 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo You Know What You Are Talking About? Characterizing Query-Knowledge Relevance For Reliable Retrieval Augmented Generation
Oct 10, 2024



Language models (LMs) are known to suffer from hallucinations and misinformation. Retrieval augmented generation (RAG) that retrieves verifiable information from an external knowledge corpus to complement the parametric knowledge in LMs provides a tangible solution to these problems. However, the generation quality of RAG is highly dependent on the relevance between a user's query and the retrieved documents. Inaccurate responses may be generated when the query is outside of the scope of knowledge represented in the external knowledge corpus or if the information in the corpus is out-of-date. In this work, we establish a statistical framework that assesses how well a query can be answered by an RAG system by capturing the relevance of knowledge. We introduce an online testing procedure that employs goodness-of-fit (GoF) tests to inspect the relevance of each user query to detect out-of-knowledge queries with low knowledge relevance. Additionally, we develop an offline testing framework that examines a collection of user queries, aiming to detect significant shifts in the query distribution which indicates the knowledge corpus is no longer sufficiently capable of supporting the interests of the users. We demonstrate the capabilities of these strategies through a systematic evaluation on eight question-answering (QA) datasets, the results of which indicate that the new testing framework is an efficient solution to enhance the reliability of existing RAG systems.
EMP: Effective Multidimensional Persistence for Graph Representation Learning
Jan 24, 2024Topological data analysis (TDA) is gaining prominence across a wide spectrum of machine learning tasks that spans from manifold learning to graph classification. A pivotal technique within TDA is persistent homology (PH), which furnishes an exclusive topological imprint of data by tracing the evolution of latent structures as a scale parameter changes. Present PH tools are confined to analyzing data through a single filter parameter. However, many scenarios necessitate the consideration of multiple relevant parameters to attain finer insights into the data. We address this issue by introducing the Effective Multidimensional Persistence (EMP) framework. This framework empowers the exploration of data by simultaneously varying multiple scale parameters. The framework integrates descriptor functions into the analysis process, yielding a highly expressive data summary. It seamlessly integrates established single PH summaries into multidimensional counterparts like EMP Landscapes, Silhouettes, Images, and Surfaces. These summaries represent data's multidimensional aspects as matrices and arrays, aligning effectively with diverse ML models. We provide theoretical guarantees and stability proofs for EMP summaries. We demonstrate EMP's utility in graph classification tasks, showing its effectiveness. Results reveal that EMP enhances various single PH descriptors, outperforming cutting-edge methods on multiple benchmark datasets.
* arXiv admin note: text overlap with arXiv:2401.13157
Using AI Uncertainty Quantification to Improve Human Decision-Making
Sep 19, 2023



AI Uncertainty Quantification (UQ) has the potential to improve human decision-making beyond AI predictions alone by providing additional useful probabilistic information to users. The majority of past research on AI and human decision-making has concentrated on model explainability and interpretability. We implemented instance-based UQ for three real datasets. To achieve this, we trained different AI models for classification for each dataset, and used random samples generated around the neighborhood of the given instance to create confidence intervals for UQ. The computed UQ was calibrated using a strictly proper scoring rule as a form of quality assurance for UQ. We then conducted two preregistered online behavioral experiments that compared objective human decision-making performance under different AI information conditions, including UQ. In Experiment 1, we compared decision-making for no AI (control), AI prediction alone, and AI prediction with a visualization of UQ. We found UQ significantly improved decision-making beyond the other two conditions. In Experiment 2, we focused on comparing different representations of UQ information: Point vs. distribution of uncertainty and visualization type (needle vs. dotplot). We did not find meaningful differences in decision-making performance among these different representations of UQ. Overall, our results indicate that human decision-making can be improved by providing UQ information along with AI predictions, and that this benefit generalizes across a variety of representations of UQ.
