 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA unified Benchmark for Multi-Frame Image Restoration under Severe Refractive Warping
May 06, 2026Video sequence capturing through refractive dynamic media, such as a turbulent air or water surface, often suffer from severe geometric distortions and temporal instability. While recent advances address mild atmospheric turbulence, no existing benchmarks systematically evaluate restoration methods under strong and highly nonuniform refractive conditions. We present a comprehensive benchmark for geometric distortion removal in video, covering a range from turbulence-like mild warping to strong discontinuous refractive deformations. The benchmark includes both laboratory-captured real data and synthetic sequences generated for static scenes via physics-based light refraction modeling across four distortion levels and multiple surface wave types. We evaluate a spectrum of methods from simple baselines and classical registration algorithms to advanced learning-based approaches including DATUM and our proposed diffusion based V-cache for high and extreme distortions regimes. Evaluation uses both pixel-level (PSNR, SSIM), and perceptual (LPIPS, DINO, CLIP) metrics providing the first large scale analysis of geometric distortion removal. Our benchmark establishes a new foundation for developing and evaluating algorithms capable of reconstructing video from highly distorted optical environments. Our code and datasets are available at https://github.com/iafoss/refractive-mfir-benchmark.
Joint Video and Text Parsing for Understanding Events and Answering Queries
Feb 21, 2014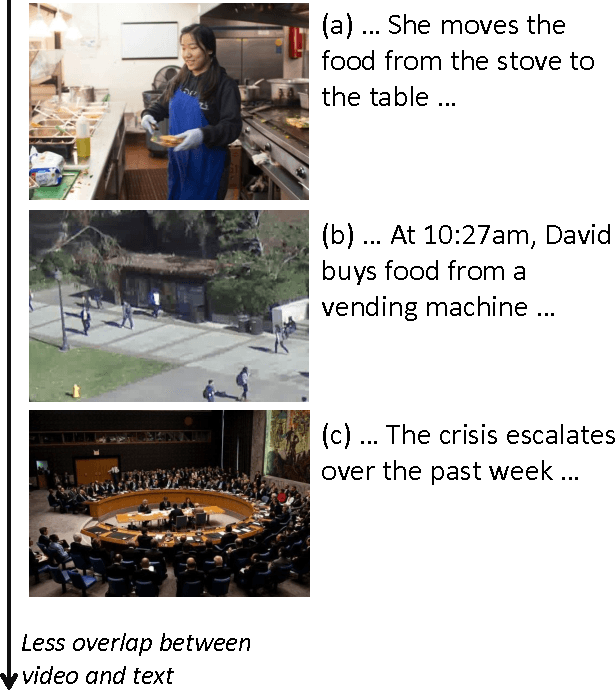
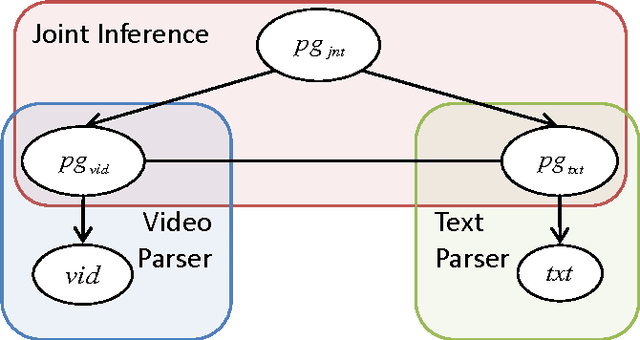
We propose a framework for parsing video and text jointly for understanding events and answering user queries. Our framework produces a parse graph that represents the compositional structures of spatial information (objects and scenes), temporal information (actions and events) and causal information (causalities between events and fluents) in the video and text. The knowledge representation of our framework is based on a spatial-temporal-causal And-Or graph (S/T/C-AOG), which jointly models possible hierarchical compositions of objects, scenes and events as well as their interactions and mutual contexts, and specifies the prior probabilistic distribution of the parse graphs. We present a probabilistic generative model for joint parsing that captures the relations between the input video/text, their corresponding parse graphs and the joint parse graph. Based on the probabilistic model, we propose a joint parsing system consisting of three modules: video parsing, text parsing and joint inference. Video parsing and text parsing produce two parse graphs from the input video and text respectively. The joint inference module produces a joint parse graph by performing matching, deduction and revision on the video and text parse graphs. The proposed framework has the following objectives: Firstly, we aim at deep semantic parsing of video and text that goes beyond the traditional bag-of-words approaches; Secondly, we perform parsing and reasoning across the spatial, temporal and causal dimensions based on the joint S/T/C-AOG representation; Thirdly, we show that deep joint parsing facilitates subsequent applications such as generating narrative text descriptions and answering queries in the forms of who, what, when, where and why. We empirically evaluated our system based on comparison against ground-truth as well as accuracy of query answering and obtained satisfactory results.