 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Semantic Analysis with Document-Level Cross-Task Coherence Rewards
Oct 12, 2020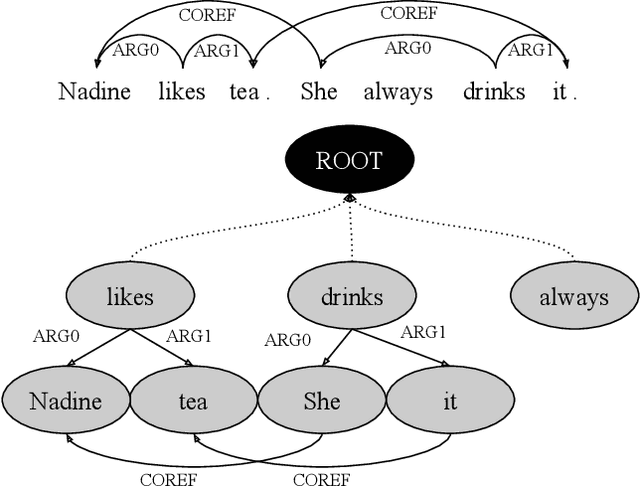
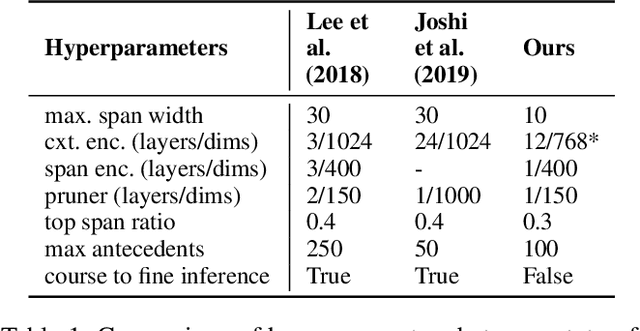
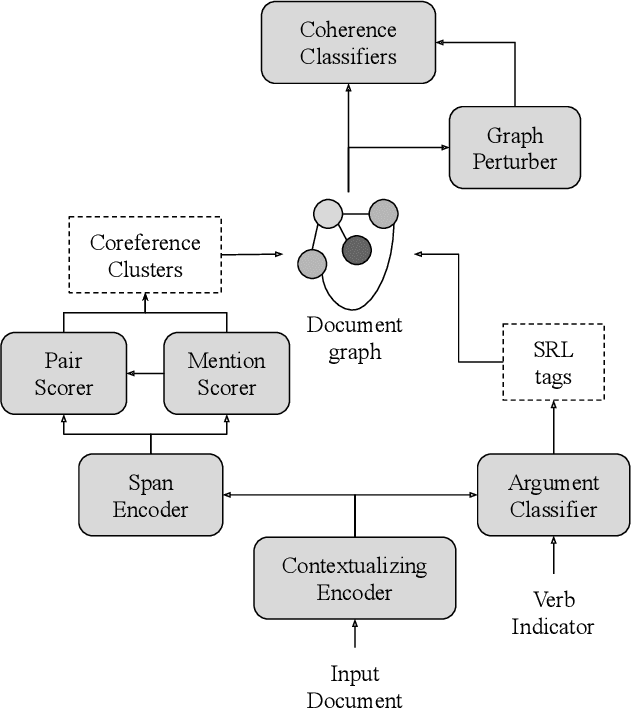
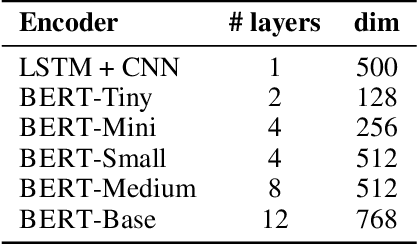
Coreference resolution and semantic role labeling are NLP tasks that capture different aspects of semantics, indicating respectively, which expressions refer to the same entity, and what semantic roles expressions serve in the sentence. However, they are often closely interdependent, and both generally necessitate natural language understanding. Do they form a coherent abstract representation of documents? We present a neural network architecture for joint coreference resolution and semantic role labeling for English, and train graph neural networks to model the 'coherence' of the combined shallow semantic graph. Using the resulting coherence score as a reward for our joint semantic analyzer, we use reinforcement learning to encourage global coherence over the document and between semantic annotations. This leads to improvements on both tasks in multiple datasets from different domains, and across a range of encoders of different expressivity, calling, we believe, for a more holistic approach to semantics in NLP.