Interpreting GNN-based IDS Detections Using Provenance Graph Structural Features
Jun 06, 2023



The black-box nature of complex Neural Network (NN)-based models has hindered their widespread adoption in security domains due to the lack of logical explanations and actionable follow-ups for their predictions. To enhance the transparency and accountability of Graph Neural Network (GNN) security models used in system provenance analysis, we propose PROVEXPLAINER, a framework for projecting abstract GNN decision boundaries onto interpretable feature spaces. We first replicate the decision-making process of GNNbased security models using simpler and explainable models such as Decision Trees (DTs). To maximize the accuracy and fidelity of the surrogate models, we propose novel graph structural features founded on classical graph theory and enhanced by extensive data study with security domain knowledge. Our graph structural features are closely tied to problem-space actions in the system provenance domain, which allows the detection results to be explained in descriptive, human language. PROVEXPLAINER allowed simple DT models to achieve 95% fidelity to the GNN on program classification tasks with general graph structural features, and 99% fidelity on malware detection tasks with a task-specific feature package tailored for direct interpretation. The explanations for malware classification are demonstrated with case studies of five real-world malware samples across three malware families.
IoTFlowGenerator: Crafting Synthetic IoT Device Traffic Flows for Cyber Deception
May 01, 2023Over the years, honeypots emerged as an important security tool to understand attacker intent and deceive attackers to spend time and resources. Recently, honeypots are being deployed for Internet of things (IoT) devices to lure attackers, and learn their behavior. However, most of the existing IoT honeypots, even the high interaction ones, are easily detected by an attacker who can observe honeypot traffic due to lack of real network traffic originating from the honeypot. This implies that, to build better honeypots and enhance cyber deception capabilities, IoT honeypots need to generate realistic network traffic flows. To achieve this goal, we propose a novel deep learning based approach for generating traffic flows that mimic real network traffic due to user and IoT device interactions. A key technical challenge that our approach overcomes is scarcity of device-specific IoT traffic data to effectively train a generator. We address this challenge by leveraging a core generative adversarial learning algorithm for sequences along with domain specific knowledge common to IoT devices. Through an extensive experimental evaluation with 18 IoT devices, we demonstrate that the proposed synthetic IoT traffic generation tool significantly outperforms state of the art sequence and packet generators in remaining indistinguishable from real traffic even to an adaptive attacker.
Reduction Algorithms for Persistence Diagrams of Networks: CoralTDA and PrunIT
Nov 24, 2022



