 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Diversity of Bootstrapped DQN via Noisy Priors
Mar 02, 2022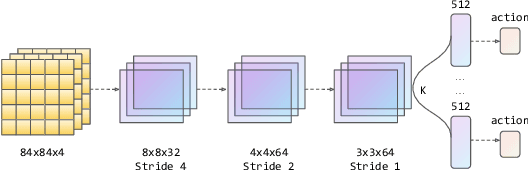
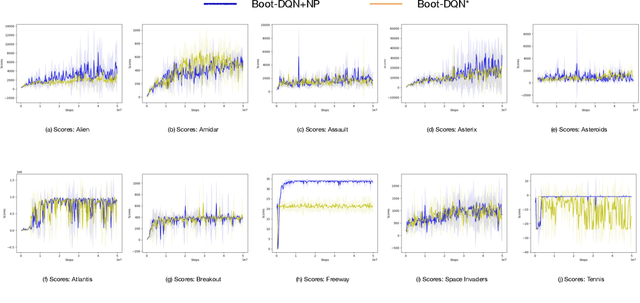
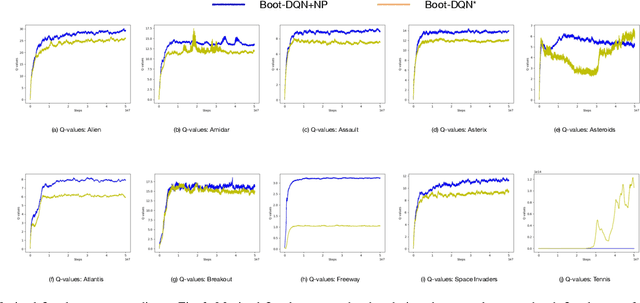

Q-learning is one of the most well-known Reinforcement Learning algorithms. There have been tremendous efforts to develop this algorithm using neural networks. Bootstrapped Deep Q-Learning Network is amongst one of them. It utilizes multiple neural network heads to introduce diversity into Q-learning. Diversity can sometimes be viewed as the amount of reasonable moves an agent can take at a given state, analogous to the definition of the exploration ratio in RL. Thus, the performance of Bootstrapped Deep Q-Learning Network is deeply connected with the level of diversity within the algorithm. In the original research, it was pointed out that a random prior could improve the performance of the model. In this article, we further explore the possibility of treating priors as a special type of noise and sample priors from a Gaussian distribution to introduce more diversity into this algorithm. We conduct our experiment on the Atari benchmark and compare our algorithm to both the original and other related algorithms. The results show that our modification of the Bootstrapped Deep Q-Learning algorithm achieves significantly higher evaluation scores across different types of Atari games. Thus, we conclude that noisy priors can improve Bootstrapped Deep Q-Learning's performance by ensuring the integrity of diversities.
Unlocking the potential of deep learning for marine ecology: overview, applications, and outlook
Sep 29, 2021

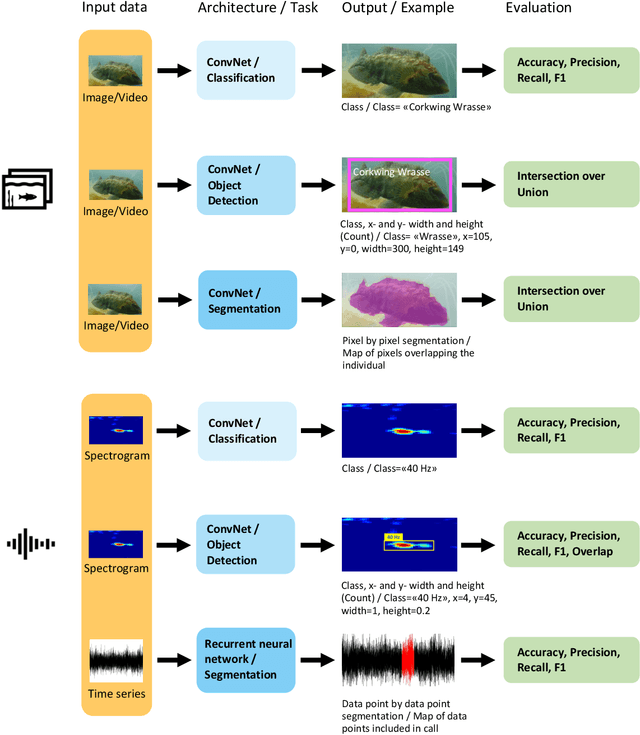
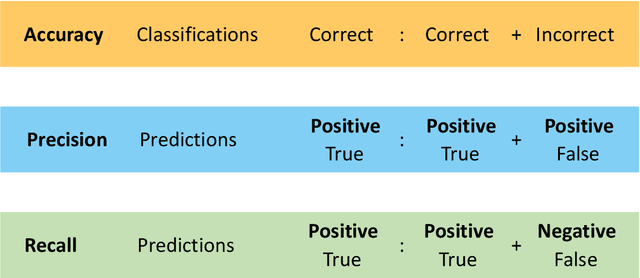
The deep learning revolution is touching all scientific disciplines and corners of our lives as a means of harnessing the power of big data. Marine ecology is no exception. These new methods provide analysis of data from sensors, cameras, and acoustic recorders, even in real time, in ways that are reproducible and rapid. Off-the-shelf algorithms can find, count, and classify species from digital images or video and detect cryptic patterns in noisy data. Using these opportunities requires collaboration across ecological and data science disciplines, which can be challenging to initiate. To facilitate these collaborations and