 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognition of handwritten Roman Numerals using Tesseract open source OCR engine
Mar 30, 2010
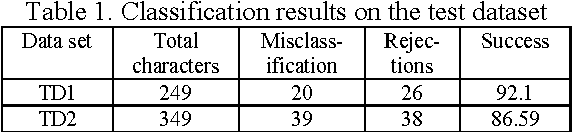
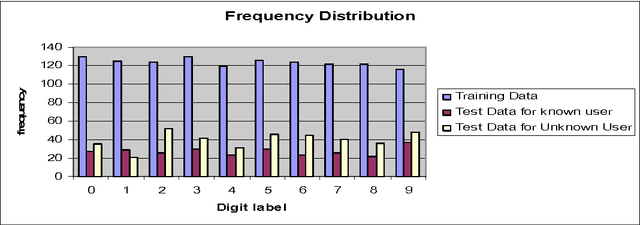
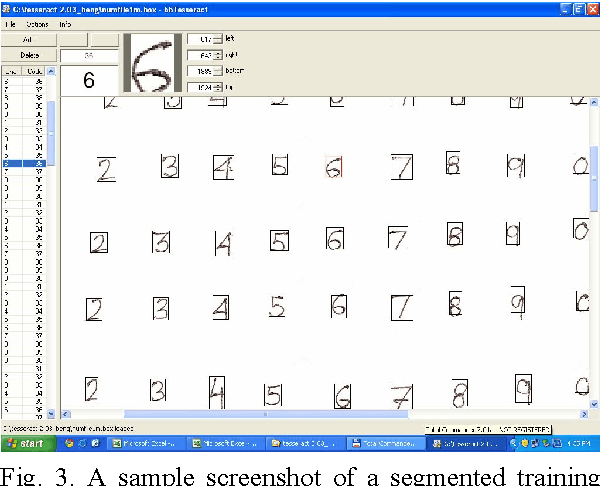
The objective of the paper is to recognize handwritten samples of Roman numerals using Tesseract open source Optical Character Recognition (OCR) engine. Tesseract is trained with data samples of different persons to generate one user-independent language model, representing the handwritten Roman digit-set. The system is trained with 1226 digit samples collected form the different users. The performance is tested on two different datasets, one consisting of samples collected from the known users (those who prepared the training data samples) and the other consisting of handwritten data samples of unknown users. The overall recognition accuracy is obtained as 92.1% and 86.59% on these test datasets respectively.
Development of a Multi-User Recognition Engine for Handwritten Bangla Basic Characters and Digits
Mar 30, 2010
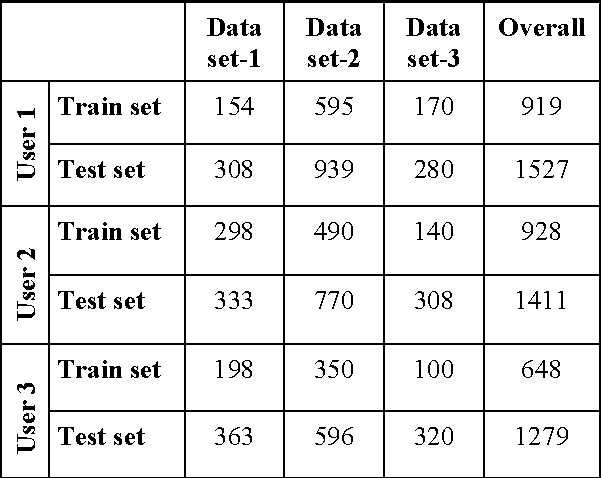

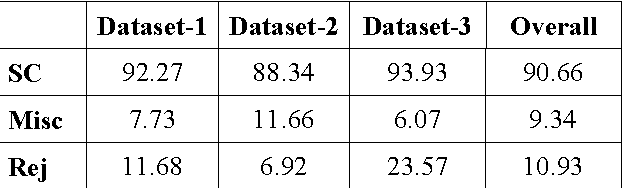
The objective of the paper is to recognize handwritten samples of basic Bangla characters using Tesseract open source Optical Character Recognition (OCR) engine under Apache License 2.0. Handwritten data samples containing isolated Bangla basic characters and digits were collected from different users. Tesseract is trained with user-specific data samples of document pages to generate separate user-models representing a unique language-set. Each such language-set recognizes isolated basic Bangla handwritten test samples collected from the designated users. On a three user model, the system is trained with 919, 928 and 648 isolated handwritten character and digit samples and the performance is tested on 1527, 14116 and 1279 character and digit samples, collected form the test datasets of the three users respectively. The user specific character/digit recognition accuracies were obtained as 90.66%, 91.66% and 96.87% respectively. The overall basic character-level and digit level accuracy of the system is observed as 92.15% and 97.37%. The system fails to segment 12.33% characters and 15.96% digits and also erroneously classifies 7.85% characters and 2.63% on the overall dataset.
