 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAWDet-7: A Multi-Scenario Benchmark for Object Detection and Description on Quantized RAW Images
Feb 03, 2026Most vision models are trained on RGB images processed through ISP pipelines optimized for human perception, which can discard sensor-level information useful for machine reasoning. RAW images preserve unprocessed scene data, enabling models to leverage richer cues for both object detection and object description, capturing fine-grained details, spatial relationships, and contextual information often lost in processed images. To support research in this domain, we introduce RAWDet-7, a large-scale dataset of ~25k training and 7.6k test RAW images collected across diverse cameras, lighting conditions, and environments, densely annotated for seven object categories following MS-COCO and LVIS conventions. In addition, we provide object-level descriptions derived from the corresponding high-resolution sRGB images, facilitating the study of object-level information preservation under RAW image processing and low-bit quantization. The dataset allows evaluation under simulated 4-bit, 6-bit, and 8-bit quantization, reflecting realistic sensor constraints, and provides a benchmark for studying detection performance, description quality & detail, and generalization in low-bit RAW image processing. Dataset & code upon acceptance.
$γ$-Quant: Towards Learnable Quantization for Low-bit Pattern Recognition
Sep 26, 2025Most pattern recognition models are developed on pre-proce\-ssed data. In computer vision, for instance, RGB images processed through image signal processing (ISP) pipelines designed to cater to human perception are the most frequent input to image analysis networks. However, many modern vision tasks operate without a human in the loop, raising the question of whether such pre-processing is optimal for automated analysis. Similarly, human activity recognition (HAR) on body-worn sensor data commonly takes normalized floating-point data arising from a high-bit analog-to-digital converter (ADC) as an input, despite such an approach being highly inefficient in terms of data transmission, significantly affecting the battery life of wearable devices. In this work, we target low-bandwidth and energy-constrained settings where sensors are limited to low-bit-depth capture. We propose $\gamma$-Quant, i.e.~the task-specific learning of a non-linear quantization for pattern recognition. We exemplify our approach on raw-image object detection as well as HAR of wearable data, and demonstrate that raw data with a learnable quantization using as few as 4-bits can perform on par with the use of raw 12-bit data. All code to reproduce our experiments is publicly available via https://github.com/Mishalfatima/Gamma-Quant
Corner Cases: How Size and Position of Objects Challenge ImageNet-Trained Models
May 06, 2025Backgrounds in images play a major role in contributing to spurious correlations among different data points. Owing to aesthetic preferences of humans capturing the images, datasets can exhibit positional (location of the object within a given frame) and size (region-of-interest to image ratio) biases for different classes. In this paper, we show that these biases can impact how much a model relies on spurious features in the background to make its predictions. To better illustrate our findings, we propose a synthetic dataset derived from ImageNet1k, Hard-Spurious-ImageNet, which contains images with various backgrounds, object positions, and object sizes. By evaluating the dataset on different pretrained models, we find that most models rely heavily on spurious features in the background when the region-of-interest (ROI) to image ratio is small and the object is far from the center of the image. Moreover, we also show that current methods that aim to mitigate harmful spurious features, do not take into account these factors, hence fail to achieve considerable performance gains for worst-group accuracies when the size and location of core features in an image change.