promote the use of deep learning towards ecosystem-based management of the sea, this paper aims to bridge the gap between marine ecologists and computer scientists. We provide insight into popular deep learning approaches for ecological data analysis in plain language, focusing on the techniques of supervised learning with deep neural networks, and illustrate challenges and opportunities through established and emerging applications of deep learning to marine ecology. We use established and future-looking case studies on plankton, fishes, marine mammals, pollution, and nutrient cycling that involve object detection, classification, tracking, and segmentation of visualized data. We conclude with a broad outlook of the field's opportunities and challenges, including potential technological advances and issues with managing complex data sets.
Self-transfer learning via patches: A prostate cancer triage approach based on bi-parametric MRI
Jul 22, 2021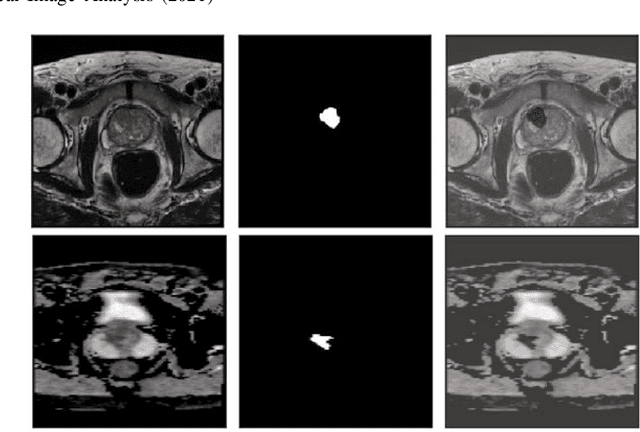
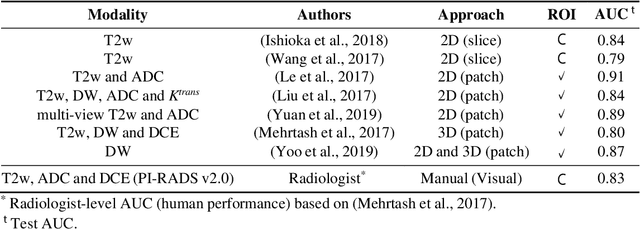
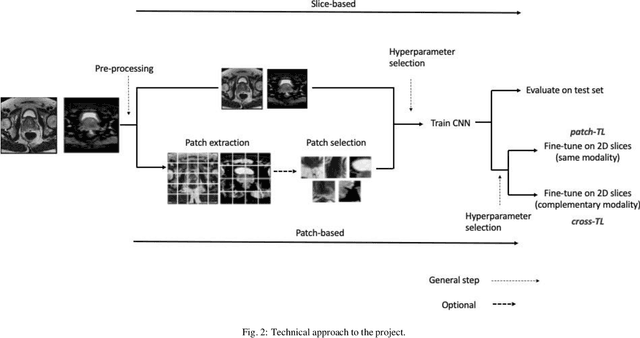
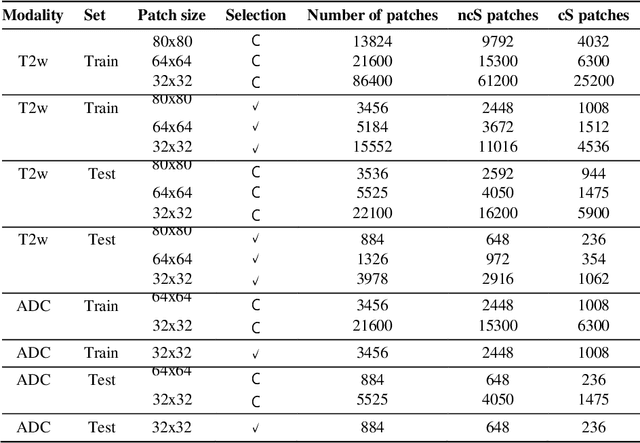
Prostate cancer (PCa) is the second most common cancer diagnosed among men worldwide. The current PCa diagnostic pathway comes at the cost of substantial overdiagnosis, leading to unnecessary treatment and further testing. Bi-parametric magnetic resonance imaging (bp-MRI) based on apparent diffusion coefficient maps (ADC) and T2-weighted (T2w) sequences has been proposed as a triage test to differentiate between clinically significant (cS) and non-clinically significant (ncS) prostate lesions. However, analysis of the sequences relies on expertise, requires specialized training, and suffers from inter-observer variability. Deep learning (DL) techniques hold promise in tasks such as classification and detection. Nevertheless, they rely on large amounts of annotated data which is not common in the medical field. In order to palliate such issues, existing works rely on transfer learning (TL) and ImageNet pre-training, which has been proven to be sub-optimal for the medical imaging domain. In this paper, we present a patch-based pre-training strategy to distinguish between cS and ncS lesions which exploit the region of interest (ROI) of the patched source domain to efficiently train a classifier in the full-slice target domain which does not require