 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis Towards Classification of Infection and Ischaemia of Diabetic Foot Ulcers
Apr 07, 2021
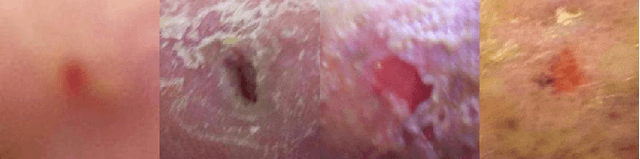
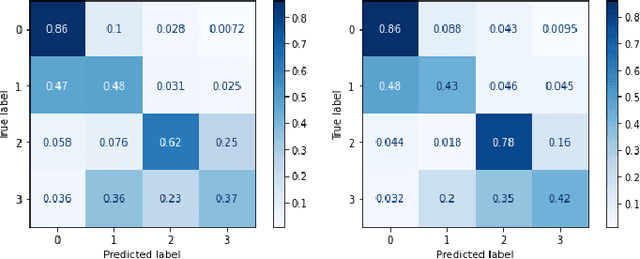
This paper introduces the Diabetic Foot Ulcers dataset (DFUC2021) for analysis of pathology, focusing on infection and ischaemia. We describe the data preparation of DFUC2021 for ground truth annotation, data curation and data analysis. The final release of DFUC2021 consists of 15,683 DFU patches, with 5,955 training, 5,734 for testing and 3,994 unlabeled DFU patches. The ground truth labels are four classes, i.e. control, infection, ischaemia and both conditions. We curate the dataset using image hashing techniques and analyse the separability using UMAP projection. We benchmark the performance of five key backbones of deep learning, i.e. VGG16, ResNet101, InceptionV3, DenseNet121 and EfficientNet on DFUC2021. We report the optimised results of these key backbones with different strategies. Based on our observations, we conclude that EfficientNetB0 with data augmentation and transfer learning provided the best results for multi-class (4-class) classification with macro-average Precision, Recall and F1-score of 0.57, 0.62 and 0.55, respectively. In ischaemia and infection recognition, when trained on one-versus-all, EfficientNetB0 achieved comparable results with the state of the art. Finally, we interpret the results with statistical analysis and Grad-CAM visualisation.
Deep learning in magnetic resonance prostate segmentation: A review and a new perspective
Nov 16, 2020
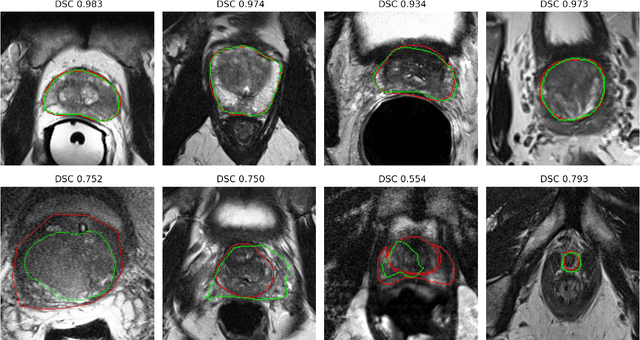
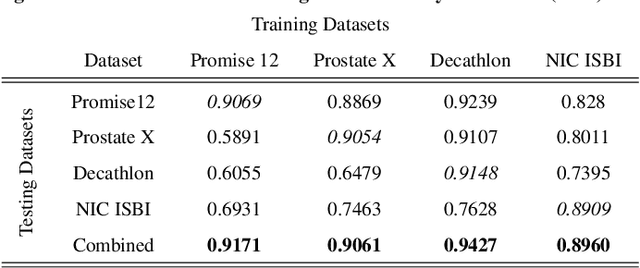
Prostate radiotherapy is a well established curative oncology modality, which in future will use Magnetic Resonance Imaging (MRI)-based radiotherapy for daily adaptive radiotherapy target definition. However the time needed to delineate the prostate from MRI data accurately is a time consuming process. Deep learning has been identified as a potential new technology for the delivery of precision radiotherapy in prostate cancer, where accurate prostate segmentation helps in cancer detection and therapy. However, the trained models can be limited in their application to clinical setting due to different acquisition protocols, limited publicly available datasets, where the size of the datasets are relatively small. Therefore, to explore the field of prostate segmentation and to discover a generalisable solution, we review the state-of-the-art deep learning algorithms in MR prostate segmentation; provide insights to the field by discussing their limitations and strengths; and propose an optimised 2D U-Net for MR prostate segmentation. We evaluate the performance on four publicly available datasets using Dice Similarity Coefficient (DSC) as performance metric. Our experiments include within dataset evaluation and cross-dataset evaluation. The best result is achieved by composite evaluation (DSC of 0.9427 on Decathlon test set) and the poorest result is achieved by cross-dataset evaluation (DSC of 0.5892, Prostate X training set, Promise 12 testing set). We outline the challenges and provide recommendations for future work. Our research provides a new perspective to MR prostate segmentation and more importantly, we provide standardised experiment settings for researchers to evaluate their algorithms. Our code is available at https://github.com/AIEMMU/MRI\_Prostate.