Recognition of Handwritten Textual Annotations using Tesseract Open Source OCR Engine for information Just In Time (iJIT)
Mar 30, 2010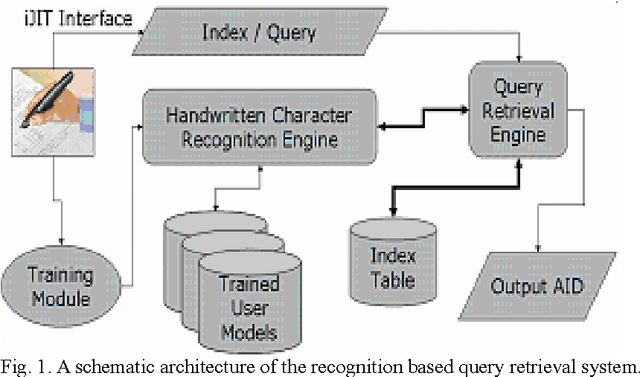
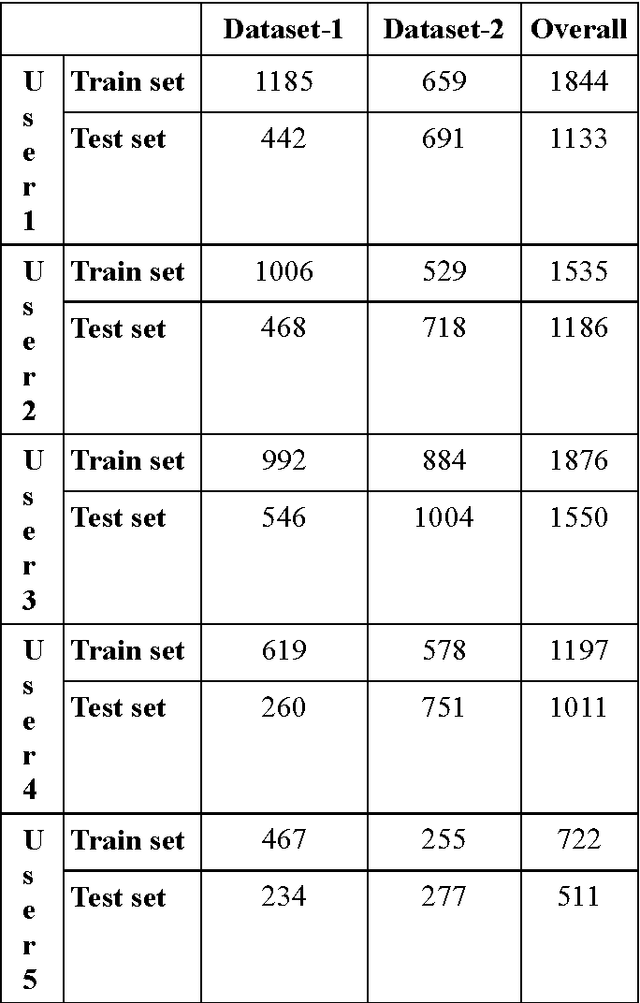
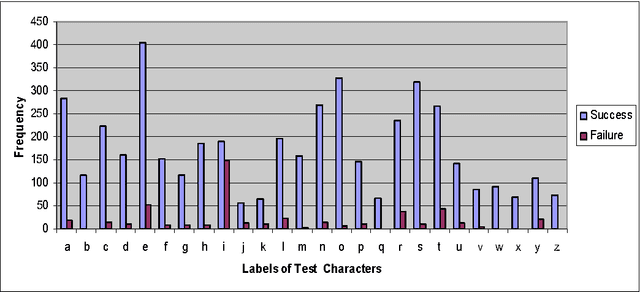
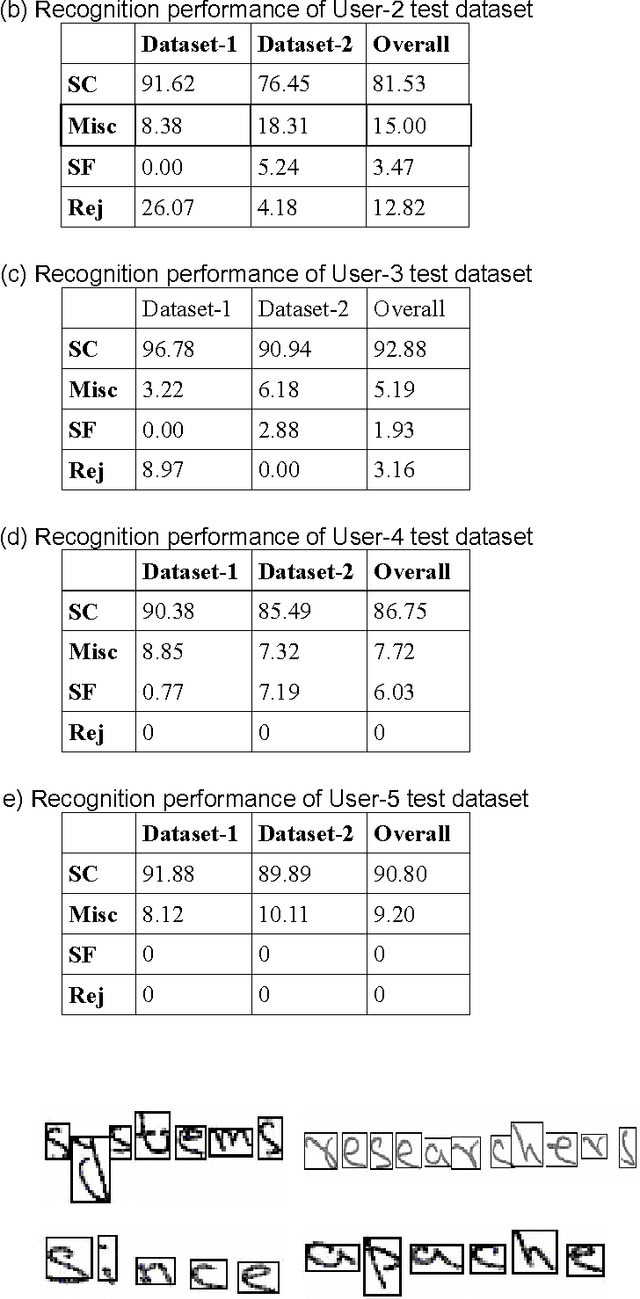
Objective of the current work is to develop an Optical Character Recognition (OCR) engine for information Just In Time (iJIT) system that can be used for recognition of handwritten textual annotations of lower case Roman script. Tesseract open source OCR engine under Apache License 2.0 is used to develop user-specific handwriting recognition models, viz., the language sets, for the said system, where each user is identified by a unique identification tag associated with the digital pen. To generate the language set for any user, Tesseract is trained with labeled handwritten data samples of isolated and free-flow texts of Roman script, collected exclusively from that user. The designed system is tested on five different language sets with free- flow handwritten annotations as test samples. The system could successfully segment and subsequently recognize 87.92%, 81.53%, 92.88%, 86.75% and 90.80% handwritten characters in the test samples of five different users.