The Sensitivity of Language Models and Humans to Winograd Schema Perturbations
May 07, 2020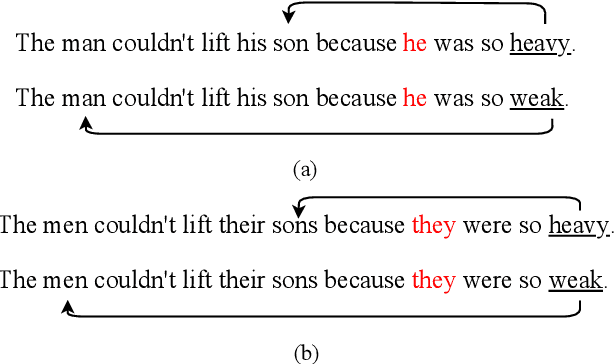

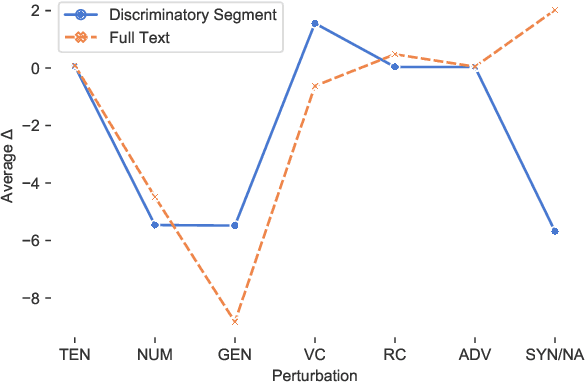
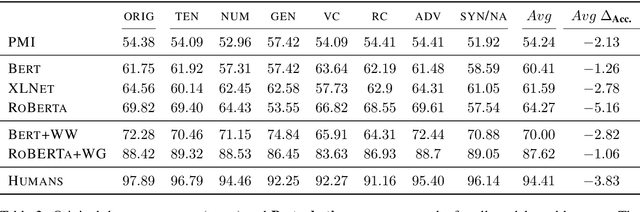
Large-scale pretrained language models are the major driving force behind recent improvements in performance on the Winograd Schema Challenge, a widely employed test of common sense reasoning ability. We show, however, with a new diagnostic dataset, that these models are sensitive to linguistic perturbations of the Winograd examples that minimally affect human understanding. Our results highlight interesting differences between humans and language models: language models are more sensitive to number or gender alternations and synonym replacements than humans, and humans are more stable and consistent in their predictions, maintain a much higher absolute performance, and perform better on non-associative instances than associative ones. Overall, humans are correct more often than out-of-the-box models, and the models are sometimes right for the wrong reasons. Finally, we show that fine-tuning on a large, task-specific dataset can offer a solution to these issues.
Do Neural Language Models Show Preferences for Syntactic Formalisms?
Apr 29, 2020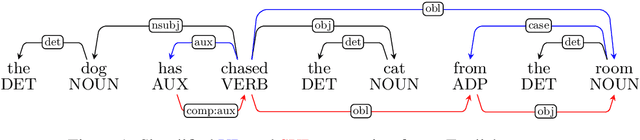
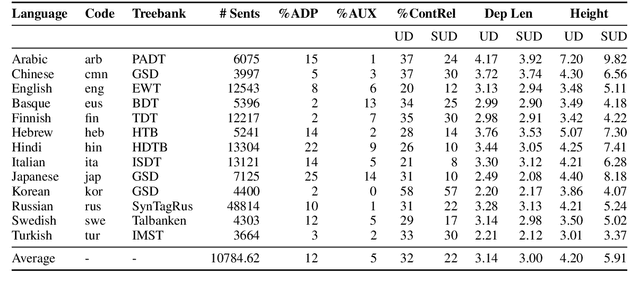

Recent work on the interpretability of deep neural language models has concluded that many properties of natural language syntax are encoded in their representational spaces. However, such studies often suffer from limited scope by focusing on a single language and a single linguistic formalism. In this study, we aim to investigate the extent to which the semblance of syntactic structure captured by language models adheres to a surface-syntactic or deep syntactic style of analysis, and whether the patterns are consistent across different languages. We apply a probe for extracting directed dependency trees to BERT and ELMo models trained on 13 different languages, probing for two different syntactic annotation styles: Universal Dependencies (UD), prioritizing deep syntactic relations, and Surface-Syntactic Universal Dependencies (SUD), focusing on surface structure. We find that both models exhibit a preference for UD over SUD - with interesting variations across languages and layers - and that the strength of this preference is correlated with differences in tree shape.