Topological data analysis (TDA) delivers invaluable and complementary information on the intrinsic properties of data inaccessible to conventional methods. However, high computational costs remain the primary roadblock hindering the successful application of TDA in real-world studies, particularly with machine learning on large complex networks. Indeed, most modern networks such as citation, blockchain, and online social networks often have hundreds of thousands of vertices, making the application of existing TDA methods infeasible. We develop two new, remarkably simple but effective algorithms to compute the exact persistence diagrams of large graphs to address this major TDA limitation. First, we prove that $(k+1)$-core of a graph $\mathcal{G}$ suffices to compute its $k^{th}$ persistence diagram, $PD_k(\mathcal{G})$. Second, we introduce a pruning algorithm for graphs to compute their persistence diagrams by removing the dominated vertices. Our experiments on large networks show that our novel approach can achieve computational gains up to 95%. The developed framework provides the first bridge between the graph theory and TDA, with applications in machine learning of large complex networks. Our implementation is available at https://github.com/cakcora/PersistentHomologyWithCoralPrunit
The Impact of Data Distribution on Fairness and Robustness in Federated Learning
Nov 29, 2021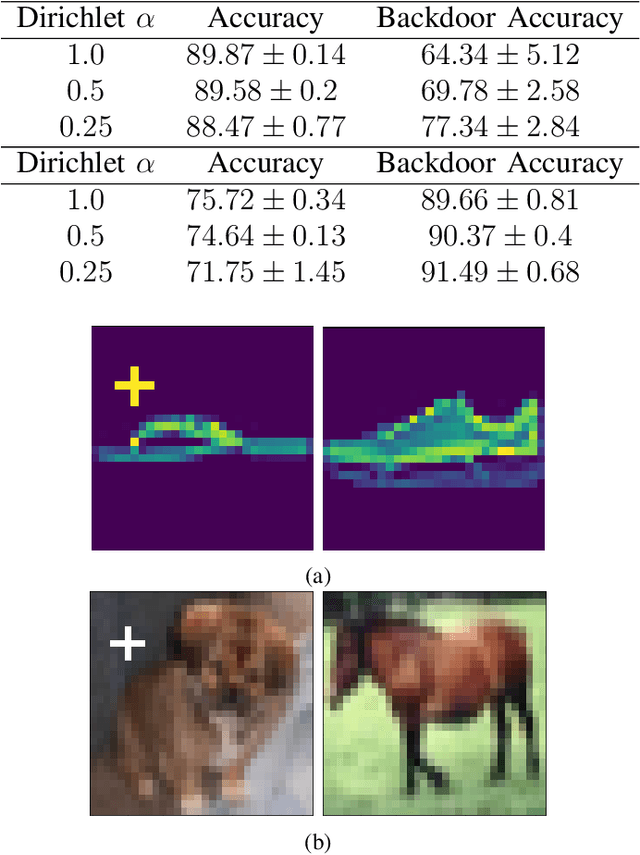

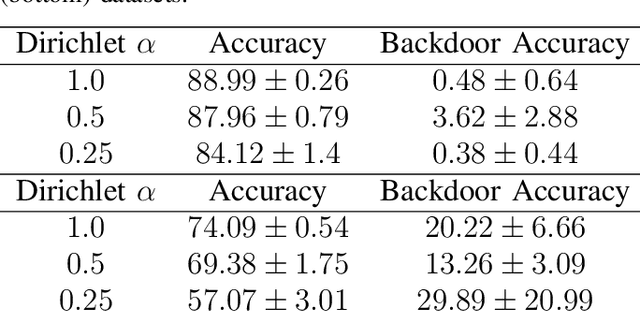
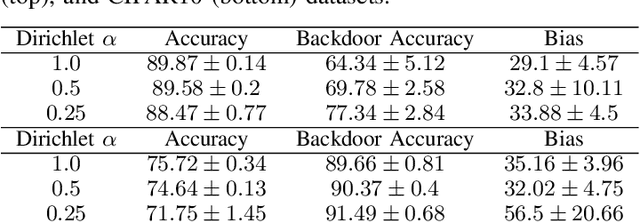
Federated Learning (FL) is a distributed machine learning protocol that allows a set of agents to collaboratively train a model without sharing their datasets. This makes FL particularly suitable for settings where data privacy is desired. However, it has been observed that the performance of FL is closely related to the similarity of the local data distributions of agents. Particularly, as the data distributions of agents differ, the accuracy of the trained models drop. In this work, we look at how variations in local data distributions affect the fairness and the robustness properties of the trained models in addition to the accuracy. Our experimental results indicate that, the trained models exhibit higher bias, and become more susceptible to attacks as local data distributions differ. Importantly, the degradation in the fairness, and robustness can be much more severe than the accuracy. Therefore, we reveal that small variations that have little impact on the accuracy could still be important if the trained model is to be deployed in a fairness/security critical context.
Multi-concept adversarial attacks
Oct 19, 2021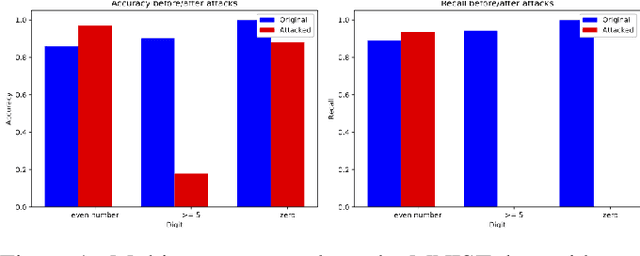
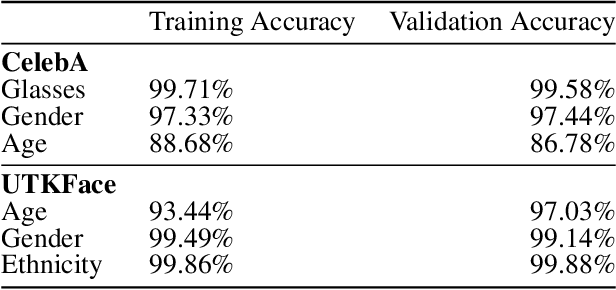

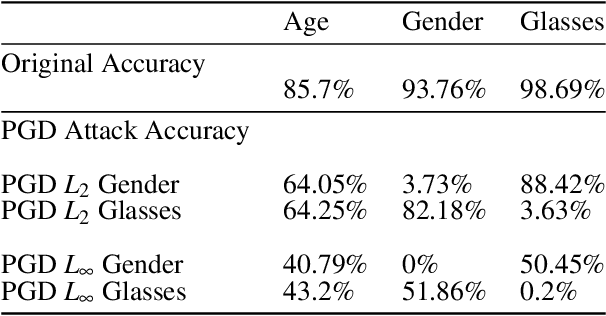
As machine learning (ML) techniques are being increasingly used in many applications, their vulnerability to adversarial attacks becomes well-known. Test time attacks, usually launched by adding adversarial noise to test instances, have been shown effective against the deployed ML models. In practice, one test input may be leveraged by different ML models. Test time attacks targeting a single ML model often neglect their impact on other ML models. In this work, we empirically