annotations by making use of transfer learning (TL). We provide a comprehensive comparison between several CNNs architectures and different settings which are presented as a baseline. Moreover, we explore cross-domain TL which exploits both MRI modalities and improves single modality results. Finally, we show how our approaches outperform the standard approaches by a considerable margin
Expert Q-learning: Deep Q-learning With State Values From Expert Examples
Jun 29, 2021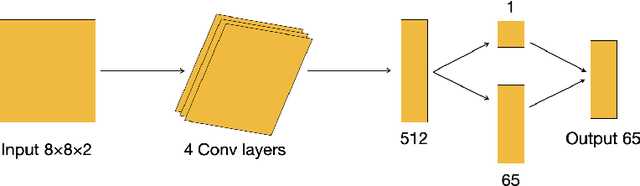
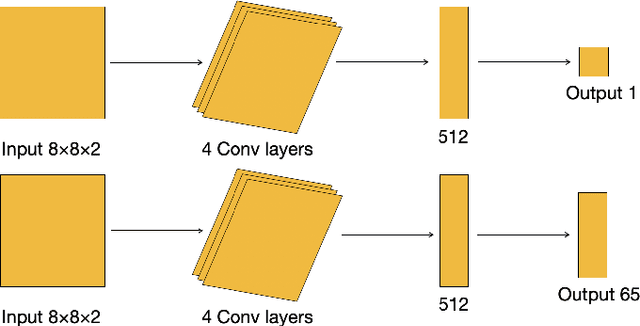
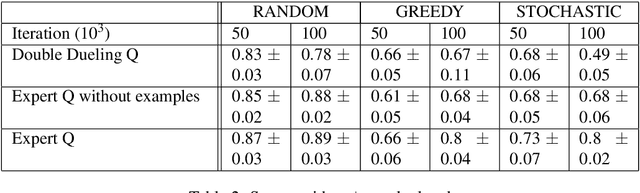
We propose a novel algorithm named Expert Q-learning. Expert Q-learning was inspired by Dueling Q-learning and aimed at incorporating the ideas from semi-supervised learning into reinforcement learning through splitting Q-values into state values and action advantages. Different from Generative Adversarial Imitation Learning and Deep Q-Learning from Demonstrations, the offline expert we have used only predicts the value of a state from {-1, 0, 1}, indicating whether this is a bad, neutral or good state. An expert network was designed in addition to the Q-network, which updates each time following the regular offline minibatch update whenever the expert example buffer is not empty. The Q-network plays the role of the advantage function only during the update. Our algorithm also keeps asynchronous copies of the Q-network and expert network, predicting the target values using the same manner as of Double Q-learning. We compared on the game of Othello our algorithm with the state-of-the-art Q-learning algorithm, which was a combination of Double Q-learning and Dueling Q-learning. The results showed that Expert Q-learning was indeed useful and more resistant to the overestimation bias of Q-learning. The baseline Q-learning algorithm exhibited unstable and suboptimal behavior, especially when playing against a stochastic player, whereas Expert Q-learning demonstrated more robust performance with higher scores. Expert Q-learning without using examples has also gained better results than the baseline algorithm when trained and tested against a fixed player. On the other hand, Expert Q-learning without examples cannot win against the baseline Q-learning algorithm in direct game competitions despite the fact that it has also shown the strength of reducing the overestimation bias.
