 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3O: A Dual-Phase Approach for Reconstructing Dynamic Shape and Skeleton of Articulated Objects from Single Monocular Video
May 21, 2024



Reconstructing dynamic articulated objects from a singular monocular video is challenging, requiring joint estimation of shape, motion, and camera parameters from limited views. Current methods typically demand extensive computational resources and training time, and require additional human annotations such as predefined parametric models, camera poses, and key points, limiting their generalizability. We propose Synergistic Shape and Skeleton Optimization (S3O), a novel two-phase method that forgoes these prerequisites and efficiently learns parametric models including visible shapes and underlying skeletons. Conventional strategies typically learn all parameters simultaneously, leading to interdependencies where a single incorrect prediction can result in significant errors. In contrast, S3O adopts a phased approach: it first focuses on learning coarse parametric models, then progresses to motion learning and detail addition. This method substantially lowers computational complexity and enhances robustness in reconstruction from limited viewpoints, all without requiring additional annotations. To address the current inadequacies in 3D reconstruction from monocular video benchmarks, we collected the PlanetZoo dataset. Our experimental evaluations on standard benchmarks and the PlanetZoo dataset affirm that S3O provides more accurate 3D reconstruction, and plausible skeletons, and reduces the training time by approximately 60% compared to the state-of-the-art, thus advancing the state of the art in dynamic object reconstruction.
Improving Multi-label Recognition using Class Co-Occurrence Probabilities
Apr 24, 2024Multi-label Recognition (MLR) involves the identification of multiple objects within an image. To address the additional complexity of this problem, recent works have leveraged information from vision-language models (VLMs) trained on large text-images datasets for the task. These methods learn an independent classifier for each object (class), overlooking correlations in their occurrences. Such co-occurrences can be captured from the training data as conditional probabilities between a pair of classes. We propose a framework to extend the independent classifiers by incorporating the co-occurrence information for object pairs to improve the performance of independent classifiers. We use a Graph Convolutional Network (GCN) to enforce the conditional probabilities between classes, by refining the initial estimates derived from image and text sources obtained using VLMs. We validate our method on four MLR datasets, where our approach outperforms all state-of-the-art methods.
Piecewise-Linear Manifolds for Deep Metric Learning
Mar 22, 2024Unsupervised deep metric learning (UDML) focuses on learning a semantic representation space using only unlabeled data. This challenging problem requires accurately estimating the similarity between data points, which is used to supervise a deep network. For this purpose, we propose to model the high-dimensional data manifold using a piecewise-linear approximation, with each low-dimensional linear piece approximating the data manifold in a small neighborhood of a point. These neighborhoods are used to estimate similarity between data points. We empirically show that this similarity estimate correlates better with the ground truth than the similarity estimates of current state-of-the-art techniques. We also show that proxies, commonly used in supervised metric learning, can be used to model the piecewise-linear manifold in an unsupervised setting, helping improve performance. Our method outperforms existing unsupervised metric learning approaches on standard zero-shot image retrieval benchmarks.
Learning Implicit Representation for Reconstructing Articulated Objects
Jan 16, 20243D Reconstruction of moving articulated objects without additional information about object structure is a challenging problem. Current methods overcome such challenges by employing category-specific skeletal models. Consequently, they do not generalize well to articulated objects in the wild. We treat an articulated object as an unknown, semi-rigid skeletal structure surrounded by nonrigid material (e.g., skin). Our method simultaneously estimates the visible (explicit) representation (3D shapes, colors, camera parameters) and the implicit skeletal representation, from motion cues in the object video without 3D supervision. Our implicit representation consists of four parts. (1) Skeleton, which specifies how semi-rigid parts are connected. (2) \textcolor{black}{Skinning Weights}, which associates each surface vertex with semi-rigid parts with probability. (3) Rigidity Coefficients, specifying the articulation of the local surface. (4) Time-Varying Transformations, which specify the skeletal motion and surface deformation parameters. We introduce an algorithm that uses physical constraints as regularization terms and iteratively estimates both implicit and explicit representations. Our method is category-agnostic, thus eliminating the need for category-specific skeletons, we show that our method outperforms state-of-the-art across standard video datasets.
