 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Continual, Online, Unsupervised Depth
Mar 02, 2021


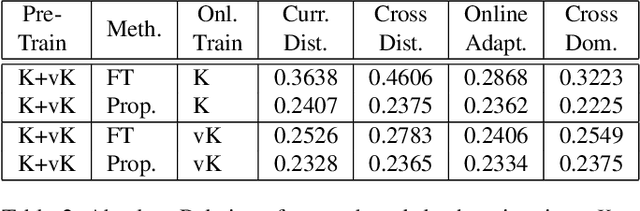
Although depth extraction with passive sensors has seen remarkable improvement with deep learning, these approaches may fail to obtain correct depth if they are exposed to environments not observed during training. Online adaptation, where the neural network trains while deployed, with unsupervised learning provides a convenient solution. However, online adaptation causes a neural network to forget the past. Thus, past training is wasted and the network is not able to provide good results if it observes past scenes. This work deals with practical online-adaptation where the input is online and temporally-correlated, and training is completely unsupervised. Regularization and replay-based methods without task boundaries are proposed to avoid catastrophic forgetting while adapting to online data. Experiments are performed on different datasets with both structure-from-motion and stereo. Results of forgetting as well as adaptation are provided, which are superior to recent methods. The proposed approach is more inline with the artificial general intelligence paradigm as the neural network learns the scene where it is deployed without any supervision (target labels and tasks) and without forgetting about the past. Code is available at github.com/umarKarim/cou_stereo and github.com/umarKarim/cou_sfm.