Distributed Word Representation in Tsetlin Machine
Apr 14, 2021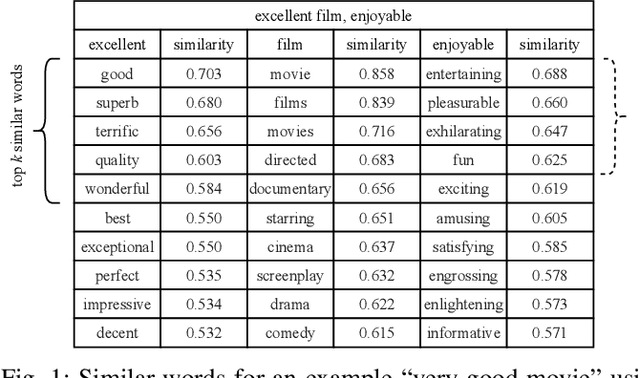
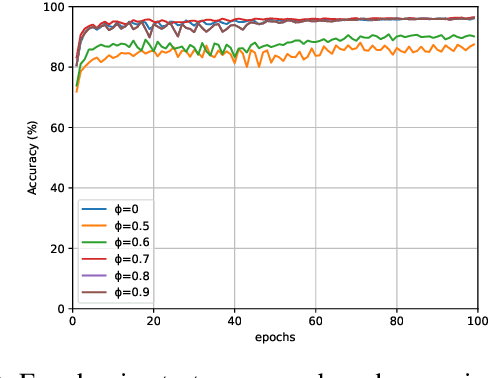
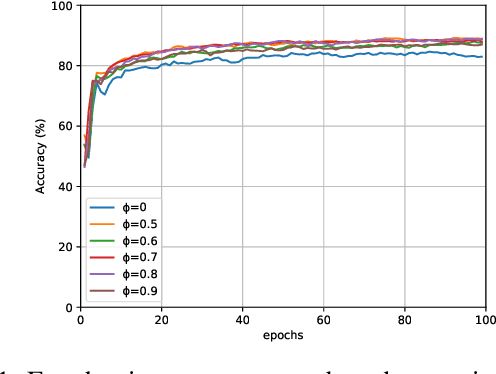
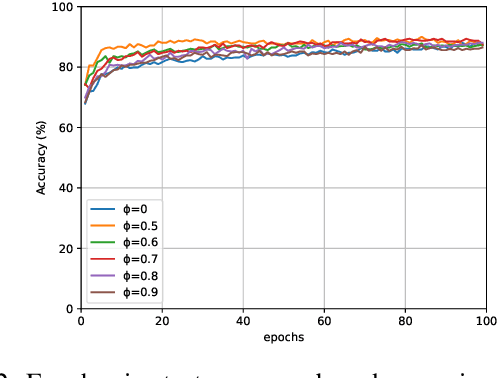
Tsetlin Machine (TM) is an interpretable pattern recognition algorithm based on propositional logic. The algorithm has demonstrated competitive performance in many Natural Language Processing (NLP) tasks, including sentiment analysis, text classification, and Word Sense Disambiguation (WSD). To obtain human-level interpretability, legacy TM employs Boolean input features such as bag-of-words (BOW). However, the BOW representation makes it difficult to use any pre-trained information, for instance, word2vec and GloVe word representations. This restriction has constrained the performance of TM compared to deep neural networks (DNNs) in NLP. To reduce the performance gap, in this paper, we propose a novel way of using pre-trained word representations for TM. The approach significantly enhances the TM performance and maintains interpretability at the same time. We achieve this by extracting semantically related words from pre-trained word representations as input features to the TM. Our experiments show that the accuracy of the proposed approach is significantly higher than the previous BOW-based TM, reaching the level of DNN-based models.