CSL: Class-Agnostic Structure-Constrained Learning for Segmentation Including the Unseen
Dec 09, 2023Addressing Out-Of-Distribution (OOD) Segmentation and Zero-Shot Semantic Segmentation (ZS3) is challenging, necessitating segmenting unseen classes. Existing strategies adapt the class-agnostic Mask2Former (CA-M2F) tailored to specific tasks. However, these methods cater to singular tasks, demand training from scratch, and we demonstrate certain deficiencies in CA-M2F, which affect performance. We propose the Class-Agnostic Structure-Constrained Learning (CSL), a plug-in framework that can integrate with existing methods, thereby embedding structural constraints and achieving performance gain, including the unseen, specifically OOD, ZS3, and domain adaptation (DA) tasks. There are two schemes for CSL to integrate with existing methods (1) by distilling knowledge from a base teacher network, enforcing constraints across training and inference phrases, or (2) by leveraging established models to obtain per-pixel distributions without retraining, appending constraints during the inference phase. We propose soft assignment and mask split methodologies that enhance OOD object segmentation. Empirical evaluations demonstrate CSL's prowess in boosting the performance of existing algorithms spanning OOD segmentation, ZS3, and DA segmentation, consistently transcending the state-of-art across all three tasks.
Open-NeRF: Towards Open Vocabulary NeRF Decomposition
Oct 25, 2023In this paper, we address the challenge of decomposing Neural Radiance Fields (NeRF) into objects from an open vocabulary, a critical task for object manipulation in 3D reconstruction and view synthesis. Current techniques for NeRF decomposition involve a trade-off between the flexibility of processing open-vocabulary queries and the accuracy of 3D segmentation. We present, Open-vocabulary Embedded Neural Radiance Fields (Open-NeRF), that leverage large-scale, off-the-shelf, segmentation models like the Segment Anything Model (SAM) and introduce an integrate-and-distill paradigm with hierarchical embeddings to achieve both the flexibility of open-vocabulary querying and 3D segmentation accuracy. Open-NeRF first utilizes large-scale foundation models to generate hierarchical 2D mask proposals from varying viewpoints. These proposals are then aligned via tracking approaches and integrated within the 3D space and subsequently distilled into the 3D field. This process ensures consistent recognition and granularity of objects from different viewpoints, even in challenging scenarios involving occlusion and indistinct features. Our experimental results show that the proposed Open-NeRF outperforms state-of-the-art methods such as LERF \cite{lerf} and FFD \cite{ffd} in open-vocabulary scenarios. Open-NeRF offers a promising solution to NeRF decomposition, guided by open-vocabulary queries, enabling novel applications in robotics and vision-language interaction in open-world 3D scenes.
Long-Distance Gesture Recognition using Dynamic Neural Networks
Aug 09, 2023



Gestures form an important medium of communication between humans and machines. An overwhelming majority of existing gesture recognition methods are tailored to a scenario where humans and machines are located very close to each other. This short-distance assumption does not hold true for several types of interactions, for example gesture-based interactions with a floor cleaning robot or with a drone. Methods made for short-distance recognition are unable to perform well on long-distance recognition due to gestures occupying only a small portion of the input data. Their performance is especially worse in resource constrained settings where they are not able to effectively focus their limited compute on the gesturing subject. We propose a novel, accurate and efficient method for the recognition of gestures from longer distances. It uses a dynamic neural network to select features from gesture-containing spatial regions of the input sensor data for further processing. This helps the network focus on features important for gesture recognition while discarding background features early on, thus making it more compute efficient compared to other techniques. We demonstrate the performance of our method on the LD-ConGR long-distance dataset where it outperforms previous state-of-the-art methods on recognition accuracy and compute efficiency.