Deep Learning in Diabetic Foot Ulcers Detection: A Comprehensive Evaluation
Oct 15, 2020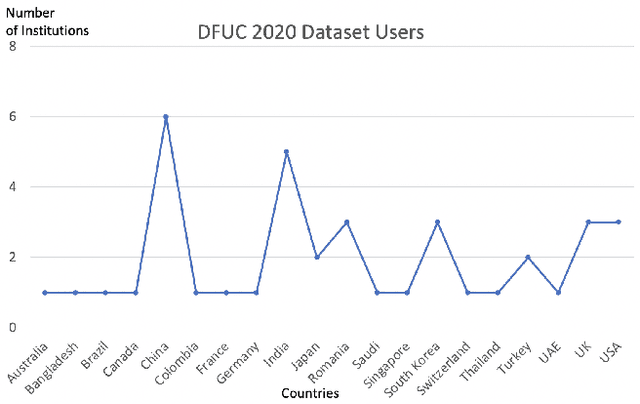
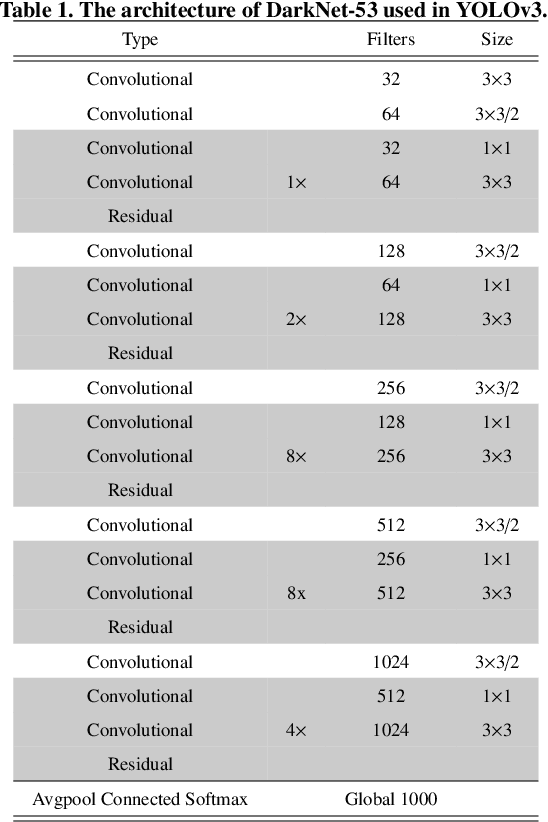
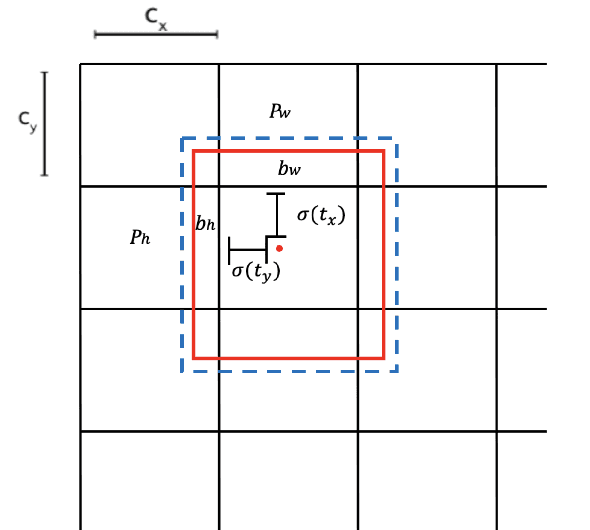
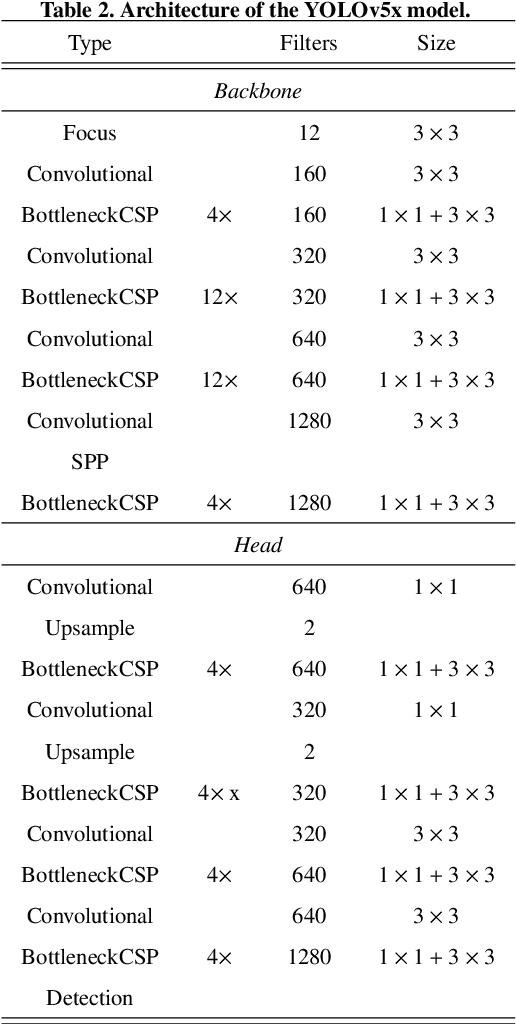
There has been a substantial amount of research on computer methods and technology for the detection and recognition of diabetic foot ulcers (DFUs), but there is a lack of systematic comparisons of state-of-the-art deep learning object detection frameworks applied to this problem. With recent development and data sharing performed as part of the DFU Challenge (DFUC2020) such a comparison becomes possible: DFUC2020 provided participants with a comprehensive dataset consisting of 2,000 images for training each method and 2,000 images for testing them. The following deep learning-based algorithms are compared in this paper: Faster R-CNN, three variants of Faster R-CNN and an ensemble method; YOLOv3; YOLOv5; EfficientDet; and a new Cascade Attention Network. For each deep learning method, we provide a detailed description of model architecture, parameter settings for training and additional stages including pre-processing, data augmentation and post-processing. We provide a comprehensive evaluation for each method. All the methods required a data augmentation stage to increase the number of images available for training and a post-processing stage to remove false positives. The best performance is obtained Deformable Convolution, a variant of Faster R-CNN, with a mAP of 0.6940 and an F1-Score of 0.7434. Finally, we demonstrate that the ensemble method based on different deep learning methods can enhanced the F1-Score but not the mAP. Our results show that state-of-the-art deep learning methods can detect DFU with some accuracy, but there are many challenges ahead before they can be implemented in real world settings.
