the utility of base foundation models as modular components to streamline the development of healthcare AI.
Integrating Flowsheet Data in OMOP Common Data Model for Clinical Research
Sep 16, 2021
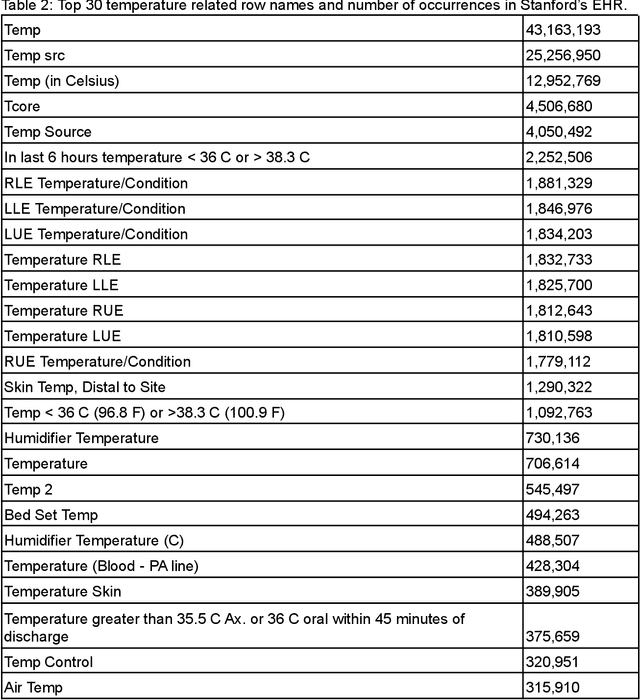
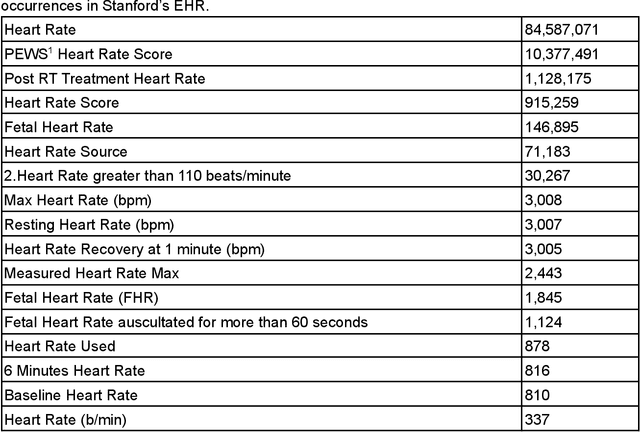

Flowsheet data presents unique challenges and opportunities for integration into standardized Common Data Models (CDMs) such as the Observational Medical Outcomes Partnership (OMOP) CDM from the Observational Health Data Sciences and Informatics (OHDSI) program. These data are a potentially rich source of detailed curated health outcomes data such as pain scores, vital signs, lines drains and airways (LDA) and other measurements that can be invaluable in building a robust model of patient health journey during an inpatient stay. We present two approaches to integration of flowsheet measures into the OMOP CDM. One approach was computationally straightforward but of potentially limited research utility. The second approach was far more computationally and labor intensive and involved mapping to standardized terms in controlled clinical vocabularies such as Logical Observation Identifiers Names and Codes (LOINC), resulting in a research data set of higher utility to population health studies.