 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOST: Motion Diffusion Model for Rare Text via Temporal Clip Banzhaf Interaction
Jul 09, 2025



We introduce MOST, a novel motion diffusion model via temporal clip Banzhaf interaction, aimed at addressing the persistent challenge of generating human motion from rare language prompts. While previous approaches struggle with coarse-grained matching and overlook important semantic cues due to motion redundancy, our key insight lies in leveraging fine-grained clip relationships to mitigate these issues. MOST's retrieval stage presents the first formulation of its kind - temporal clip Banzhaf interaction - which precisely quantifies textual-motion coherence at the clip level. This facilitates direct, fine-grained text-to-motion clip matching and eliminates prevalent redundancy. In the generation stage, a motion prompt module effectively utilizes retrieved motion clips to produce semantically consistent movements. Extensive evaluations confirm that MOST achieves state-of-the-art text-to-motion retrieval and generation performance by comprehensively addressing previous challenges, as demonstrated through quantitative and qualitative results highlighting its effectiveness, especially for rare prompts.
Improving Machine Reading Comprehension with Single-choice Decision and Transfer Learning
Nov 06, 2020
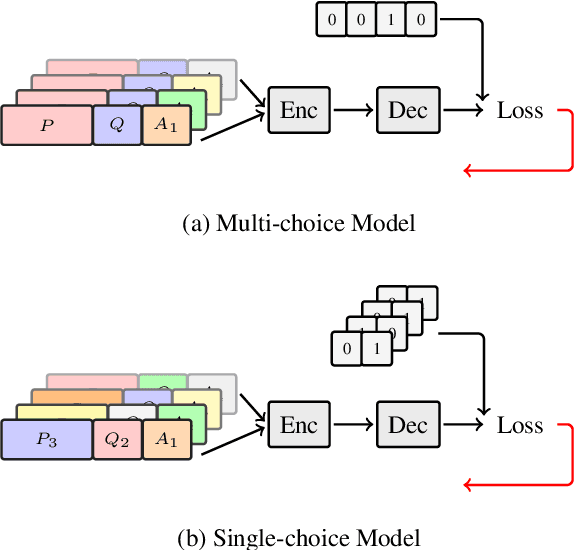
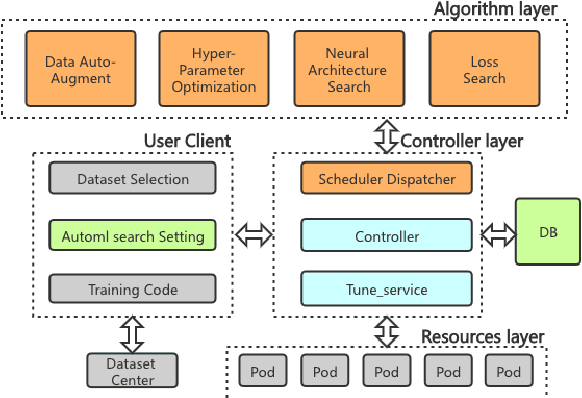
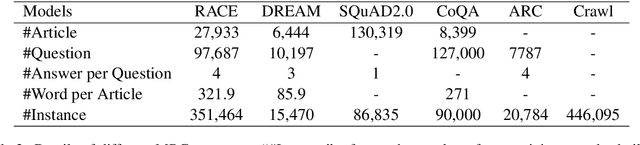
Multi-choice Machine Reading Comprehension (MMRC) aims to select the correct answer from a set of options based on a given passage and question. Due to task specific of MMRC, it is no-trivial to transfer knowledge from other MRC tasks such as SQuAD, Dream. In this paper, we simply reconstruct multi-choice to single-choice by training a binary classification to distinguish whether a certain answer is correct. Then select the option with the highest confidence score. We construct our model upon ALBERT-xxlarge model and estimate it on the RACE dataset. During training, We adopt AutoML strategy to tune better parameters. Experimental results show that the single-choice is better than multi-choice. In addition, by transferring knowledge from other kinds of MRC tasks, our model achieves the new state of the art results in both single and ensemble settings.