Improving prostate whole gland segmentation in t2-weighted MRI with synthetically generated data
Mar 27, 2021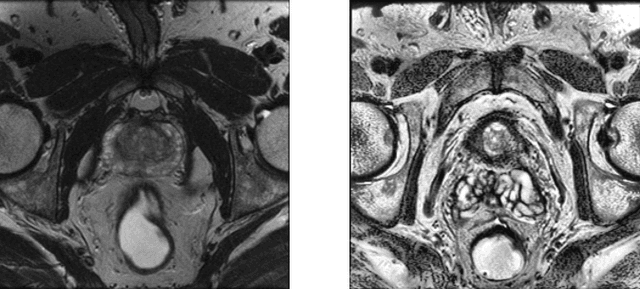
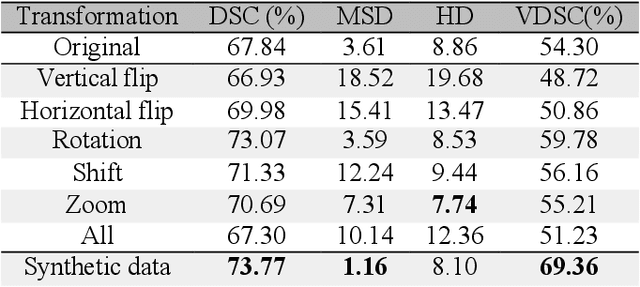
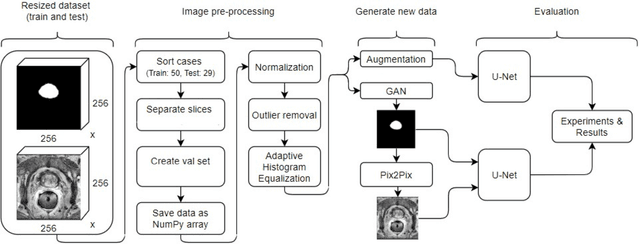
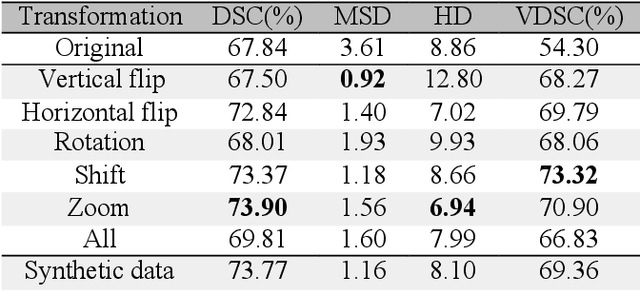
Whole gland (WG) segmentation of the prostate plays a crucial role in detection, staging and treatment planning of prostate cancer (PCa). Despite promise shown by deep learning (DL) methods, they rely on the availability of a considerable amount of annotated data. Augmentation techniques such as translation and rotation of images present an alternative to increase data availability. Nevertheless, the amount of information provided by the transformed data is limited due to the correlation between the generated data and the original. Based on the recent success of generative adversarial networks (GAN) in producing synthetic images for other domains as well as in the medical domain, we present a pipeline to generate WG segmentation masks and synthesize T2-weighted MRI of the prostate based on a publicly available multi-center dataset. Following, we use the generated data as a form of data augmentation. Results show an improvement in the quality of the WG segmentation when compared to standard augmentation techniques.