demonstrate that naively attacking the classifier learning one concept may negatively impact classifiers trained to learn other concepts. For example, for the online image classification scenario, when the Gender classifier is under attack, the (wearing) Glasses classifier is simultaneously attacked with the accuracy dropped from 98.69 to 88.42. This raises an interesting question: is it possible to attack one set of classifiers without impacting the other set that uses the same test instance? Answers to the above research question have interesting implications for protecting privacy against ML model misuse. Attacking ML models that pose unnecessary risks of privacy invasion can be an important tool for protecting individuals from harmful privacy exploitation. In this paper, we address the above research question by developing novel attack techniques that can simultaneously attack one set of ML models while preserving the accuracy of the other. In the case of linear classifiers, we provide a theoretical framework for finding an optimal solution to generate such adversarial examples. Using this theoretical framework, we develop a multi-concept attack strategy in the context of deep learning. Our results demonstrate that our techniques can successfully attack the target classes while protecting the protected classes in many different settings, which is not possible with the existing test-time attack-single strategies.
Learning Generative Deception Strategies in Combinatorial Masking Games
Sep 23, 2021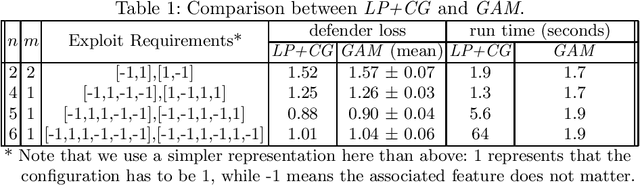
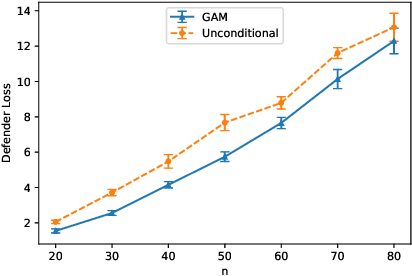
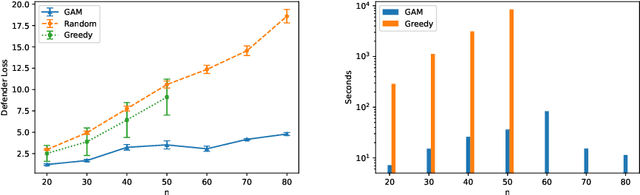
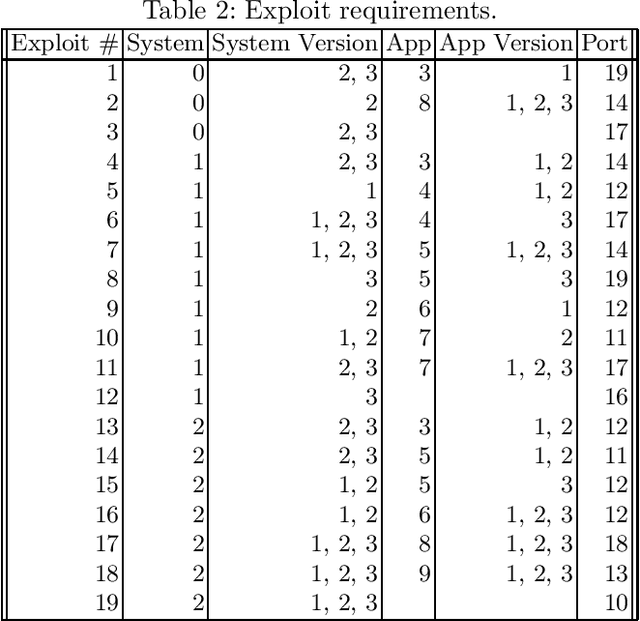
Deception is a crucial tool in the cyberdefence repertoire, enabling defenders to leverage their informational advantage to reduce the likelihood of successful attacks. One way deception can be employed is through obscuring, or masking, some of the information about how systems are configured, increasing attacker's uncertainty about their targets. We present a novel game-theoretic model of the resulting defender-attacker interaction, where the defender chooses a subset of attributes to mask, while the attacker responds by choosing an exploit to execute. The strategies of both players have combinatorial structure with complex informational dependencies, and therefore even representing these strategies is not trivial. First, we show that the problem of computing an equilibrium of the resulting zero-sum defender-attacker game can be represented as a linear program with a combinatorial number of system configuration variables and constraints, and develop a constraint generation approach for solving this problem. Next, we present a novel highly scalable approach for approximately solving such games by representing the strategies of both players as neural networks. The key idea is to represent the defender's mixed strategy using a deep neural network generator, and then using alternating gradient-descent-ascent algorithm, analogous to the training of Generative Adversarial Networks. Our experiments, as well as a case study, demonstrate the efficacy of the proposed approach.