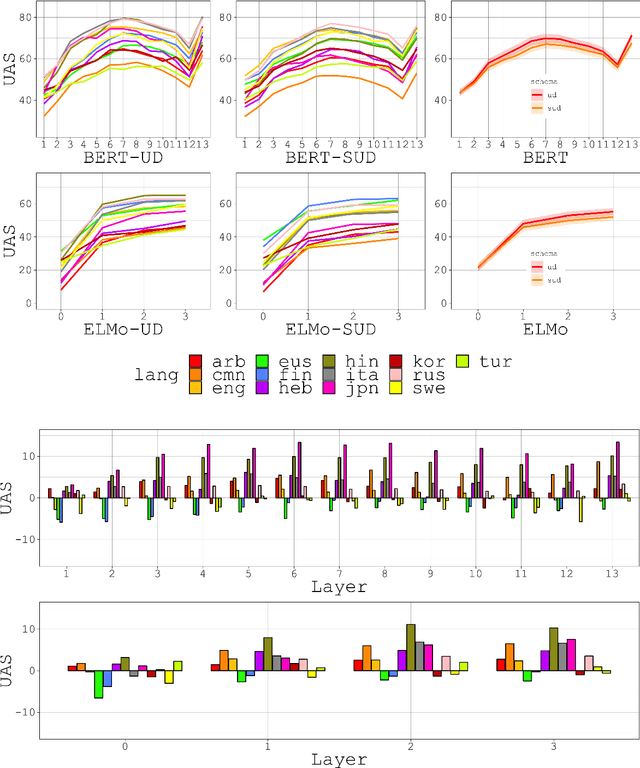
Compositional Generalization in Image Captioning
Sep 16, 2019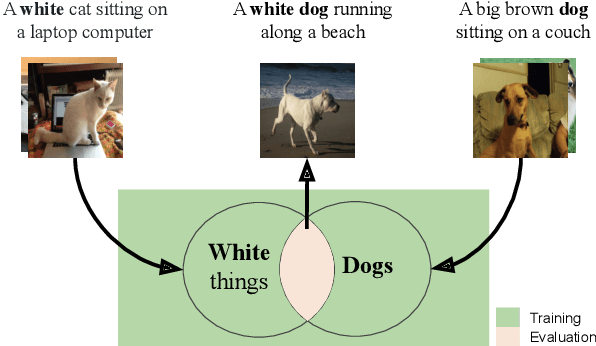

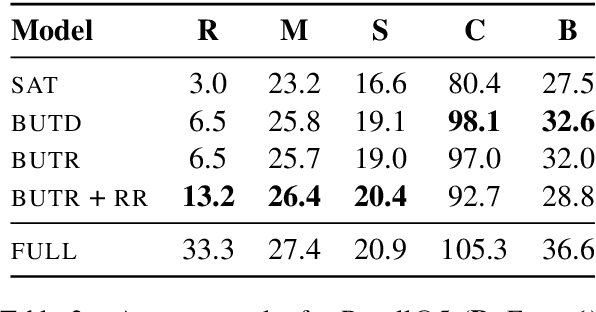
Image captioning models are usually evaluated on their ability to describe a held-out set of images, not on their ability to generalize to unseen concepts. We study the problem of compositional generalization, which measures how well a model composes unseen combinations of concepts when describing images. State-of-the-art image captioning models show poor generalization performance on this task. We propose a multi-task model to address the poor performance, that combines caption generation and image--sentence ranking, and uses a decoding mechanism that re-ranks the captions according their similarity to the image. This model is substantially better at generalizing to unseen combinations of concepts compared to state-of-the-art captioning models.
