 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStock Price Prediction using Sentiment Analysis and Deep Learning for Indian Markets
Apr 07, 2022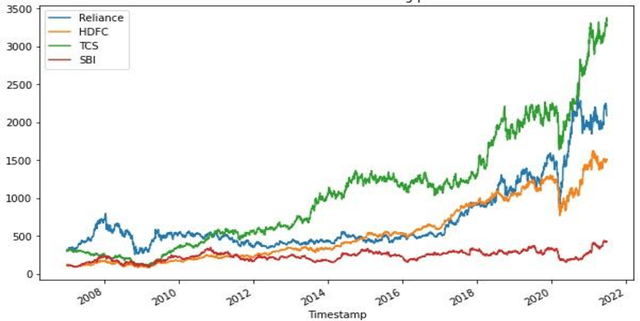
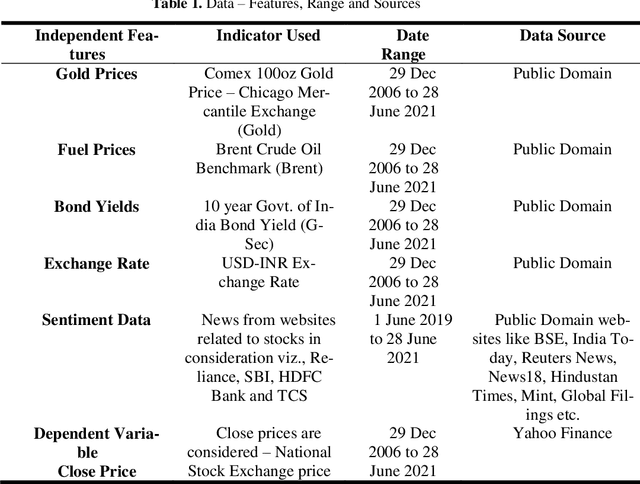
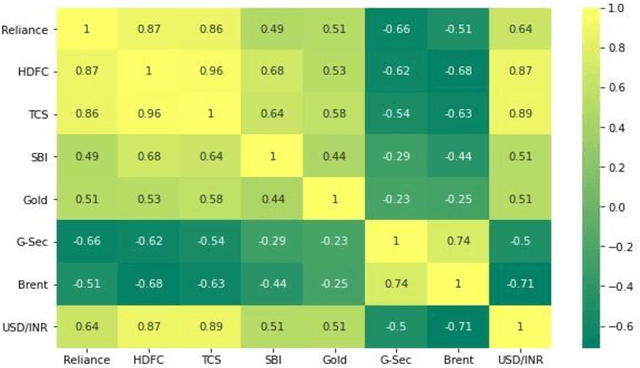
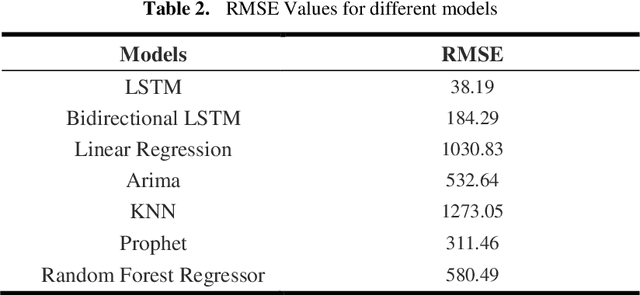
Stock market prediction has been an active area of research for a considerable period. Arrival of computing, followed by Machine Learning has upgraded the speed of research as well as opened new avenues. As part of this research study, we aimed to predict the future stock movement of shares using the historical prices aided with availability of sentiment data. Two models were used as part of the exercise, LSTM was the first model with historical prices as the independent variable. Sentiment Analysis captured using Intensity Analyzer was used as the major parameter for Random Forest Model used for the second part, some macro parameters like Gold, Oil prices, USD exchange rate and Indian Govt. Securities yields were also added to the model for improved accuracy of the model. As the end product, prices of 4 stocks viz. Reliance, HDFC Bank, TCS and SBI were predicted using the aforementioned two models. The results were evaluated using RMSE metric.