Increased-Range Unsupervised Monocular Depth Estimation
Jun 23, 2020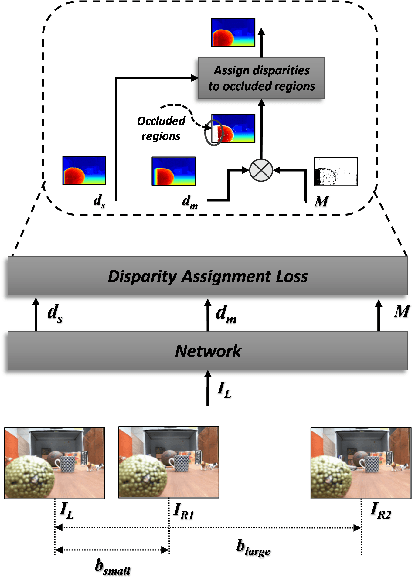
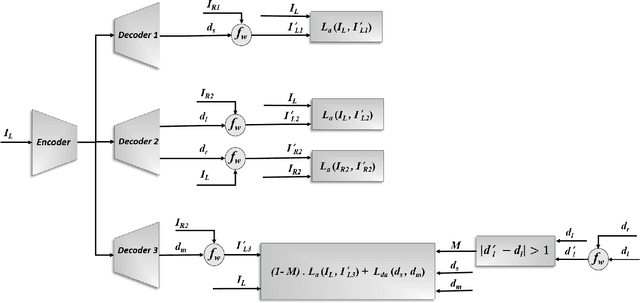
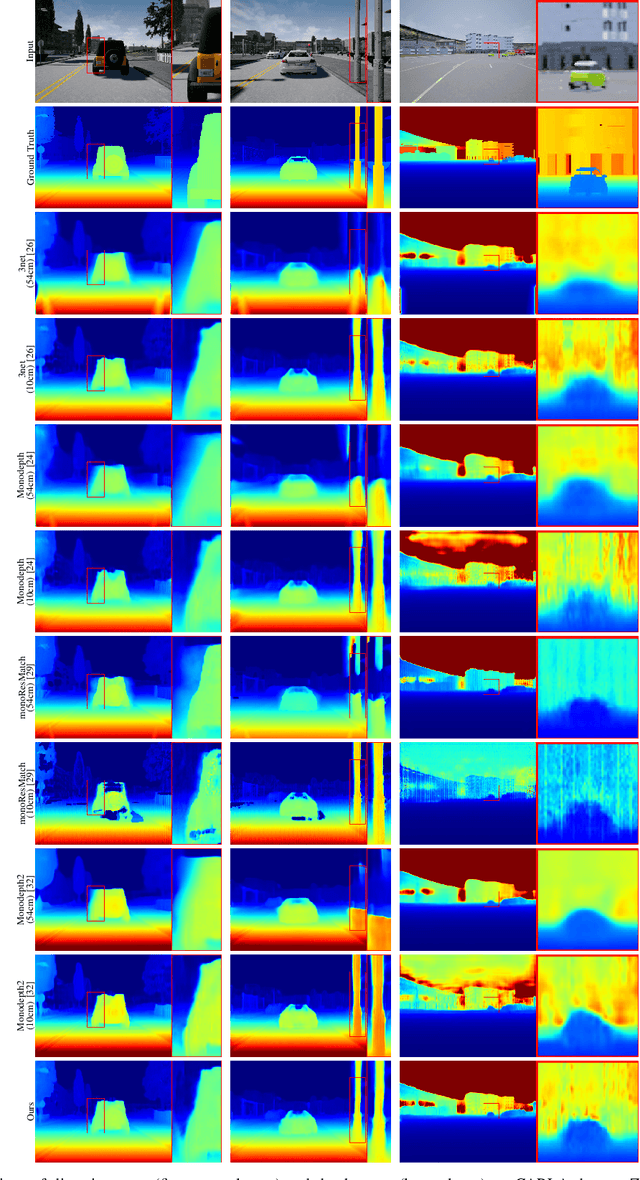
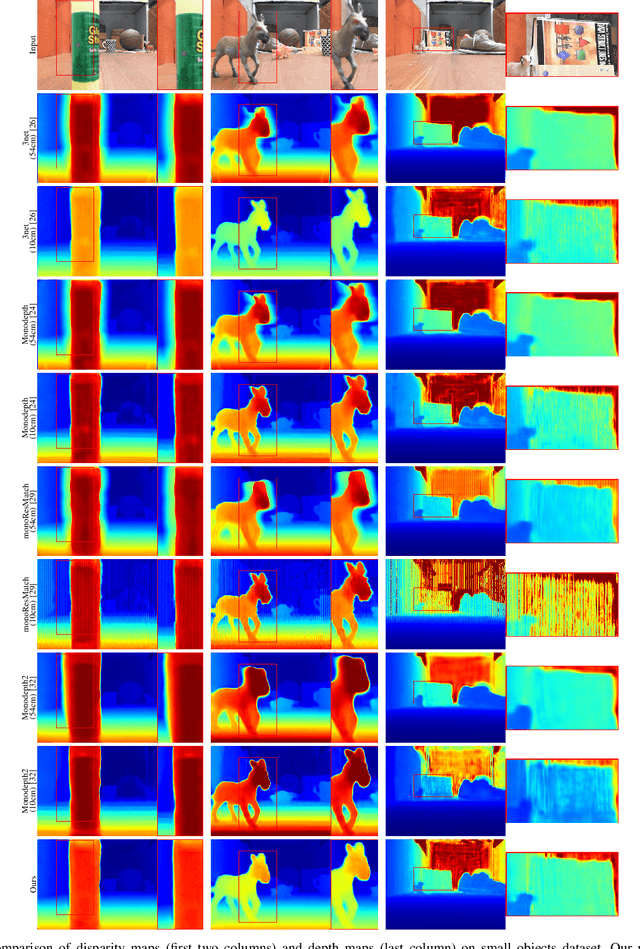
Unsupervised deep learning methods have shown promising performance for single-image depth estimation. Since most of these methods use binocular stereo pairs for self-supervision, the depth range is generally limited. Small-baseline stereo pairs provide small depth range but handle occlusions well. On the other hand, stereo images acquired with a wide-baseline rig cause occlusions-related errors in the near range but estimate depth well in the far range. In this work, we propose to integrate the advantages of the small and wide baselines. By training the network using three horizontally aligned views, we obtain accurate depth predictions for both close and far ranges. Our strategy allows to infer multi-baseline depth from a single image. This is unlike previous multi-baseline systems which employ more than two cameras. The qualitative and quantitative results show the superior performance of multi-baseline approach over previous stereo-based monocular methods. For 0.1 to 80 meters depth range, our approach decreases the absolute relative error of depth by 24% compared to Monodepth2. Our approach provides 21 frames per second on a single Nvidia1080 GPU, making it useful for practical applications.
