 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Binarization On Recurrent Neural Networks For Single-Channel Source Separation
Aug 23, 2019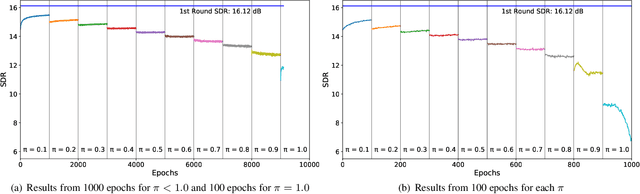
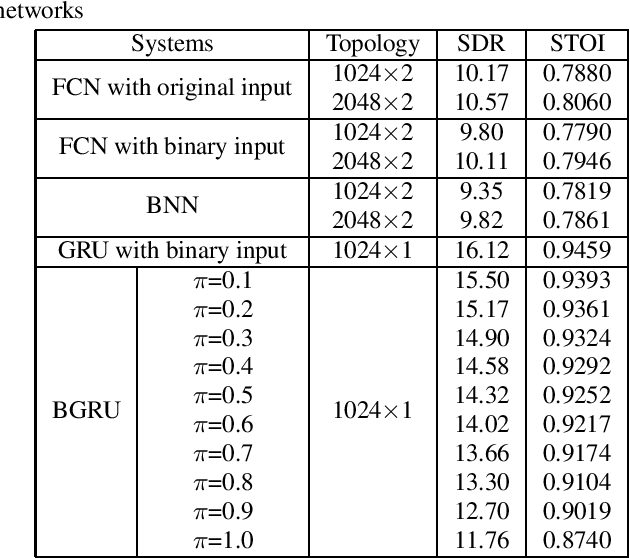
This paper proposes a Bitwise Gated Recurrent Unit (BGRU) network for the single-channel source separation task. Recurrent Neural Networks (RNN) require several sets of weights within its cells, which significantly increases the computational cost compared to the fully-connected networks. To mitigate this increased computation, we focus on the GRU cells and quantize the feedforward procedure with binarized values and bitwise operations. The BGRU network is trained in two stages. The real-valued weights are pretrained and transferred to the bitwise network, which are then incrementally binarized to minimize the potential loss that can occur from a sudden introduction of quantization. As the proposed binarization technique turns only a few randomly chosen parameters into their binary versions, it gives the network training procedure a chance to gently adapt to the partly quantized version of the network. It eventually achieves the full binarization by incrementally increasing the amount of binarization over the iterations. Our experiments show that the proposed BGRU method produces source separation results greater than that of a real-valued fully connected network, with 11-12 dB mean Signal-to-Distortion Ratio (SDR). A fully binarized BGRU still outperforms a Bitwise Neural Network (BNN) by 1-2 dB even with less number of layers.
Recognition of handwritten Roman Numerals using Tesseract open source OCR engine
Mar 30, 2010
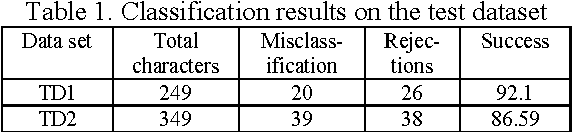
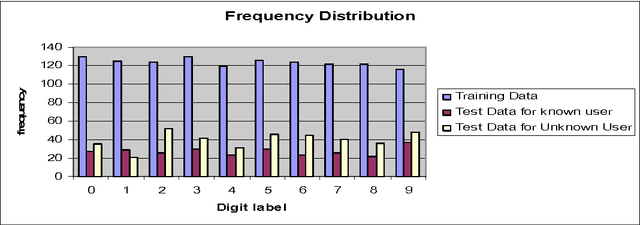
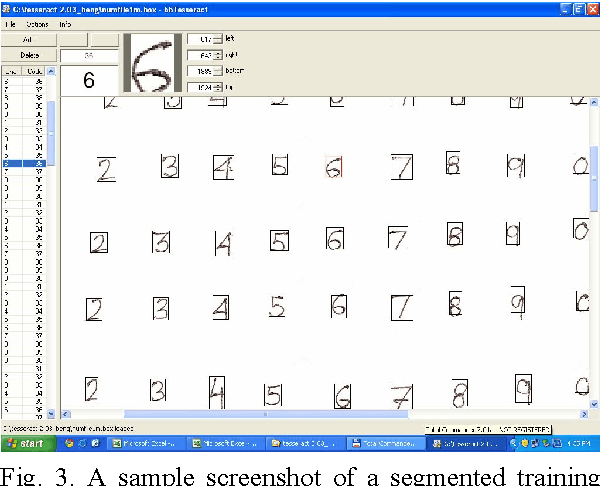
The objective of the paper is to recognize handwritten samples of Roman numerals using Tesseract open source Optical Character Recognition (OCR) engine. Tesseract is trained with data samples of different persons to generate one user-independent language model, representing the handwritten Roman digit-set. The system is trained with 1226 digit samples collected form the different users. The performance is tested on two different datasets, one consisting of samples collected from the known users (those who prepared the training data samples) and the other consisting of handwritten data samples of unknown users. The overall recognition accuracy is obtained as 92.1% and 86.59% on these test datasets respectively.