Detection of Distracted Driver using Convolution Neural Network
Apr 07, 2022
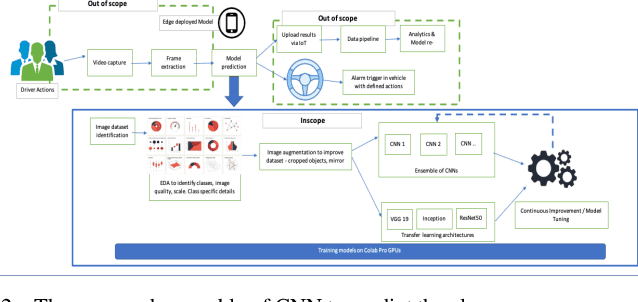
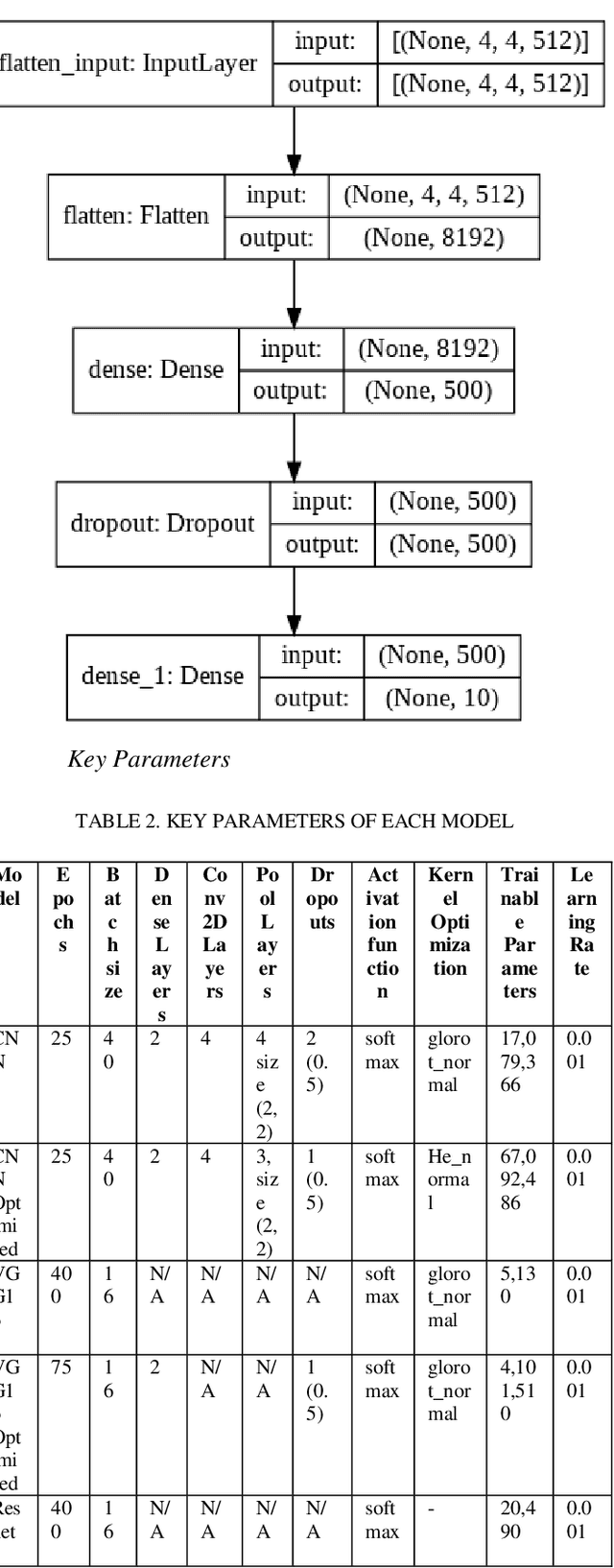

With over 50 million car sales annually and over 1.3 million deaths every year due to motor accidents we have chosen this space. India accounts for 11 per cent of global death in road accidents. Drivers are held responsible for 78% of accidents. Road safety problems in developing countries is a major concern and human behavior is ascribed as one of the main causes and accelerators of road safety problems. Driver distraction has been identified as the main reason for accidents. Distractions can be caused due to reasons such as mobile usage, drinking, operating instruments, facial makeup, social interaction. For the scope of this project, we will focus on building a highly efficient ML model to classify different driver distractions at runtime using computer vision. We would also analyze the overall speed and scalability of the model in order to be able to set it up on an edge device. We use CNN, VGG-16, RestNet50 and ensemble of CNN to predict the classes.