Self-Supervised Representation Learning for Visual Anomaly Detection
Jun 17, 2020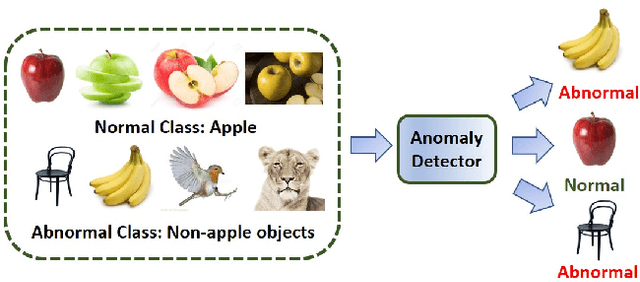
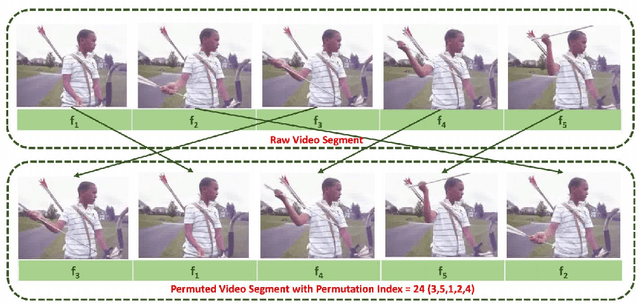
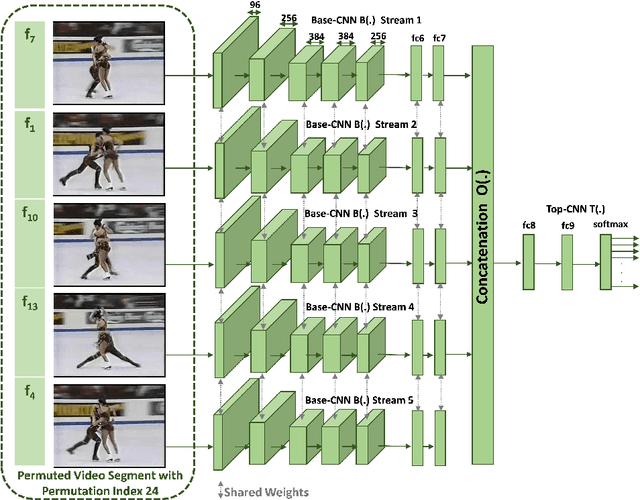
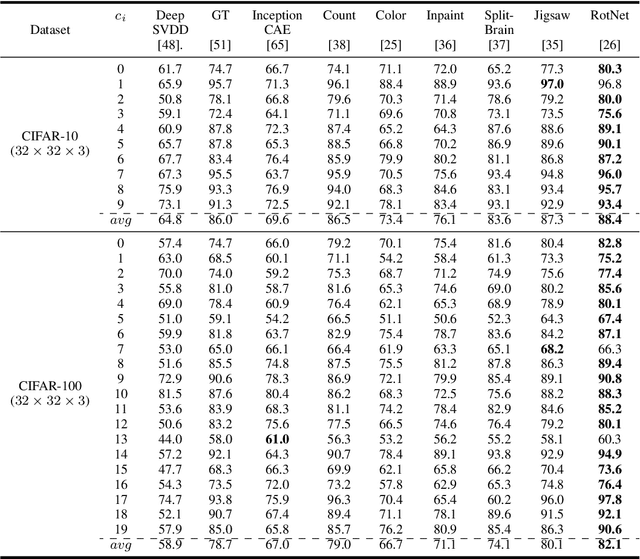
Self-supervised learning allows for better utilization of unlabelled data. The feature representation obtained by self-supervision can be used in downstream tasks such as classification, object detection, segmentation, and anomaly detection. While classification, object detection, and segmentation have been investigated with self-supervised learning, anomaly detection needs more attention. We consider the problem of anomaly detection in images and videos, and present a new visual anomaly detection technique for videos. Numerous seminal and state-of-the-art self-supervised methods are evaluated for anomaly detection on a variety of image datasets. The best performing image-based self-supervised representation learning method is then used for video anomaly detection to see the importance of spatial features in visual anomaly detection in videos. We also propose a simple self-supervision approach for learning temporal coherence across video frames without the use of any optical flow information. At its core, our method identifies the frame indices of a jumbled video sequence allowing it to learn the spatiotemporal features of the video. This intuitive approach shows superior performance of visual anomaly detection compared to numerous methods for images and videos on UCF101 and ILSVRC2015 video datasets.