A Relational Tsetlin Machine with Applications to Natural Language Understanding
Feb 22, 2021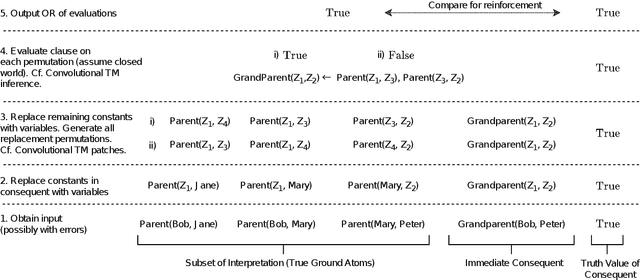


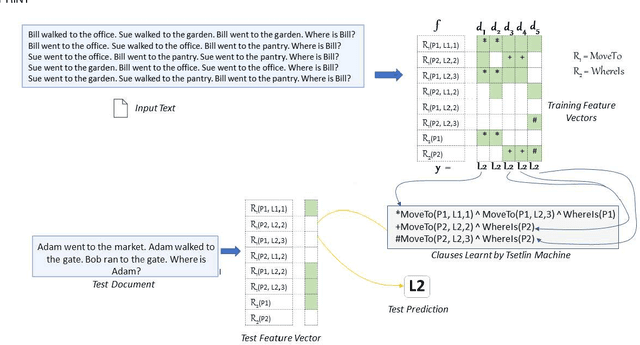
TMs are a pattern recognition approach that uses finite state machines for learning and propositional logic to represent patterns. In addition to being natively interpretable, they have provided competitive accuracy for various tasks. In this paper, we increase the computing power of TMs by proposing a first-order logic-based framework with Herbrand semantics. The resulting TM is relational and can take advantage of logical structures appearing in natural language, to learn rules that represent how actions and consequences are related in the real world. The outcome is a logic program of Horn clauses, bringing in a structured view of unstructured data. In closed-domain question-answering, the first-order representation produces 10x more compact KBs, along with an increase in answering accuracy from 94.83% to 99.48%. The approach is further robust towards erroneous, missing, and superfluous information, distilling the aspects of a text that are important for real-world understanding.
Massively Parallel and Asynchronous Tsetlin Machine Architecture Supporting Almost Constant-Time Scaling
Sep 13, 2020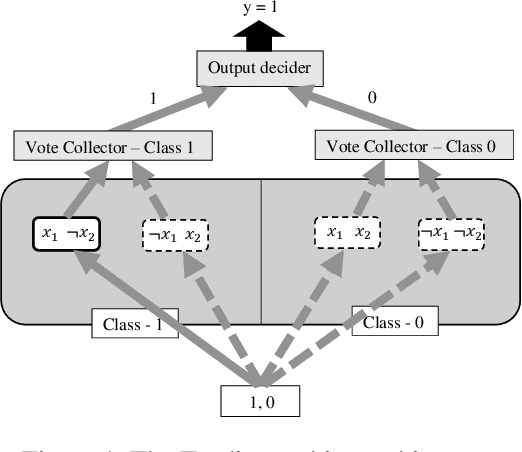
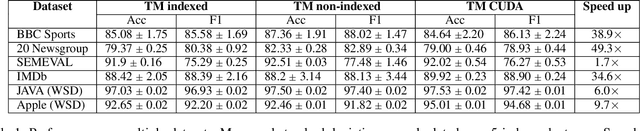
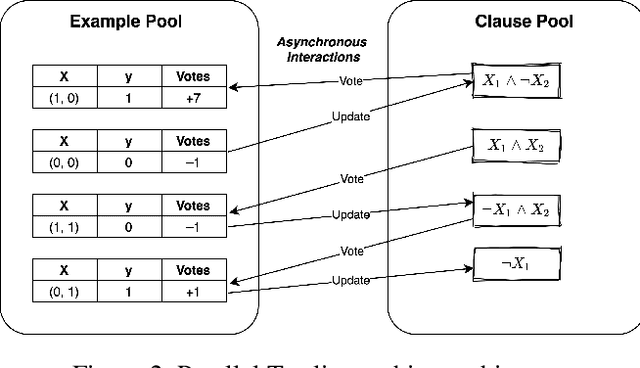
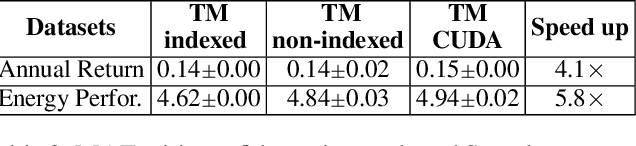
Using logical clauses to represent patterns, Tsetlin machines (TMs) have recently obtained competitive performance in terms of accuracy, memory footprint, energy, and learning speed on several benchmarks. A team of Tsetlin automata (TAs) composes each clause, thus driving the entire learning process. These are rewarded/penalized according to three local rules that optimize global behaviour. Each clause votes for or against a particular class, with classification resolved using a majority vote. In the parallel and asynchronous architecture that we propose here, every clause runs in its own thread for massive parallelism. For each training example, we keep track of the class votes obtained from the clauses in local voting tallies. The local voting tallies allow us to detach the processing of each clause from the rest of the clauses, supporting decentralized learning. Thus, rather