R-MNet: A Perceptual Adversarial Network for Image Inpainting
Aug 11, 2020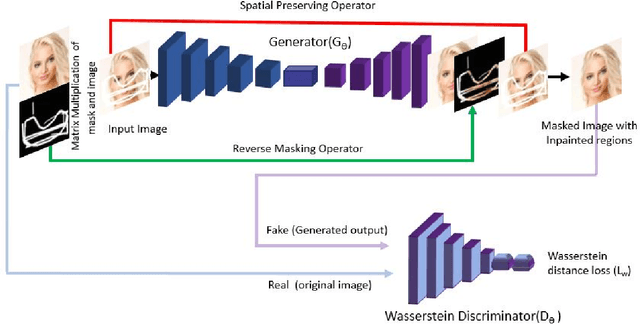
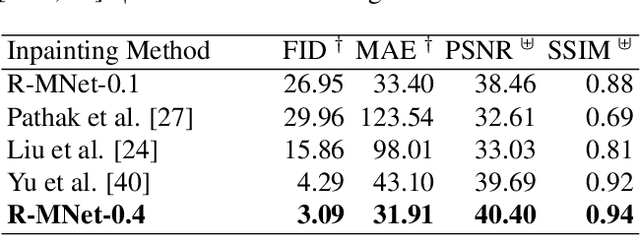
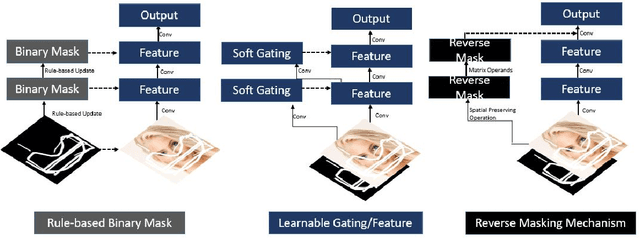

Facial image inpainting is a problem that is widely studied, and in recent years the introduction of Generative Adversarial Networks, has led to improvements in the field. Unfortunately some issues persists, in particular when blending the missing pixels with the visible ones. We address the problem by proposing a Wasserstein GAN combined with a new reverse mask operator, namely Reverse Masking Network (R-MNet), a perceptual adversarial network for image inpainting. The reverse mask operator transfers the reverse masked image to the end of the encoder-decoder network leaving only valid pixels to be inpainted. Additionally, we propose a new loss function computed in feature space to target only valid pixels combined with adversarial training. These then capture data distributions and generate images similar to those in the training data with achieved realism (realistic and coherent) on the output images. We evaluate our method on publicly available dataset, and compare with state-of-the-art methods. We show that our method is able to generalize to high-resolution inpainting task, and further show more realistic outputs that are plausible to the human visual system when compared with the state-of-the-art methods.
DFUC2020: Analysis Towards Diabetic Foot Ulcer Detection
Apr 24, 2020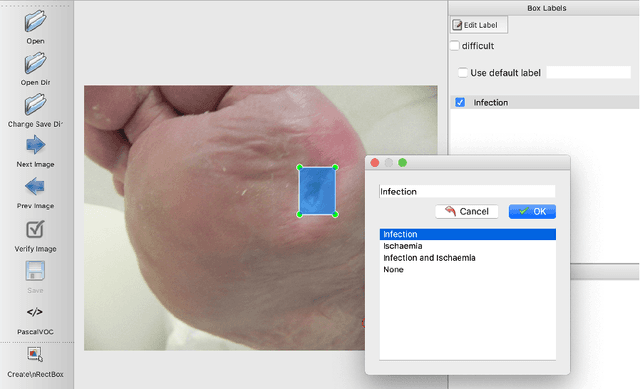
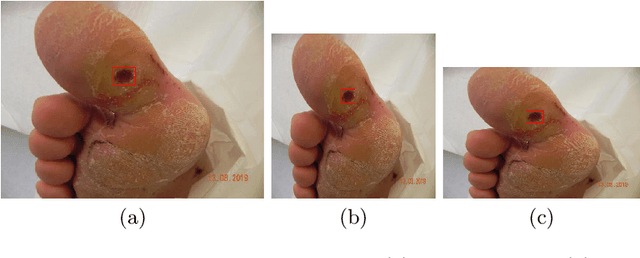
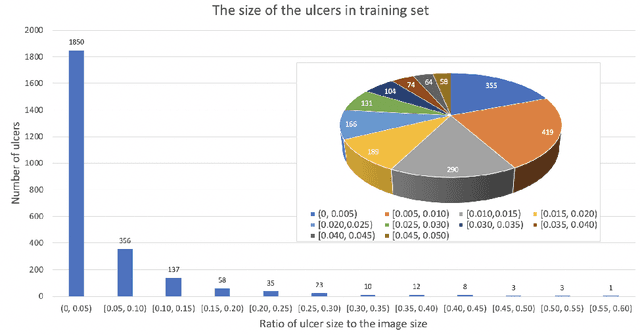