LSTM-RASA Based Agri Farm Assistant for Farmers
Apr 07, 2022

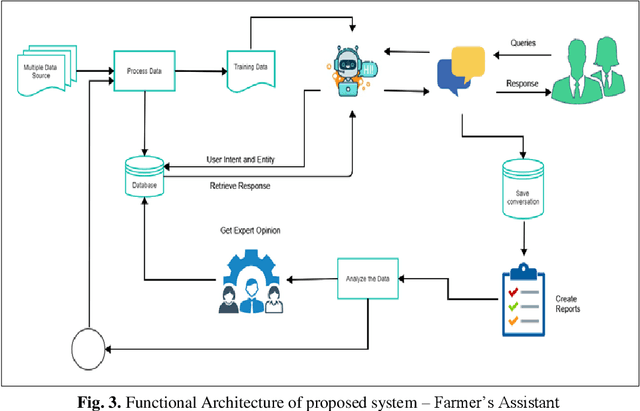
The application of Deep Learning and Natural Language based ChatBots are growing rapidly in recent years. They are used in many fields like customer support, reservation system and as personal assistant. The Enterprises are using such ChatBots to serve their customers in a better and efficient manner. Even after such technological advancement, the expert advice does not reach the farmers on timely manner. The farmers are still largely dependent on their peers knowledge in solving the problems they face in their field. These technologies have not been effectively used to give the required information to farmers on timely manner. This project aims to implement a closed domain ChatBot for the field of Agriculture Farmers Assistant. Farmers can have conversation with the Chatbot and get the expert advice in their field. Farmers Assistant is based on RASA Open Source Framework. The Chatbot identifies the intent and entity from user utterances and retrieve the remedy from the database and share it with the user. We tested the Bot with existing data and it showed promising results.
Implementing a Real-Time, YOLOv5 based Social Distancing Measuring System for Covid-19
Apr 07, 2022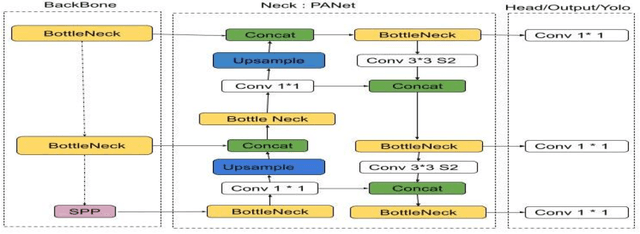

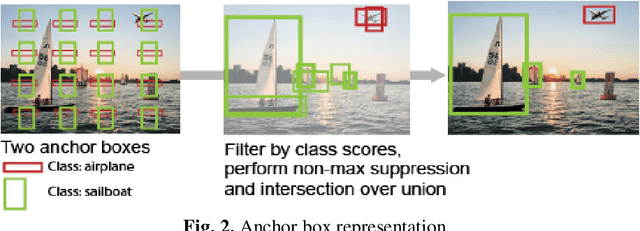
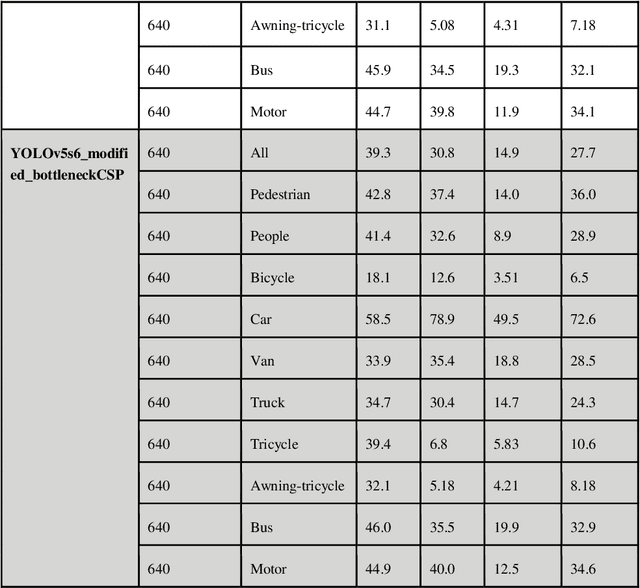
The purpose of this work is, to provide a YOLOv5 deep learning-based social distance monitoring framework using an overhead view perspective. In addition, we have developed a custom defined model YOLOv5 modified CSP (Cross Stage Partial Network) and assessed the performance on COCO and Visdrone dataset with and without transfer learning. Our findings show that the developed model successfully identifies the individual who violates the social distances. The accuracy of 81.7% for the modified bottleneck CSP without transfer learning is observed on COCO dataset after training the model for 300 epochs whereas for the same epochs, the default YOLOv5 model is attaining 80.1% accuracy with transfer learning. This shows an improvement in accuracy by our modified bottleneck CSP model. For the Visdrone dataset, we