than processing training examples one-by-one as in the original TM, the clauses access the training examples simultaneously, updating themselves and the local voting tallies in parallel. There is no synchronization among the clause threads, apart from atomic adds to the local voting tallies. Operating asynchronously, each team of TA will most of the time operate on partially calculated or outdated voting tallies. However, across diverse learning tasks, it turns out that our decentralized TM learning algorithm copes well with working on outdated data, resulting in no significant loss in learning accuracy. Further, we show that the approach provides up to 50 times faster learning. Finally, learning time is almost constant for reasonable clause amounts. For sufficiently large clause numbers, computation time increases approximately proportionally. Our parallel and asynchronous architecture thus allows processing of more massive datasets and operating with more clauses for higher accuracy.
On the Convergence of Tsetlin Machines for the IDENTITY- and NOT Operators
Jul 28, 2020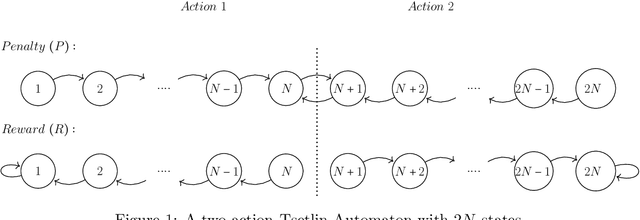
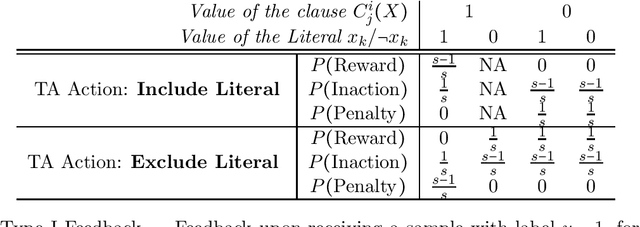
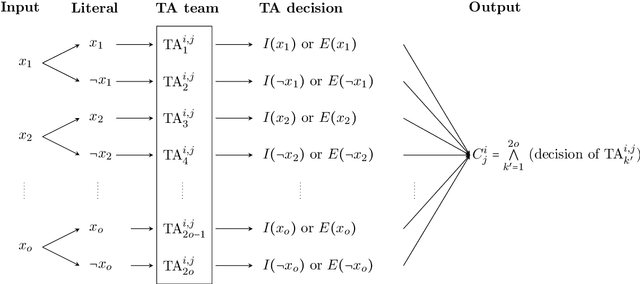

The Tsetlin Machine (TM) is a recent machine learning algorithm with several distinct properties, such as interpretability, simplicity, and hardware-friendliness. Although numerous empirical evaluations report on its performance, the mathematical analysis of its convergence is still open. In this article, we analyze the convergence of the TM with only one clause involved for classification. More specifically, we examine two basic logical operators, namely, the IDENTITY- and NOT operators. Our analysis reveals that the TM, with just one clause, can converge correctly to the intended logical operator, learning from training data over an infinite time horizon. Besides, it can capture arbitrarily rare patterns and select the most accurate one when two candidate patterns are incompatible, by configuring a granularity parameter. The analysis of the convergence of the two basic operators lays the foundation for analyzing other logical operators. These analyses altogether, from a mathematical perspective, provide new insights on why TMs have obtained state-of-the-art performance on several pattern recognition problems.