Higher-order Comparisons of Sentence Encoder Representations
Sep 05, 2019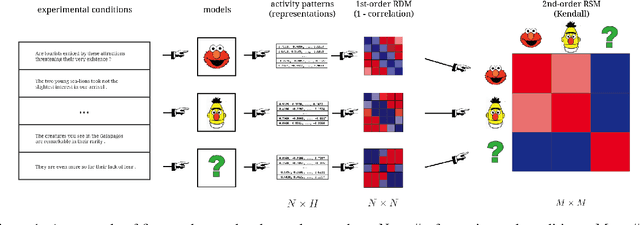
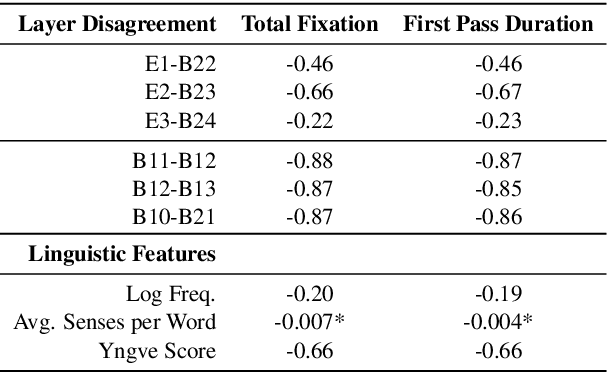
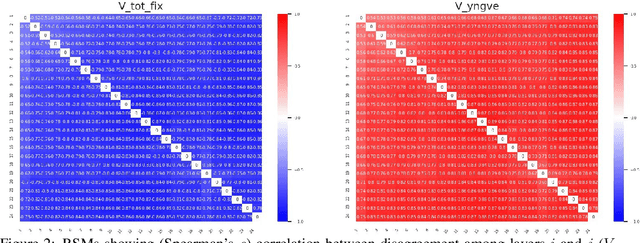
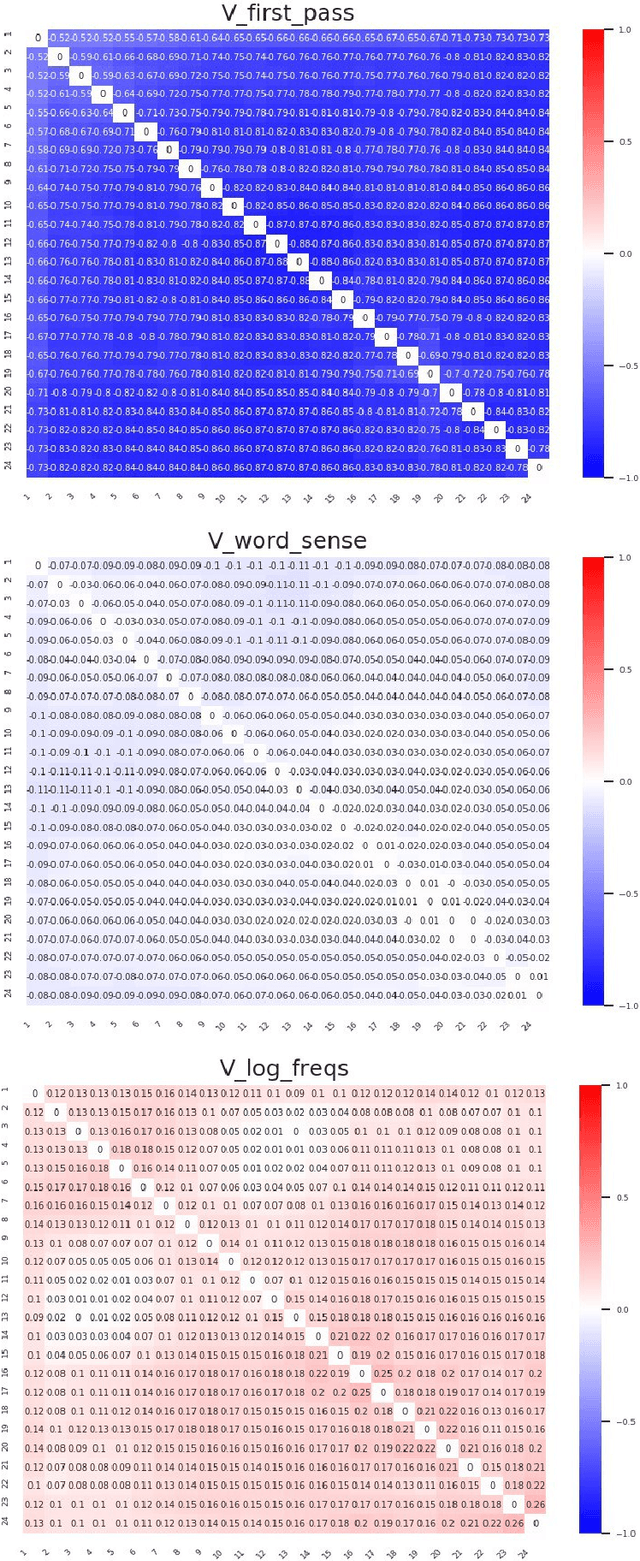
Representational Similarity Analysis (RSA) is a technique developed by neuroscientists for comparing activity patterns of different measurement modalities (e.g., fMRI, electrophysiology, behavior). As a framework, RSA has several advantages over existing approaches to interpretation of language encoders based on probing or diagnostic classification: namely, it does not require large training samples, is not prone to overfitting, and it enables a more transparent comparison between the representational geometries of different models and modalities. We demonstrate the utility of RSA by establishing a previously unknown correspondence between widely-employed pretrained language encoders and human processing difficulty via eye-tracking data, showcasing its potential in the interpretability toolbox for neural models
