 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Lifelong Learning of Multilingual Text-To-Speech Synthesis
Oct 09, 2021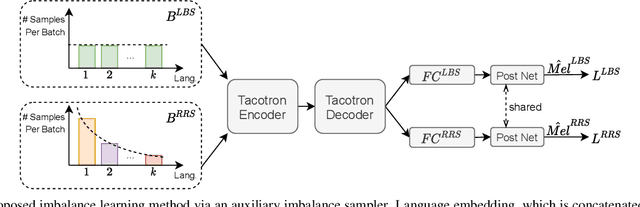
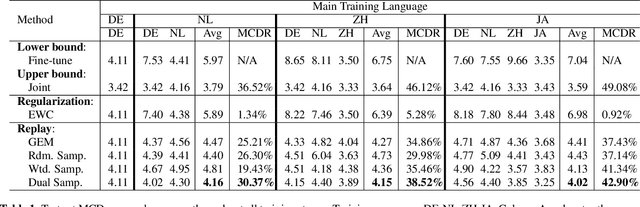
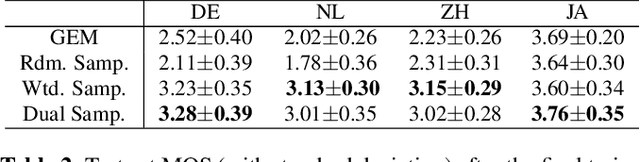
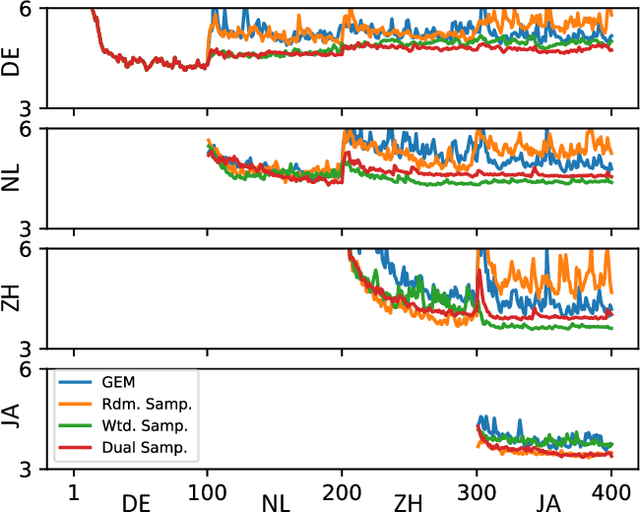
This work presents a lifelong learning approach to train a multilingual Text-To-Speech (TTS) system, where each language was seen as an individual task and was learned sequentially and continually. It does not require pooled data from all languages altogether, and thus alleviates the storage and computation burden. One of the challenges of lifelong learning methods is "catastrophic forgetting": in TTS scenario it means that model performance quickly degrades on previous languages when adapted to a new language. We approach this problem via a data-replay-based lifelong learning method. We formulate the replay process as a supervised learning problem, and propose a simple yet effective dual-sampler framework to tackle the heavily language-imbalanced training samples. Through objective and subjective evaluations, we show that this supervised learning formulation outperforms other gradient-based and regularization-based lifelong learning methods, achieving 43% Mel-Cepstral Distortion reduction compared to a fine-tuning baseline.
EventPlus: A Temporal Event Understanding Pipeline
Jan 13, 2021
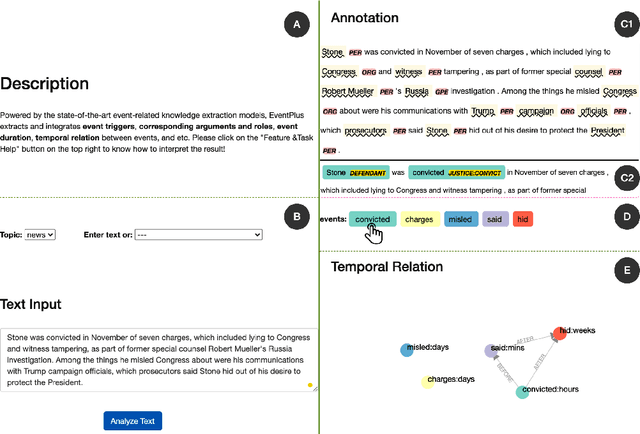


We present EventPlus, a temporal event understanding pipeline that integrates various state-of-the-art event understanding components including event trigger and type detection, event argument detection, event duration and temporal relation extraction. Event information, especially event temporal knowledge, is a type of common sense knowledge that helps people understand how stories evolve and provides predictive hints for future events. EventPlus as the first comprehensive temporal event understanding pipeline provides a convenient tool for users to quickly obtain annotations about events and their temporal information for any user-provided document. Furthermore, we show EventPlus can be easily adapted to other domains (e.g., biomedical domain). We make EventPlus publicly available to facilitate event-related information extraction and downstream applications.
