 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMateICL: Mitigating Attention Dispersion in Large-Scale In-Context Learning
May 02, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in In-Context Learning (ICL). However, the fixed position length constraints in pre-trained models limit the number of demonstration examples. Recent efforts to extend context suffer from attention dispersion as the number of demonstrations increases. In this paper, we introduce Mitigating Attention Dispersion in large-scale ICL (MateICL) that enables LLMs to maintain effective self-attention as the context size grows. We first split the context into multiple windows, each filled to the model's context capacity, which are processed separately. Then, we introduce an additional layer to recalibrate the attention weights, prioritizing the query tokens as the number of demonstrations increases. Our empirical results show that MateICL can effectively leverage larger contexts to improve ICL performance. Compared to retrieval-based baselines, MateICL consistently achieves better performance without requiring an externally trained retrieval model. Despite recent advances in inference strategies (e.g., 32k token contexts), our results demonstrate that MateICL remains beneficial in computationally resource-constrained settings. The code is publicly available at https://github.com/amurtadha/MateICL.
AlcLaM: Arabic Dialectal Language Model
Jul 18, 2024

Pre-trained Language Models (PLMs) are integral to many modern natural language processing (NLP) systems. Although multilingual models cover a wide range of languages, they often grapple with challenges like high inference costs and a lack of diverse non-English training data. Arabic-specific PLMs are trained predominantly on modern standard Arabic, which compromises their performance on regional dialects. To tackle this, we construct an Arabic dialectal corpus comprising 3.4M sentences gathered from social media platforms. We utilize this corpus to expand the vocabulary and retrain a BERT-based model from scratch. Named AlcLaM, our model was trained using only 13 GB of text, which represents a fraction of the data used by existing models such as CAMeL, MARBERT, and ArBERT, compared to 7.8%, 10.2%, and 21.3%, respectively. Remarkably, AlcLaM demonstrates superior performance on a variety of Arabic NLP tasks despite the limited training data. AlcLaM is available at GitHub https://github.com/amurtadha/Alclam and HuggingFace https://huggingface.co/rahbi.
Supervised Gradual Machine Learning for Aspect Category Detection
Apr 08, 2024Aspect Category Detection (ACD) aims to identify implicit and explicit aspects in a given review sentence. The state-of-the-art approaches for ACD use Deep Neural Networks (DNNs) to address the problem as a multi-label classification task. However, learning category-specific representations heavily rely on the amount of labeled examples, which may not readily available in real-world scenarios. In this paper, we propose a novel approach to tackle the ACD task by combining DNNs with Gradual Machine Learning (GML) in a supervised setting. we aim to leverage the strength of DNN in semantic relation modeling, which can facilitate effective knowledge transfer between labeled and unlabeled instances during the gradual inference of GML. To achieve this, we first analyze the learned latent space of the DNN to model the relations, i.e., similar or opposite, between instances. We then represent these relations as binary features in a factor graph to efficiently convey knowledge. Finally, we conduct a comparative study of our proposed solution on real benchmark datasets and demonstrate that the GML approach, in collaboration with DNNs for feature extraction, consistently outperforms pure DNN solutions.
Naive Bayes-based Context Extension for Large Language Models
Mar 26, 2024



Large Language Models (LLMs) have shown promising in-context learning abilities. However, conventional In-Context Learning (ICL) approaches are often impeded by length limitations of transformer architecture, which pose challenges when attempting to effectively integrate supervision from a substantial number of demonstration examples. In this paper, we introduce a novel framework, called Naive Bayes-based Context Extension (NBCE), to enable existing LLMs to perform ICL with an increased number of demonstrations by significantly expanding their context size. Importantly, this expansion does not require fine-tuning or dependence on particular model architectures, all the while preserving linear efficiency. NBCE initially splits the context into equal-sized windows fitting the target LLM's maximum length. Then, it introduces a voting mechanism to select the most relevant window, regarded as the posterior context. Finally, it employs Bayes' theorem to generate the test task. Our experimental results demonstrate that NBCE substantially enhances performance, particularly as the number of demonstration examples increases, consistently outperforming alternative methods. The NBCE code will be made publicly accessible. The code NBCE is available at: https://github.com/amurtadha/NBCE-master
Relationship of the language distance to English ability of a country
Nov 15, 2022Language difference is one of the factors that hinder the acquisition of second language skills. In this article, we introduce a novel solution that leverages the strength of deep neural networks to measure the semantic dissimilarity between languages based on their word distributions in the embedding space of the multilingual pre-trained language model (e.g.,BERT). Then, we empirically examine the effectiveness of the proposed semantic language distance (SLD) in explaining the consistent variation in English ability of countries, which is proxied by their performance in the Internet-Based Test of English as Foreign Language (TOEFL iBT). The experimental results show that the language distance demonstrates negative influence on a country's average English ability. Interestingly, the effect is more significant on speaking and writing subskills, which pertain to the productive aspects of language learning. Besides, we provide specific recommendations for future research directions.
Gradual Machine Learning for Aspect-level Sentiment Analysis
Jul 01, 2019
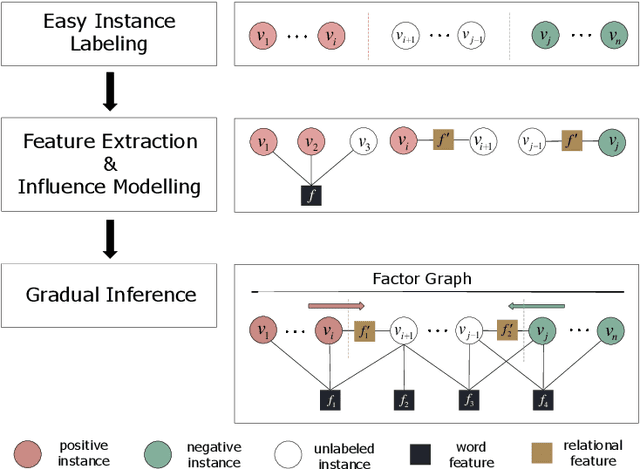

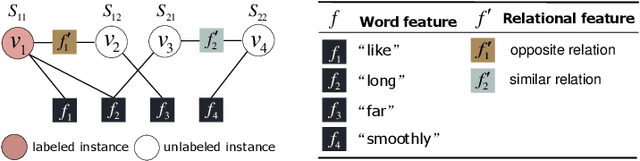
The state-of-the-art solutions for Aspect-Level Sentiment Analysis (ALSA) were built on a variety of deep neural networks (DNN), whose efficacy depends on large amounts of accurately labeled training data. Unfortunately, high-quality labeled training data usually require expensive manual work, and may thus not be readily available in real scenarios. In this paper, we propose a novel solution for ALSA based on the recently proposed paradigm of gradual machine learning, which can enable effective machine labeling without the requirement for manual labeling effort. It begins with some easy instances in an ALSA task, which can be automatically labeled by the machine with high accuracy, and then gradually labels the more challenging instances by iterative factor graph inference. In the process of gradual machine learning, the hard instances are gradually labeled in small stages based on the estimated evidential certainty provided by the labeled easier instances. Our extensive experiments on the benchmark datasets have shown that the performance of the proposed solution is considerably better than its unsupervised alternatives, and also highly competitive compared to the state-of-the-art supervised DNN techniques.