Learning Audio-Visual Dynamics Using Scene Graphs for Audio Source Separation
Oct 29, 2022There exists an unequivocal distinction between the sound produced by a static source and that produced by a moving one, especially when the source moves towards or away from the microphone. In this paper, we propose to use this connection between audio and visual dynamics for solving two challenging tasks simultaneously, namely: (i) separating audio sources from a mixture using visual cues, and (ii) predicting the 3D visual motion of a sounding source using its separated audio. Towards this end, we present Audio Separator and Motion Predictor (ASMP) -- a deep learning framework that leverages the 3D structure of the scene and the motion of sound sources for better audio source separation. At the heart of ASMP is a 2.5D scene graph capturing various objects in the video and their pseudo-3D spatial proximities. This graph is constructed by registering together 2.5D monocular depth predictions from the 2D video frames and associating the 2.5D scene regions with the outputs of an object detector applied on those frames. The ASMP task is then mathematically modeled as the joint problem of: (i) recursively segmenting the 2.5D scene graph into several sub-graphs, each associated with a constituent sound in the input audio mixture (which is then separated) and (ii) predicting the 3D motions of the corresponding sound sources from the separated audio. To empirically evaluate ASMP, we present experiments on two challenging audio-visual datasets, viz. Audio Separation in the Wild (ASIW) and Audio Visual Event (AVE). Our results demonstrate that ASMP achieves a clear improvement in source separation quality, outperforming prior works on both datasets, while also estimating the direction of motion of the sound sources better than other methods.
Tracking Grow-Finish Pigs Across Large Pens Using Multiple Cameras
Nov 22, 2021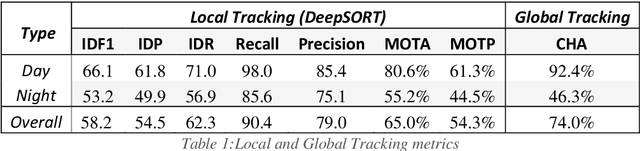
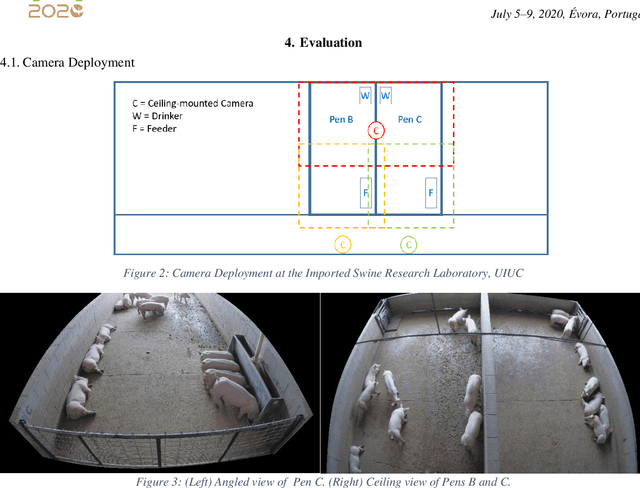


Increasing demand for meat products combined with farm labor shortages has resulted in a need to develop new real-time solutions to monitor animals effectively. Significant progress has been made in continuously locating individual pigs using tracking-by-detection methods. However, these methods fail for oblong pens because a single fixed camera does not cover the entire floor at adequate resolution. We address this problem by using multiple cameras, placed such that the visual fields of adjacent