Biomedical Event Extraction with Hierarchical Knowledge Graphs
Oct 12, 2020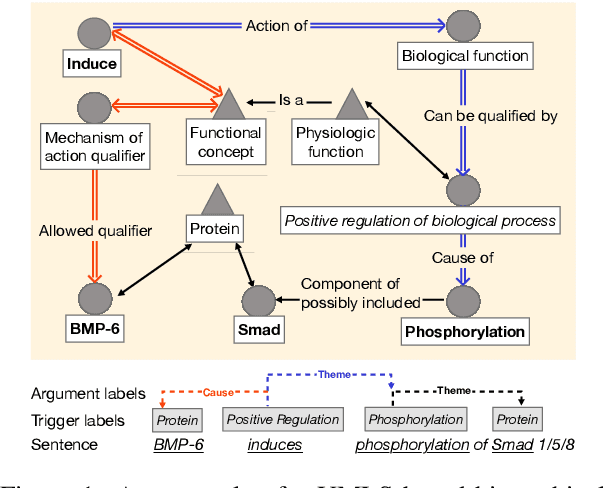
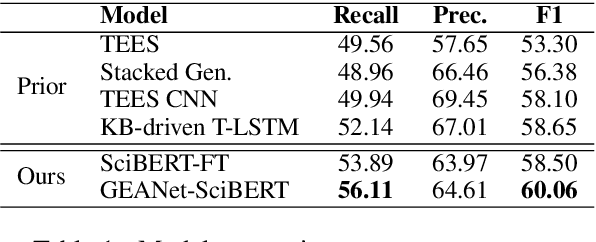
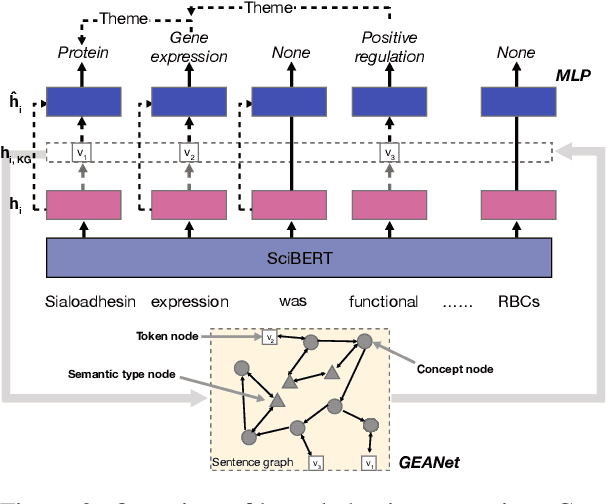
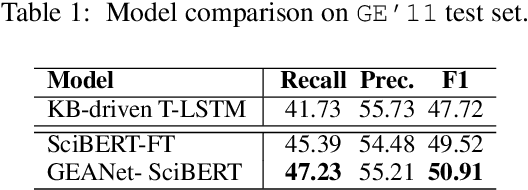
Biomedical event extraction is critical in understanding biomolecular interactions described in scientific corpus. One of the main challenges is to identify nested structured events that are associated with non-indicative trigger words. We propose to incorporate domain knowledge from Unified Medical Language System (UMLS) to a pre-trained language model via Graph Edge-conditioned Attention Networks (GEANet) and hierarchical graph representation. To better recognize the trigger words, each sentence is first grounded to a sentence graph based on a jointly modeled hierarchical knowledge graph from UMLS. The grounded graphs are then propagated by GEANet, a novel graph neural networks for enhanced capabilities in inferring complex events. On BioNLP 2011 GENIA Event Extraction task, our approach achieved 1.41% F1 and 3.19% F1 improvements on all events and complex events, respectively. Ablation studies confirm the importance of GEANet and hierarchical KG.