Fine-Tuning DARTS for Image Classification
Jun 16, 2020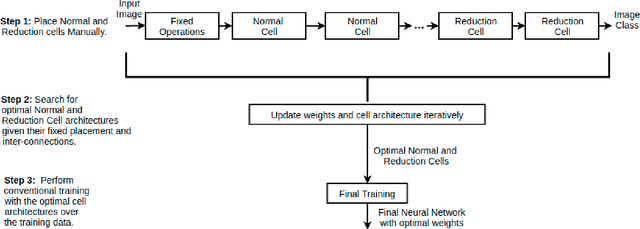
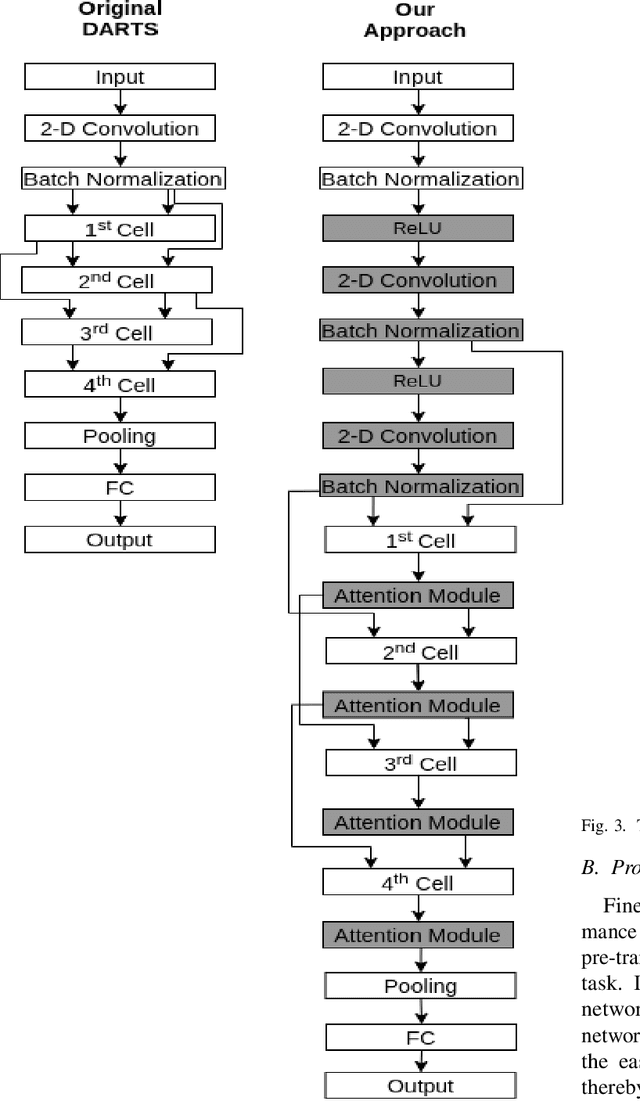
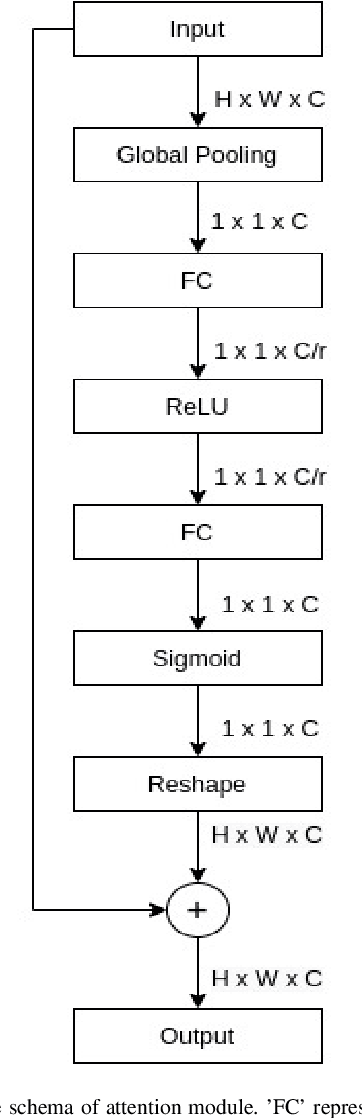
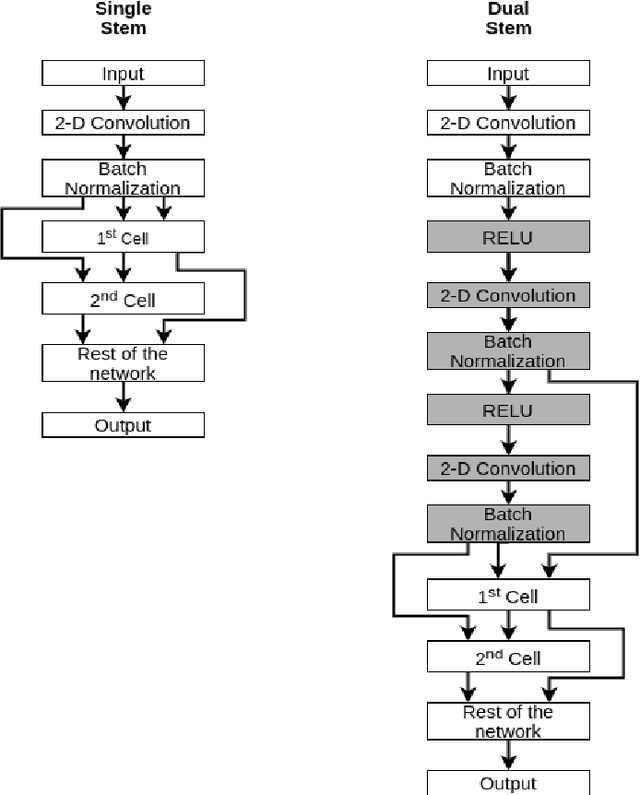
Neural Architecture Search (NAS) has gained attraction due to superior classification performance. Differential Architecture Search (DARTS) is a computationally light method. To limit computational resources DARTS makes numerous approximations. These approximations result in inferior performance. We propose to fine-tune DARTS using fixed operations as they are independent of these approximations. Our method offers a good trade-off between the number of parameters and classification accuracy. Our approach improves the top-1 accuracy on Fashion-MNIST, CompCars, and MIO-TCD datasets by 0.56%, 0.50%, and 0.39%, respectively compared to the state-of-the-art approaches. Our approach performs better than DARTS, improving the accuracy by 0.28%, 1.64%, 0.34%, 4.5%, and 3.27% compared to DARTS, on CIFAR-10, CIFAR-100, Fashion-MNIST, CompCars, and MIO-TCD datasets, respectively.
Global Feature Aggregation for Accident Anticipation
Jun 16, 2020
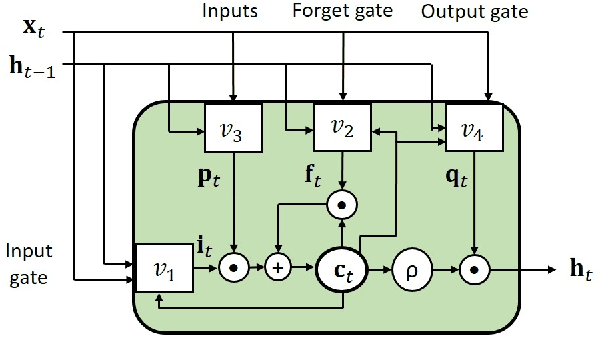
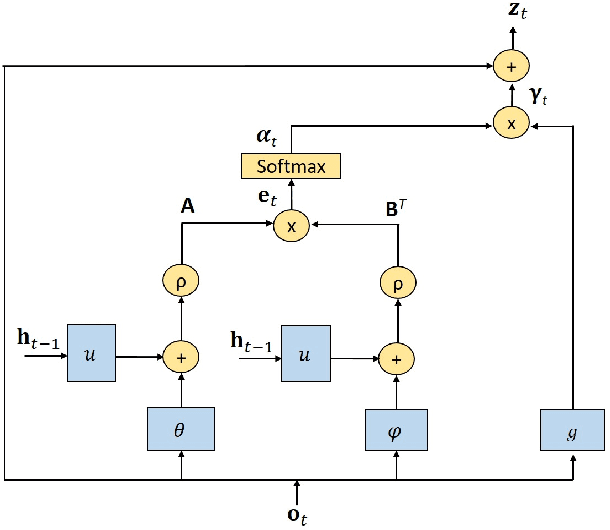