are able to achieve an accuracy of upto 56.5% for certain classes and especially an accuracy of 40% for people and pedestrians with transfer learning using the default YOLOv5s model for 30 epochs. While the modified bottleneck CSP is able to perform slightly better than the default model with an accuracy score of upto 58.1% for certain classes and an accuracy of ~40.4% for people and pedestrians.
Contextual Attention Mechanism, SRGAN Based Inpainting System for Eliminating Interruptions from Images
Apr 06, 2022
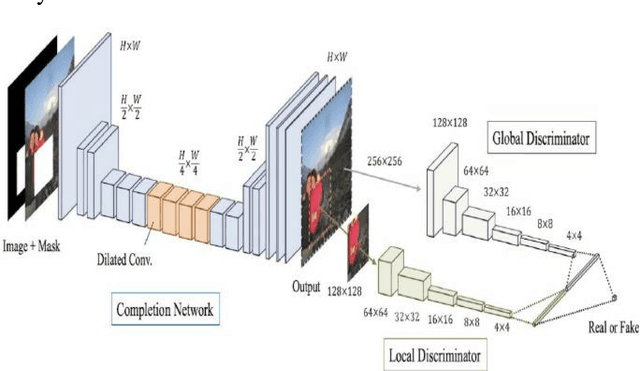
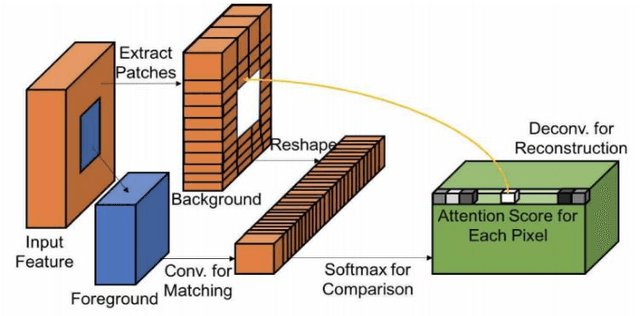
The new alternative is to use deep learning to inpaint any image by utilizing image classification and computer vision techniques. In general, image inpainting is a task of recreating or reconstructing any broken image which could be a photograph or oil/acrylic painting. With the advancement in the field of Artificial Intelligence, this topic has become popular among AI enthusiasts. With our approach, we propose an initial end-to-end pipeline for inpainting images using a complete Machine Learning approach instead of a conventional application-based approach. We first use the YOLO model to automatically identify and localize the object we wish to remove from the image. Using the result obtained from the model we can generate a mask for the same. After this, we provide the masked image and original image to the GAN model which uses the Contextual Attention method to fill in the region. It consists of two generator networks and two discriminator networks and is also called a coarse-to-fine network structure. The two generators use fully convolutional networks while the global discriminator gets hold of the entire image as input while the local discriminator gets the grip of the filled region as input. The contextual Attention mechanism is proposed to effectively borrow the neighbor information from distant spatial locations for reconstructing the missing pixels. The third part of our implementation uses SRGAN to resolve the inpainted image back to its original size. Our work is inspired by the paper Free-Form Image Inpainting with Gated Convolution and Generative Image Inpainting with Contextual Attention.