Deep Structured Neural Network for Event Temporal Relation Extraction
Sep 24, 2019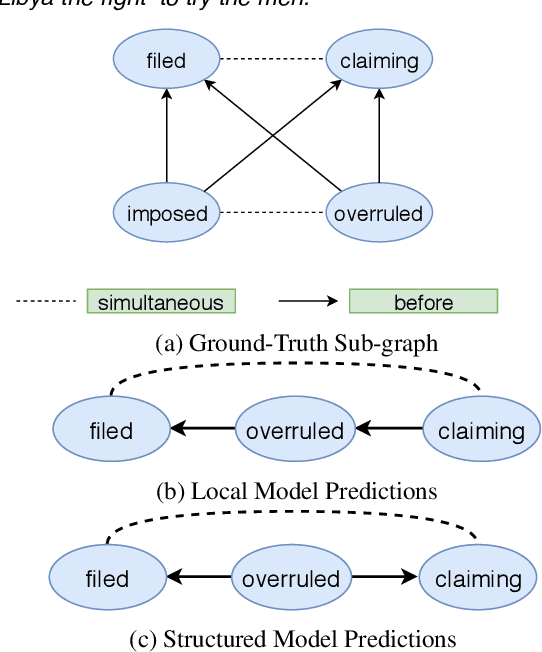
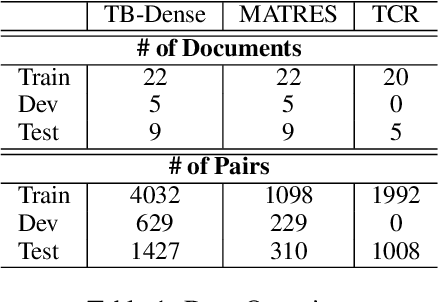
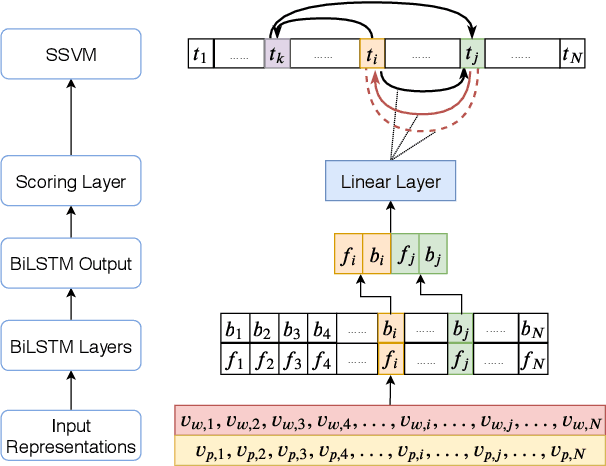
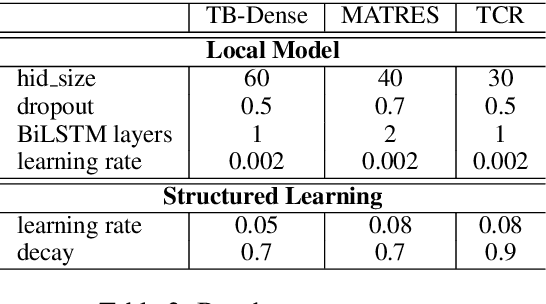
We propose a novel deep structured learning framework for event temporal relation extraction. The model consists of 1) a recurrent neural network (RNN) to learn scoring functions for pair-wise relations, and 2) a structured support vector machine (SSVM) to make joint predictions. The neural network automatically learns representations that account for long-term contexts to provide robust features for the structured model, while the SSVM incorporates domain knowledge such as transitive closure of temporal relations as constraints to make better globally consistent decisions. By jointly training the two components, our model combines the benefits of both data-driven learning and knowledge exploitation. Experimental results on three high-quality event temporal relation datasets (TCR, MATRES, and TB-Dense) demonstrate that incorporated with pre-trained contextualized embeddings, the proposed model achieves significantly better performances than the state-of-the-art methods on all three datasets. We also provide thorough ablation studies to investigate our model.