X-WikiRE: A Large, Multilingual Resource for Relation Extraction as Machine Comprehension
Aug 15, 2019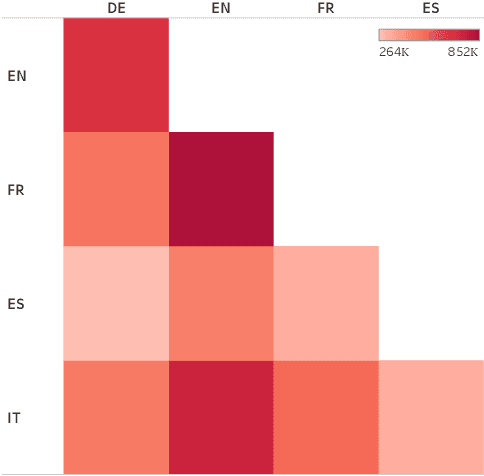

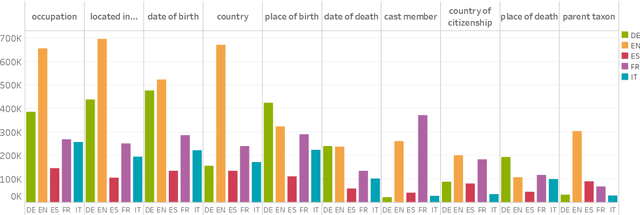
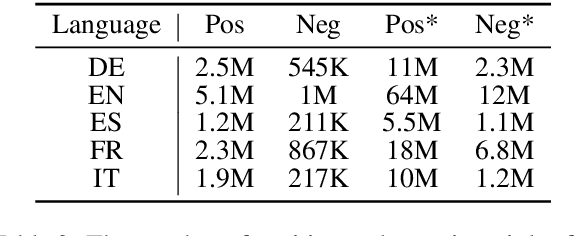
Although the vast majority of knowledge bases KBs are heavily biased towards English, Wikipedias do cover very different topics in different languages. Exploiting this, we introduce a new multilingual dataset (X-WikiRE), framing relation extraction as a multilingual machine reading problem. We show that by leveraging this resource it is possible to robustly transfer models cross-lingually and that multilingual support significantly improves (zero-shot) relation extraction, enabling the population of low-resourced KBs from their well-populated counterparts.