Banana Sub-Family Classification and Quality Prediction using Computer Vision
Apr 06, 2022
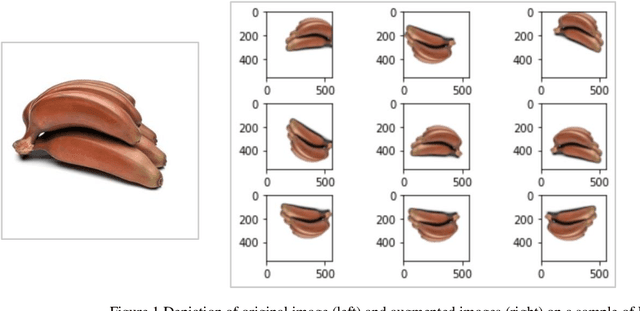

India is the second largest producer of fruits and vegetables in the world, and one of the largest consumers of fruits like Banana, Papaya and Mangoes through retail and ecommerce giants like BigBasket, Grofers and Amazon Fresh. However, adoption of technology in supply chain and retail stores is still low and there is a great potential to adopt computer-vision based technology for identification and classification of fruits. We have chosen banana fruit to build a computer vision based model to carry out the following three use-cases (a) Identify Banana from a given image (b) Determine sub-family or variety of Banana (c) Determine the quality of Banana. Successful execution of these use-cases using computer-vision model would greatly help with overall inventory management automation, quality control, quick and efficient weighing and billing which all are manual labor intensive currently. In this work, we suggest a machine learning pipeline that combines the ideas of CNNs, transfer learning, and data augmentation towards improving Banana fruit sub family and quality image classification. We have built a basic CNN and then went on to tune a MobileNet Banana classification model using a combination of self-curated and publicly-available dataset of 3064 images. The results show an overall 93.4% and 100% accuracy for sub-family/variety and for quality test classifications respectively.
Detecting key Soccer match events to create highlights using Computer Vision
Apr 06, 2022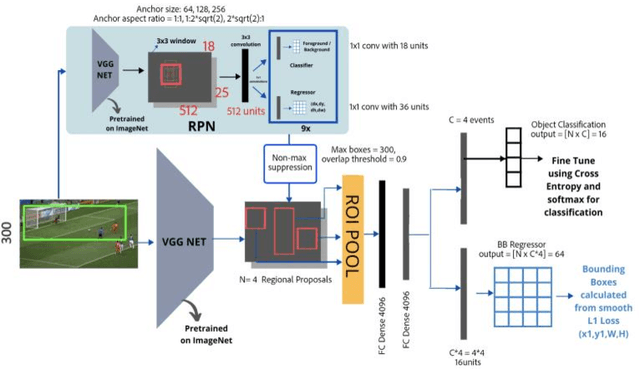

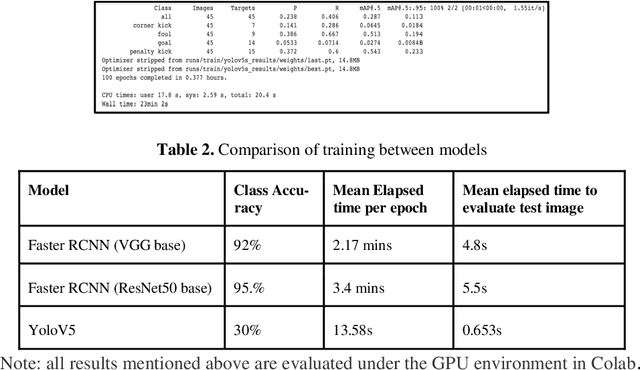

The research and data science community has been fascinated with the development of automatic systems for the detection of key events in a video. Special attention in this field is given to sports video analytics which could help in identifying key events during a match and help in preparing a strategy for the games going forward. For this paper, we have chosen Football (soccer) as a sport where we would want to create highlights for a given match video, through a computer vision model that aims to identify important events in a Soccer match to create highlights of the match. We built the models based on Faster RCNN and YoloV5 architectures and noticed that for the amount of data we used for training Faster RCNN did better than YoloV5 in detecting the events in the match though it was much slower. Within Faster RCNN using ResNet50 as a base model gave a better class accuracy of 95.5% as compared to 92% with VGG16 as base model completely outperforming YoloV5 for our training dataset. We tested with an original video of size 23 minutes and our model could reduce it to 4:50 minutes of highlights capturing almost all important events in the match.