cameras overlap, and together they span the entire floor. Avoiding breaks in tracking requires inter-camera handover when a pig crosses from one camera's view into that of an adjacent camera. We identify the adjacent camera and the shared pig location on the floor at the handover time using inter-view homography. Our experiments involve two grow-finish pens, housing 16-17 pigs each, and three RGB cameras. Our algorithm first detects pigs using a deep learning-based object detection model (YOLO) and creates their local tracking IDs using a multi-object tracking algorithm (DeepSORT). We then use inter-camera shared locations to match multiple views and generate a global ID for each pig that holds throughout tracking. To evaluate our approach, we provide five two-minutes long video sequences with fully annotated global identities. We track pigs in a single camera view with a Multi-Object Tracking Accuracy and Precision of 65.0% and 54.3% respectively and achieve a Camera Handover Accuracy of 74.0%. We open-source our code and annotated dataset at https://github.com/AIFARMS/multi-camera-pig-tracking
A Hierarchical Variational Neural Uncertainty Model for Stochastic Video Prediction
Oct 06, 2021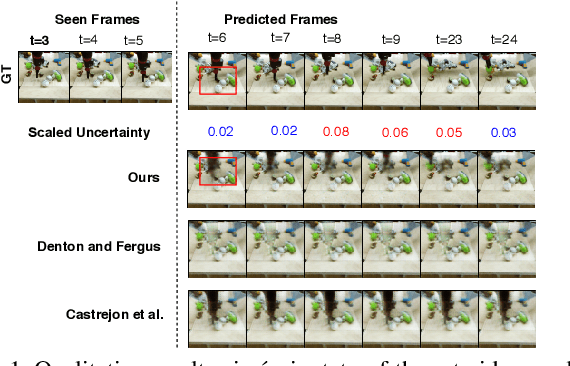
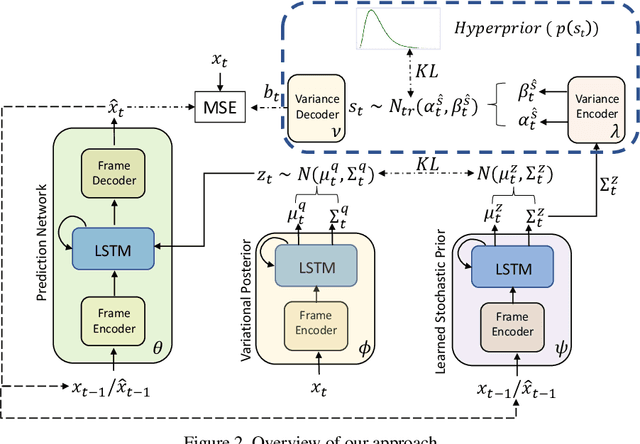
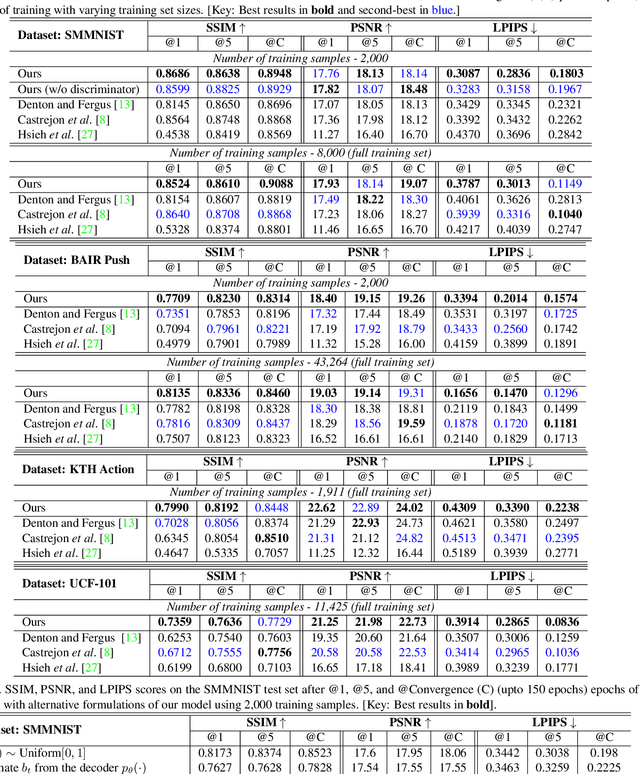
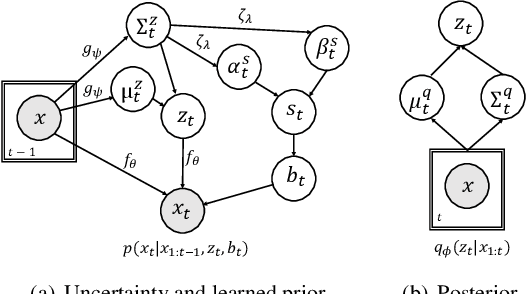
Predicting the future frames of a video is a challenging task, in part due to the underlying stochastic real-world phenomena. Prior approaches to solve this task typically estimate a latent prior characterizing this stochasticity, however do not account for the predictive uncertainty of the (deep learning) model. Such approaches often derive the training signal from the mean-squared error (MSE) between the generated frame and the ground truth, which can lead to sub-optimal training, especially when the predictive uncertainty is high. Towards this end, we introduce Neural Uncertainty Quantifier (NUQ) - a stochastic quantification of the model's predictive uncertainty, and use it to weigh the MSE loss. We propose a hierarchical, variational framework to derive NUQ in a principled manner using a deep, Bayesian graphical model. Our experiments on four benchmark stochastic video prediction datasets show that our proposed framework trains more effectively compared to the state-of-the-art models (especially when the training sets are small), while demonstrating better video generation quality and diversity against several evaluation metrics.