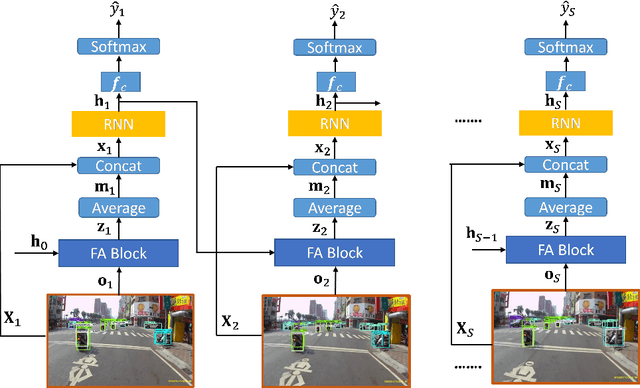
Anticipation of accidents ahead of time in autonomous and non-autonomous vehicles aids in accident avoidance. In order to recognize abnormal events such as traffic accidents in a video sequence, it is important that the network takes into account interactions of objects in a given frame. We propose a novel Feature Aggregation (FA) block that refines each object's features by computing a weighted sum of the features of all objects in a frame. We use FA block along with Long Short Term Memory (LSTM) network to anticipate accidents in the video sequences. We report mean Average Precision (mAP) and Average Time-to-Accident (ATTA) on Street Accident (SA) dataset. Our proposed method achieves the highest score for risk anticipation by predicting accidents 0.32 sec and 0.75 sec earlier compared to the best results with Adaptive Loss and dynamic parameter prediction based methods respectively.
Plug-and-Play Anomaly Detection with Expectation Maximization Filtering
Jun 16, 2020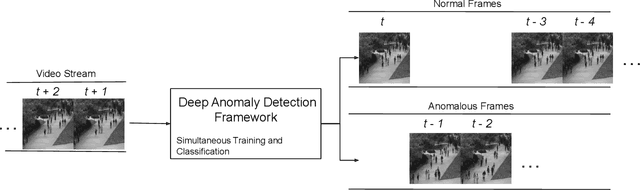

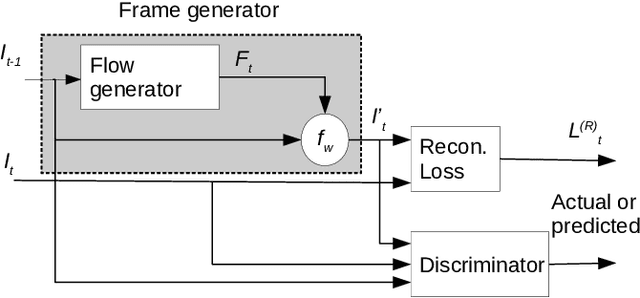

Anomaly detection in crowds enables early rescue response. A plug-and-play smart camera for crowd surveillance has numerous constraints different from typical anomaly detection: the training data cannot be used iteratively; there are no training labels; and training and classification needs to be performed simultaneously. We tackle all these constraints with our approach in this paper. We propose a Core Anomaly-Detection (CAD) neural network which learns the motion behavior of objects in the scene with an unsupervised method. On average over standard datasets, CAD with a single epoch of training shows a percentage increase in Area Under the Curve (AUC) of 4.66% and 4.9% compared to the best results with convolutional autoencoders and convolutional LSTM-based methods, respectively. With a single epoch of training, our method improves the AUC by 8.03% compared to the convolutional LSTM-based approach. We also propose an Expectation Maximization filter which chooses samples for training the core anomaly-detection network. The overall framework improves the AUC compared to future frame prediction-based approach by 24.87% when crowd anomaly detection is performed on a video stream. We believe our work is the first step towards using deep learning methods with autonomous plug-and-play smart cameras for crowd anomaly detection.