Bi-Sampling Approach to Classify Music Mood leveraging Raga-Rasa Association in Indian Classical Music
Mar 13, 2022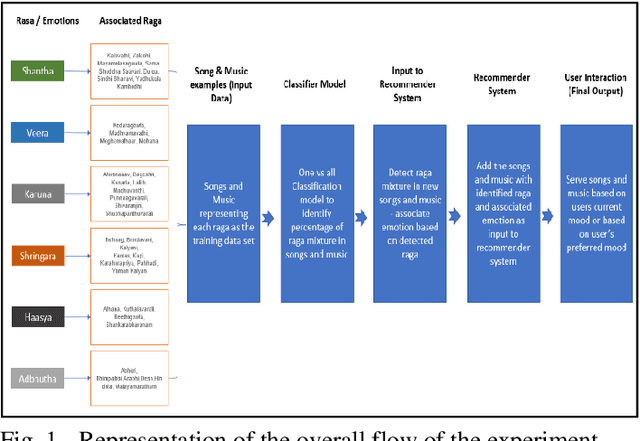

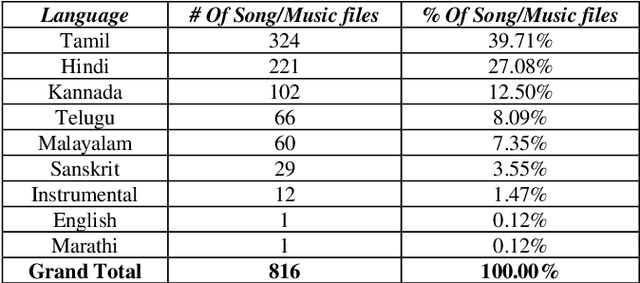
The impact of Music on the mood or emotion of the listener is a well-researched area in human psychology and behavioral science. In Indian classical music, ragas are the melodic structure that defines the various styles and forms of the music. Each raga has been found to evoke a specific emotion in the listener. With the advent of advanced capabilities of audio signal processing and the application of machine learning, the demand for intelligent music classifiers and recommenders has received increased attention, especially in the 'Music as a service' cloud applications. This paper explores a novel framework to leverage the raga-rasa association in Indian classical Music to build an intelligent classifier and its application in music recommendation system based on user's current mood and the mood they aspire to be in.
Building a Question and Answer System for News Domain
May 12, 2021
This project attempts to build a Question- Answering system in the News Domain, where Passages will be News articles, and anyone can ask a Question against it. We have built a span-based model using an Attention mechanism, where the model predicts the answer to a question as to the position of the start and end tokens in a paragraph. For training our model, we have used the Stanford Question and Answer (SQuAD 2.0) dataset[1]. To do well on SQuAD 2.0, systems must not only answer questions when possible but also determine when no answer is supported by the paragraph and abstain from answering. Our model architecture comprises three layers- Embedding Layer, RNN Layer, and the Attention Layer. For the Embedding layer, we used GloVe and the Universal Sentence Encoder. For the RNN Layer, we built variations of the RNN Layer including bi-LSTM and Stacked LSTM and we built an Attention Layer using a Context to Question Attention and also improvised on the innovative Bidirectional Attention Layer. Our best performing model which uses GloVe Embedding combined with Bi-LSTM and Context to Question Attention achieved an F1 Score and EM of 33.095 and 33.094 respectively. We also leveraged transfer learning and built a Transformer based model using BERT. The BERT-based model achieved an F1 Score and EM of 57.513 and 49.769 respectively. We concluded that the BERT model is superior in all aspects of answering various types of questions.