Spoken Language Intent Detection using Confusion2Vec
Apr 07, 2019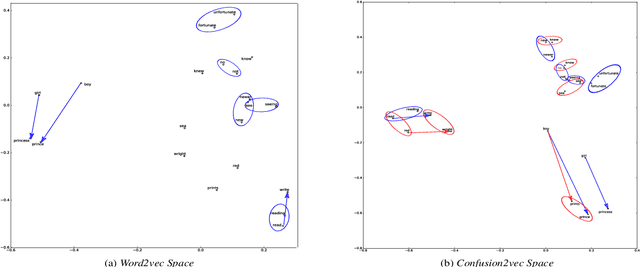
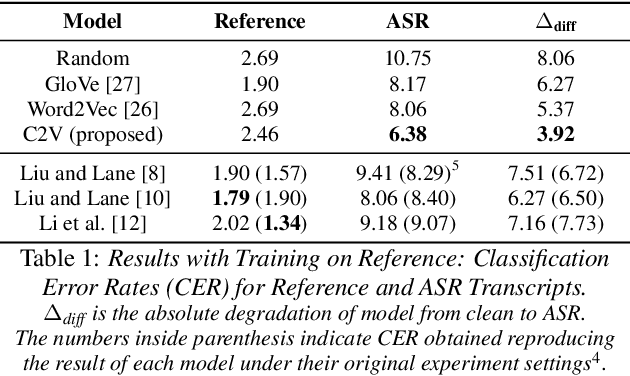
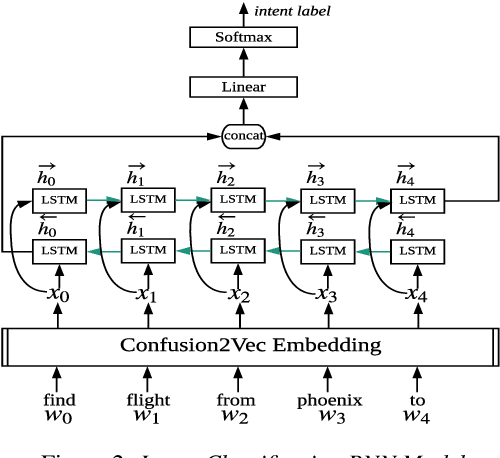
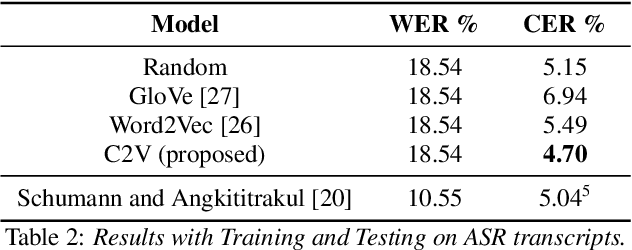
Decoding speaker's intent is a crucial part of spoken language understanding (SLU). The presence of noise or errors in the text transcriptions, in real life scenarios make the task more challenging. In this paper, we address the spoken language intent detection under noisy conditions imposed by automatic speech recognition (ASR) systems. We propose to employ confusion2vec word feature representation to compensate for the errors made by ASR and to increase the robustness of the SLU system. The confusion2vec, motivated from human speech production and perception, models acoustic relationships between words in addition to the semantic and syntactic relations of words in human language. We hypothesize that ASR often makes errors relating to acoustically similar words, and the confusion2vec with inherent model of acoustic relationships between words is able to compensate for the errors. We demonstrate through experiments on the ATIS benchmark dataset, the robustness of the proposed model to achieve state-of-the-art results under noisy ASR conditions. Our system reduces classification error rate (CER) by 20.84% and improves robustness by 37.48% (lower CER degradation) relative to the previous state-of-the-art going from clean to noisy transcripts. Improvements are also demonstrated when training the intent detection models on noisy transcripts.