Global Feature Aggregation for Accident Anticipation
Jun 16, 2020
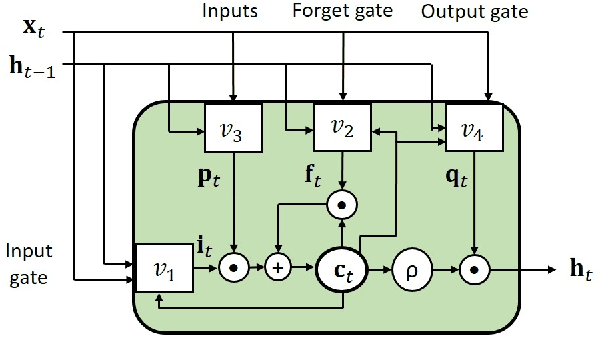
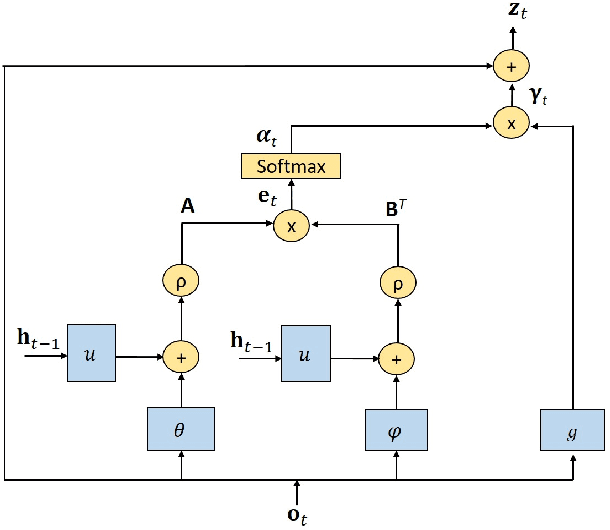
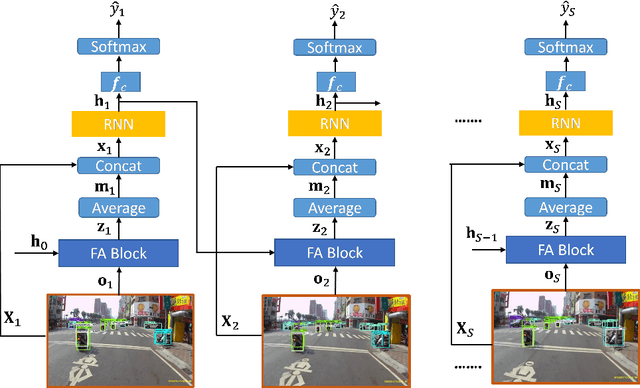
Anticipation of accidents ahead of time in autonomous and non-autonomous vehicles aids in accident avoidance. In order to recognize abnormal events such as traffic accidents in a video sequence, it is important that the network takes into account interactions of objects in a given frame. We propose a novel Feature Aggregation (FA) block that refines each object's features by computing a weighted sum of the features of all objects in a frame. We use FA block along with Long Short Term Memory (LSTM) network to anticipate accidents in the video sequences. We report mean Average Precision (mAP) and Average Time-to-Accident (ATTA) on Street Accident (SA) dataset. Our proposed method achieves the highest score for risk anticipation by predicting accidents 0.32 sec and 0.75 sec earlier compared to the best results with Adaptive Loss and dynamic parameter prediction based methods respectively.
Plug-and-Play Anomaly Detection with Expectation Maximization Filtering
Jun 16, 2020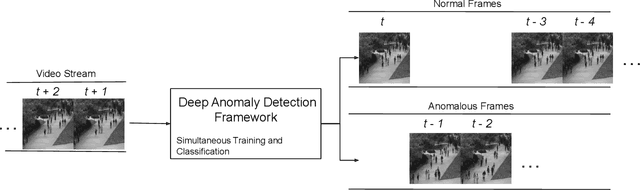

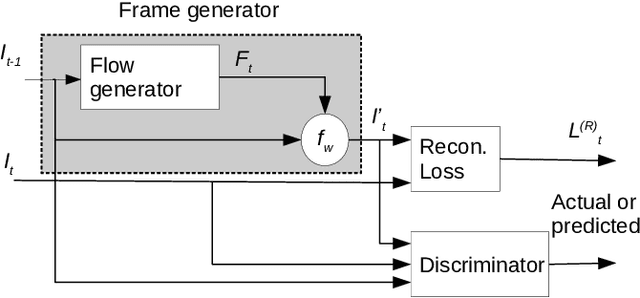

Anomaly detection in crowds enables early rescue response. A plug-and-play smart camera for crowd surveillance has numerous constraints different from typical anomaly detection: the training data cannot be used iteratively; there are no training labels; and training and classification needs to be performed simultaneously. We tackle all these constraints with our approach in this paper. We propose a Core Anomaly-Detection (CAD) neural network which learns the motion behavior of objects in the scene with an unsupervised method. On average over standard datasets, CAD with a single epoch of training shows a percentage increase in Area Under the Curve (AUC) of 4.66% and 4.9% compared to the best results with convolutional autoencoders and convolutional LSTM-based methods, respectively. With a single epoch of training, our method improves the AUC by 8.03% compared to the convolutional LSTM-based approach. We also propose an Expectation Maximization filter which chooses samples for training the core anomaly-detection network. The overall framework improves the AUC compared to future frame prediction-based approach by 24.87% when crowd anomaly detection is performed on a video stream. We believe our work is the first step towards using deep learning methods with autonomous plug-and-play smart cameras for crowd anomaly detection.