A Novel Multi-Step Finite-State Automaton for Arbitrarily Deterministic Tsetlin Machine Learning
Jul 04, 2020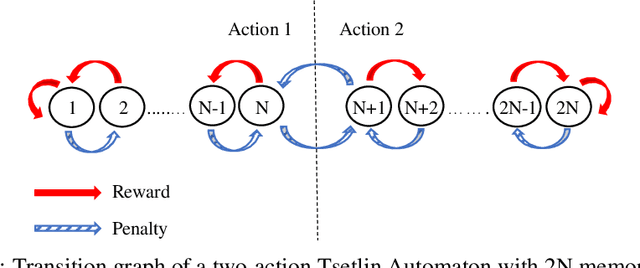
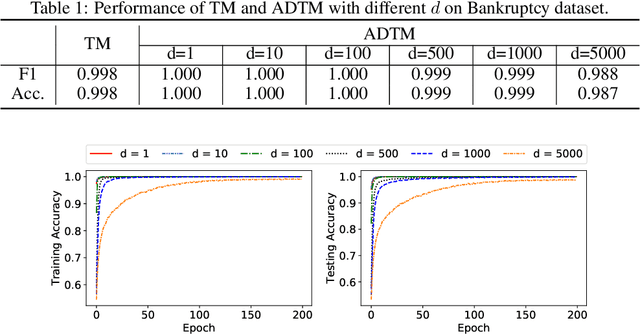
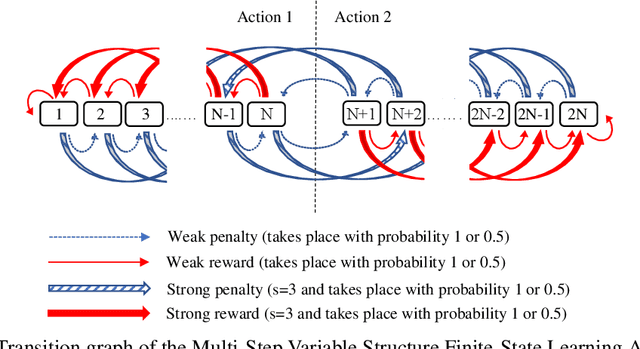
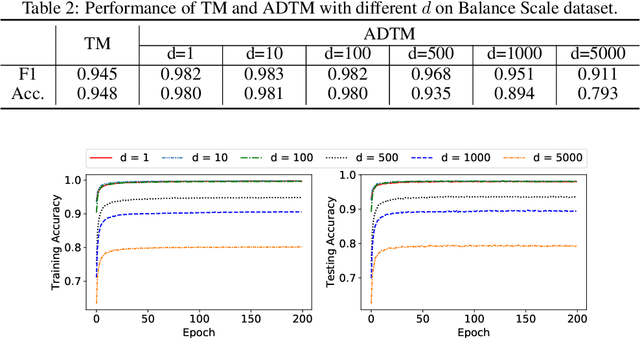
Due to the high energy consumption and scalability challenges of deep learning, there is a critical need to shift research focus towards dealing with energy consumption constraints. Tsetlin Machines (TMs) are a recent approach to machine learning that has demonstrated significantly reduced energy usage compared to neural networks alike, while performing competitively accuracy-wise on several benchmarks. However, TMs rely heavily on energy-costly random number generation to stochastically guide a team of Tsetlin Automata to a Nash Equilibrium of the TM game. In this paper, we propose a novel finite-state learning automaton that can replace the Tsetlin Automata in TM learning, for increased determinism. The new automaton uses multi-step deterministic state jumps to reinforce sub-patterns. Simultaneously, flipping a coin to skip every $d$'th state update ensures diversification by randomization. The $d$-parameter thus allows the degree of randomization to be finely controlled. E.g., $d=1$ makes every update random and $d=\infty$ makes the automaton completely deterministic. Our empirical results show that, overall, only substantial degrees of determinism reduces accuracy. Energy-wise, random number generation constitutes switching energy consumption of the TM, saving up to 11 mW power for larger datasets with high $d$ values. We can thus use the new $d$-parameter to trade off accuracy against energy consumption, to facilitate low-energy machine learning.