Better, Faster, Stronger Sequence Tagging Constituent Parsers
Feb 28, 2019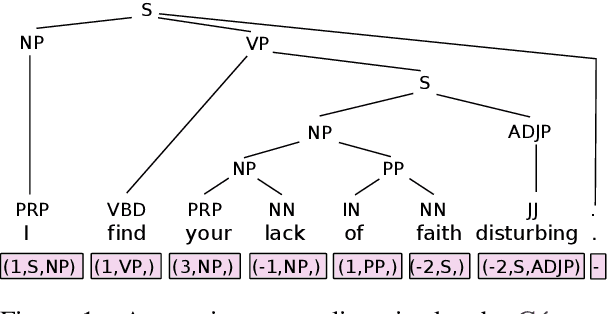
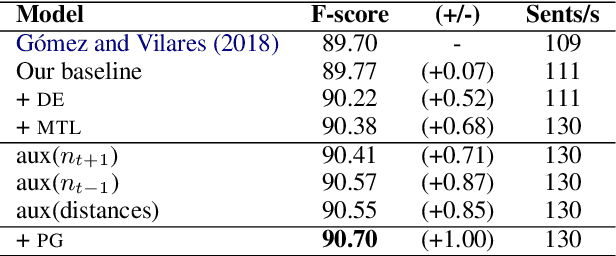
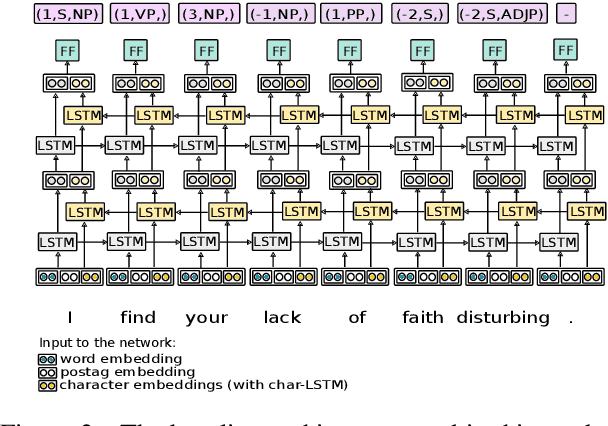

Sequence tagging models for constituent parsing are faster, but less accurate than other types of parsers. In this work, we address the following weaknesses of such constituent parsers: (a) high error rates around closing brackets of long constituents, (b) large label sets, leading to sparsity, and (c) error propagation arising from greedy decoding. To effectively close brackets, we train a model that learns to switch between tagging schemes. To reduce sparsity, we decompose the label set and use multi-task learning to jointly learn to predict sublabels. Finally, we mitigate issues from greedy decoding through auxiliary losses and sentence-level fine-tuning with policy gradient. Combining these techniques, we clearly surpass the performance of sequence tagging constituent parsers on the English and Chinese Penn Treebanks, and reduce their parsing time even further. On the SPMRL datasets, we observe even greater improvements across the board, including a new state of the art on Basque, Hebrew, Polish and Swedish.
What can we learn from Semantic Tagging?
Aug 29, 2018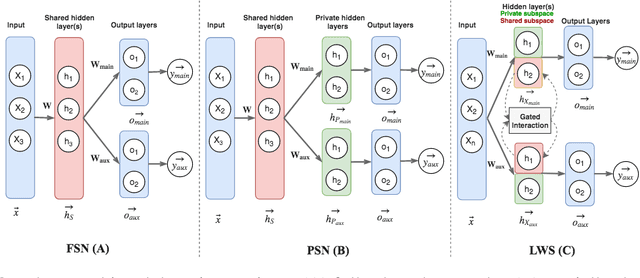
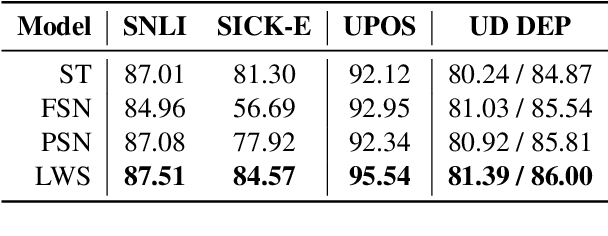
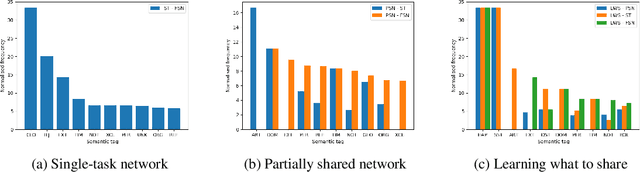
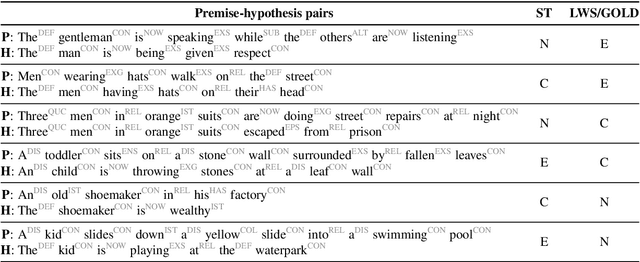
We investigate the effects of multi-task learning using the recently introduced task of semantic tagging. We employ semantic tagging as an auxiliary task for three different NLP tasks: part-of-speech tagging, Universal Dependency parsing, and Natural Language Inference. We compare full neural network sharing, partial neural network sharing, and what we term the learning what to share setting where negative transfer between tasks is less likely. Our findings show considerable improvements for all tasks, particularly in the learning what to share setting, which shows consistent gains across all tasks.