BiFair: Training Fair Models with Bilevel Optimization
Jun 03, 2021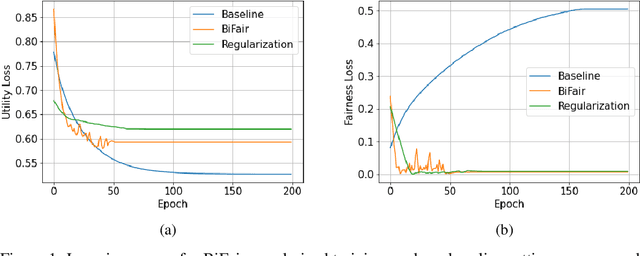
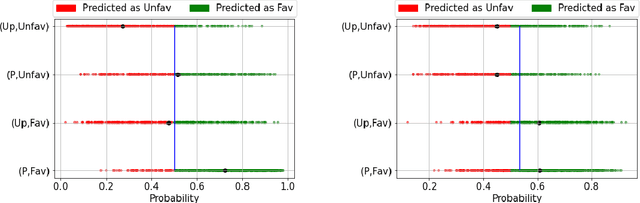
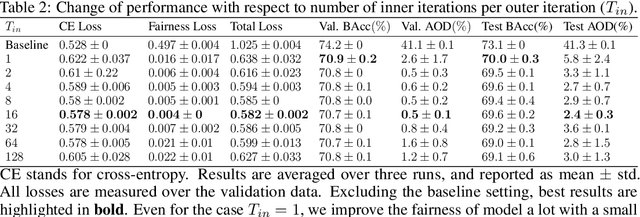
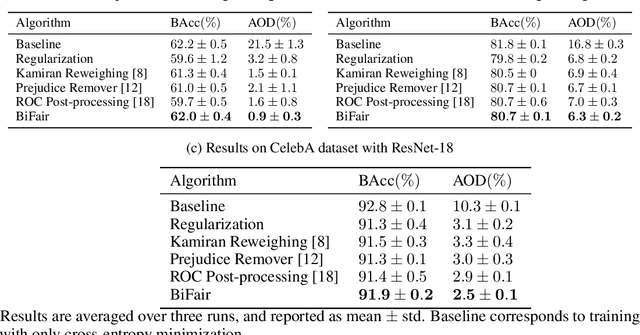
Prior studies have shown that, training machine learning models via empirical loss minimization to maximize a utility metric (e.g., accuracy), might yield models that make discriminatory predictions. To alleviate this issue, we develop a new training algorithm, named BiFair, which jointly minimizes for a utility, and a fairness loss of interest. Crucially, we do so without directly modifying the training objective, e.g., by adding regularization terms. Rather, we learn a set of weights on the training dataset, such that, training on the weighted dataset ensures both good utility, and fairness. The dataset weights are learned in concurrence to the model training, which is done by solving a bilevel optimization problem using a held-out validation dataset. Overall, this approach yields models with better fairness-utility trade-offs. Particularly, we compare our algorithm with three other state-of-the-art fair training algorithms over three real-world datasets, and demonstrate that, BiFair consistently performs better, i.e., we reach to better values of a given fairness metric under same, or higher accuracy. Further, our algorithm is scalable. It is applicable both to simple models, such as logistic regression, as well as more complex models, such as deep neural networks, as evidenced by our experimental analysis.