 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Few-shot Object Segmentation using Co-Attention with Visual and Semantic Inputs
Paper and Code
Feb 07, 2020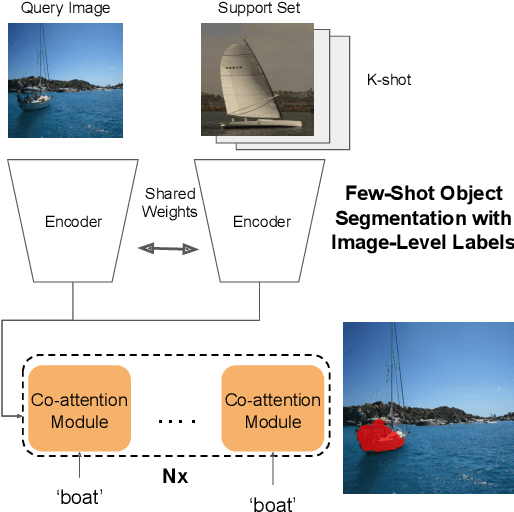
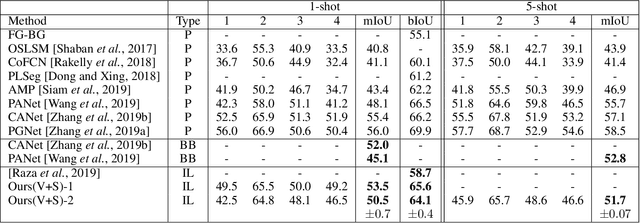
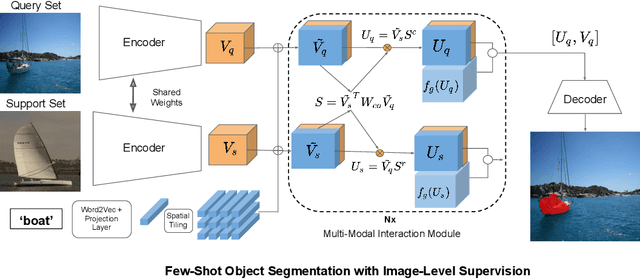
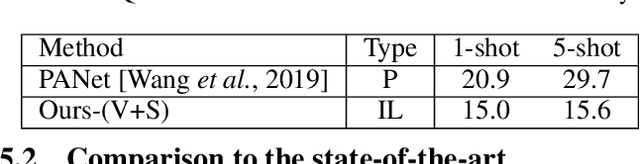
Significant progress has been made recently in developing few-shot object segmentation methods. Learning is shown to be successful in few segmentation settings, including pixel-level, scribbles and bounding boxes. This paper takes another approach, i.e., only requiring image-level classification data for few-shot object segmentation. We propose a novel multi-modal interaction module for few-shot object segmentation that utilizes a co-attention mechanism using both visual and word embedding. Our model using image-level labels achieves 4.8% improvement over previously proposed image-level few-shot object segmentation. It also outperforms state-of-the-art methods that use weak bounding box supervision on PASCAL-$5^i$. Our results show that few-shot segmentation benefits from utilizing word embeddings, and that we are able to perform few-shot segmentation using stacked joint visual semantic processing with weak image-level labels. We further propose a novel setup, Temporal Object Segmentation for Few-shot Learning (TOSFL) for videos. TOSFL requires only image-level labels for the first frame in order to segment objects in the following frames. TOSFL provides a novel benchmark for video segmentation, which can be used on a variety of public video data such as Youtube-VOS, as demonstrated in our experiment.