Deep Hybrid Scattering Image Learning
Sep 19, 2018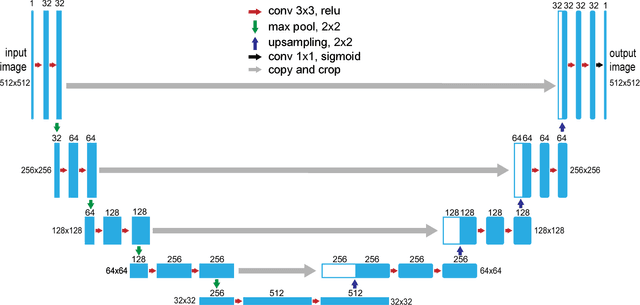
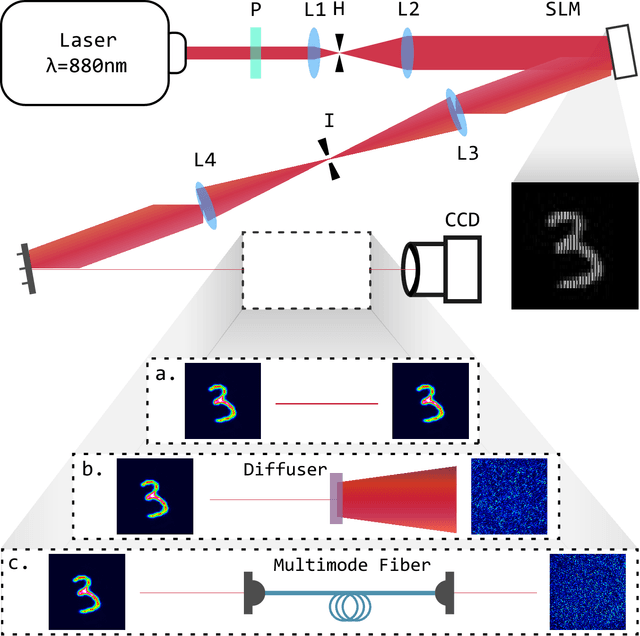
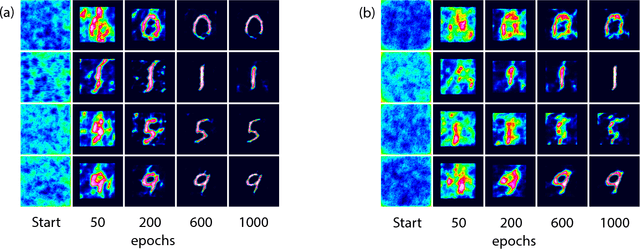
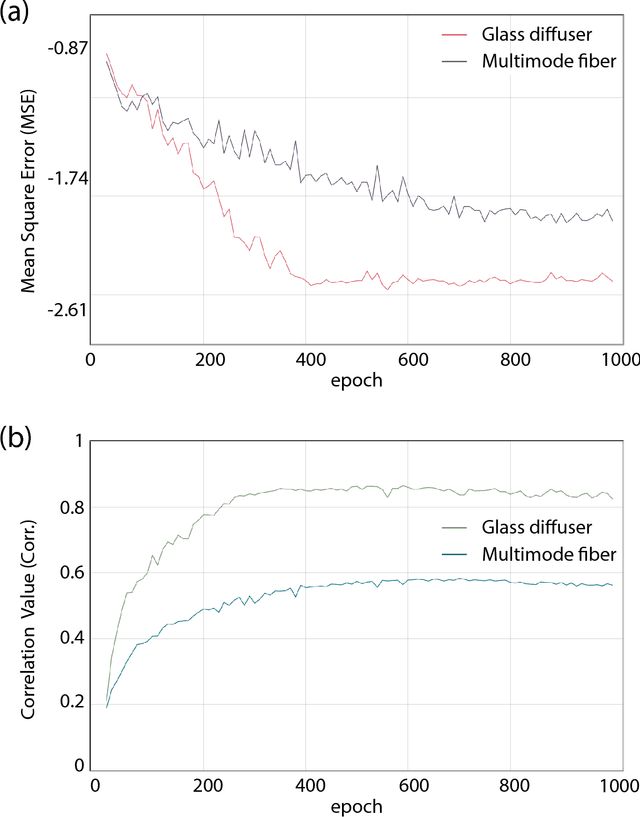
A well-trained deep neural network is shown to gain capability of simultaneously restoring two kinds of images, which are completely destroyed by two distinct scattering medias respectively. The network, based on the U-net architecture, can be trained by blended dataset of speckles-reference images pairs. We experimentally demonstrate the power of the network in reconstructing images which are strongly diffused by glass diffuser or multi-mode fiber. The learning model further shows good generalization ability to reconstruct images that are distinguished from the training dataset. Our work facilitates the study of optical transmission and expands machine learning's application in optics.