 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Safety Guarantee for Stochastic Control Systems Using Average Reward MDPs
Nov 11, 2025



Safety in stochastic control systems, which are subject to random noise with a known probability distribution, aims to compute policies that satisfy predefined operational constraints with high confidence throughout the uncertain evolution of the state variables. The unpredictable evolution of state variables poses a significant challenge for meeting predefined constraints using various control methods. To address this, we present a new algorithm that computes safe policies to determine the safety level across a finite state set. This algorithm reduces the safety objective to the standard average reward Markov Decision Process (MDP) objective. This reduction enables us to use standard techniques, such as linear programs, to compute and analyze safe policies. We validate the proposed method numerically on the Double Integrator and the Inverted Pendulum systems. Results indicate that the average-reward MDPs solution is more comprehensive, converges faster, and offers higher quality compared to the minimum discounted-reward solution.
Robust Maximum Entropy Behavior Cloning
Jan 04, 2021
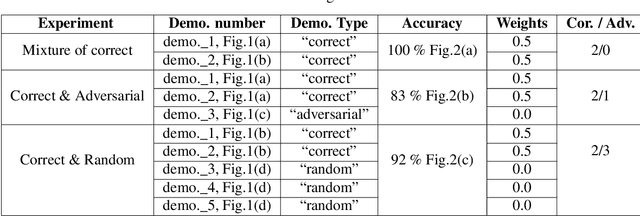

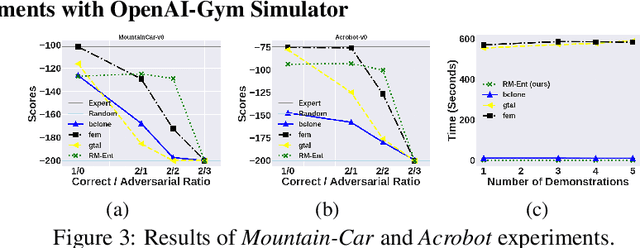
Imitation learning (IL) algorithms use expert demonstrations to learn a specific task. Most of the existing approaches assume that all expert demonstrations are reliable and trustworthy, but what if there exist some adversarial demonstrations among the given data-set? This may result in poor decision-making performance. We propose a novel general frame-work to directly generate a policy from demonstrations that autonomously detect the adversarial demonstrations and exclude them from the data set. At the same time, it's sample, time-efficient, and does not require a simulator. To model such adversarial demonstration we propose a min-max problem that leverages the entropy of the model to assign weights for each demonstration. This allows us to learn the behavior using only the correct demonstrations or a mixture of correct demonstrations.