Recognition of Handwritten Roman Script Using Tesseract Open source OCR Engine
Mar 30, 2010
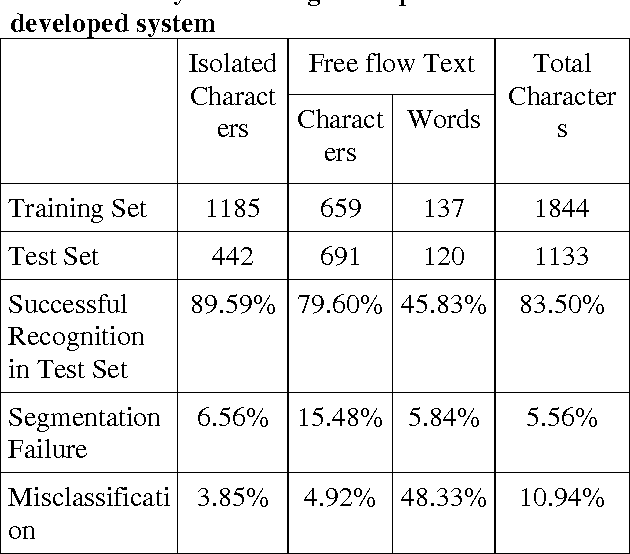
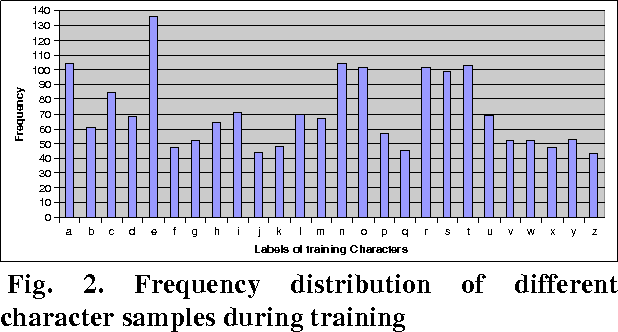
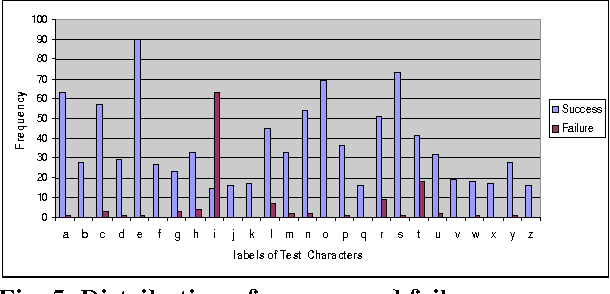
In the present work, we have used Tesseract 2.01 open source Optical Character Recognition (OCR) Engine under Apache License 2.0 for recognition of handwriting samples of lower case Roman script. Handwritten isolated and free-flow text samples were collected from multiple users. Tesseract is trained to recognize user-specific handwriting samples of both the categories of document pages. On a single user model, the system is trained with 1844 isolated handwritten characters and the performance is tested on 1133 characters, taken form the test set. The overall character-level accuracy of the system is observed as 83.5%. The system fails to segment 5.56% characters and erroneously classifies 10.94% characters.
Development of a multi-user handwriting recognition system using Tesseract open source OCR engine
Mar 30, 2010
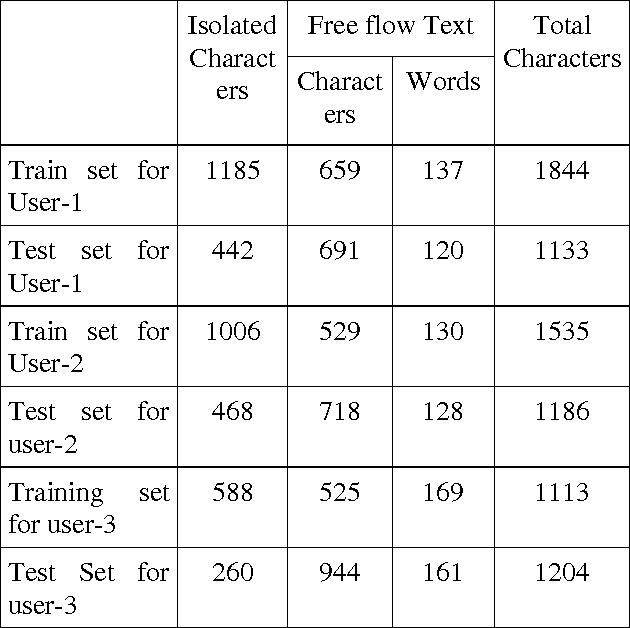
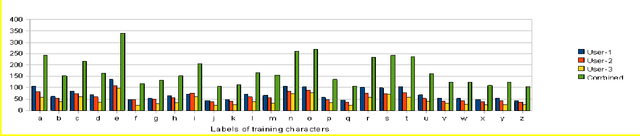

The objective of the paper is to recognize handwritten samples of lower case Roman script using Tesseract open source Optical Character Recognition (OCR) engine under Apache License 2.0. Handwritten data samples containing isolated and free-flow text were collected from different users. Tesseract is trained with user-specific data samples of both the categories of document pages to generate separate user-models representing a unique language-set. Each such language-set recognizes isolated and free-flow handwritten test samples collected from the designated user. On a three user model, the system is trained with 1844, 1535 and 1113 isolated handwritten character samples collected from three different users and the performance is tested on 1133, 1186 and 1204 character samples, collected form the test sets of the three users respectively. The user specific character level accuracies were obtained as 87.92%, 81.53% and 65.71% respectively. The overall character-level accuracy of the system is observed as 78.39%. The system fails to segment 10.96% characters and erroneously classifies 10.65% characters on the overall dataset.