Every 20 seconds, a limb is amputated somewhere in the world due to diabetes. This is a global health problem that requires a global solution. The MICCAI challenge discussed in this paper, which concerns the detection of diabetic foot ulcers, will accelerate the development of innovative healthcare technology to address this unmet medical need. In an effort to improve patient care and reduce the strain on healthcare systems, recent research has focused on the creation of cloud-based detection algorithms that can be consumed as a service by a mobile app that patients (or a carer, partner or family member) could use themselves to monitor their condition and to detect the appearance of a diabetic foot ulcer (DFU). Collaborative work between Manchester Metropolitan University, Lancashire Teaching Hospital and the Manchester University NHS Foundation Trust has created a repository of 4000 DFU images for the purpose of supporting research toward more advanced methods of DFU detection. Based on a joint effort involving the lead scientists of the UK, US, India and New Zealand, this challenge will solicit original work, and promote interactions between researchers and interdisciplinary collaborations. This paper presents a dataset description and analysis, assessment methods, benchmark algorithms and initial evaluation results. It facilitates the challenge by providing useful insights into state-of-the-art and ongoing research.
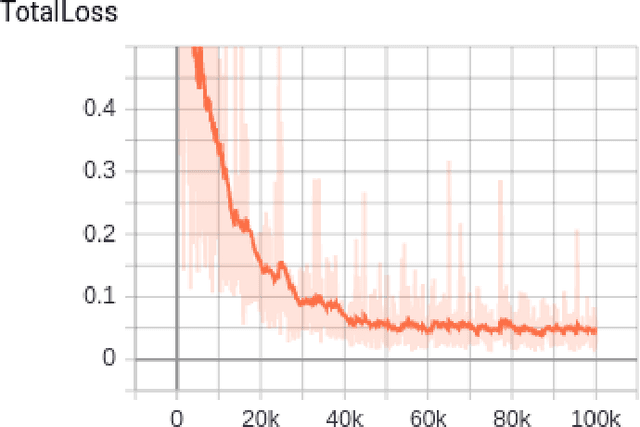
Anysize GAN: A solution to the image-warping problem
Mar 06, 2020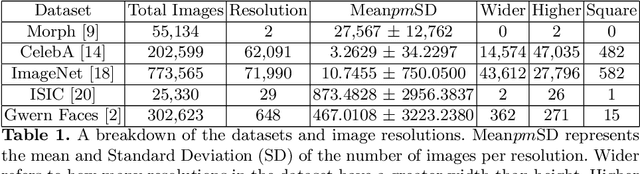

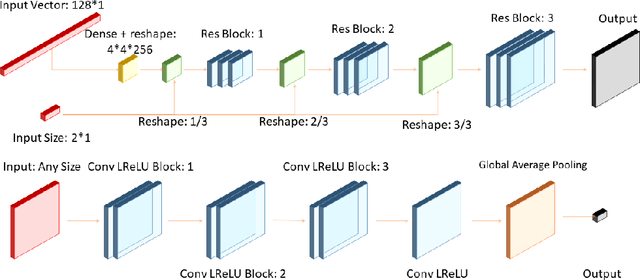
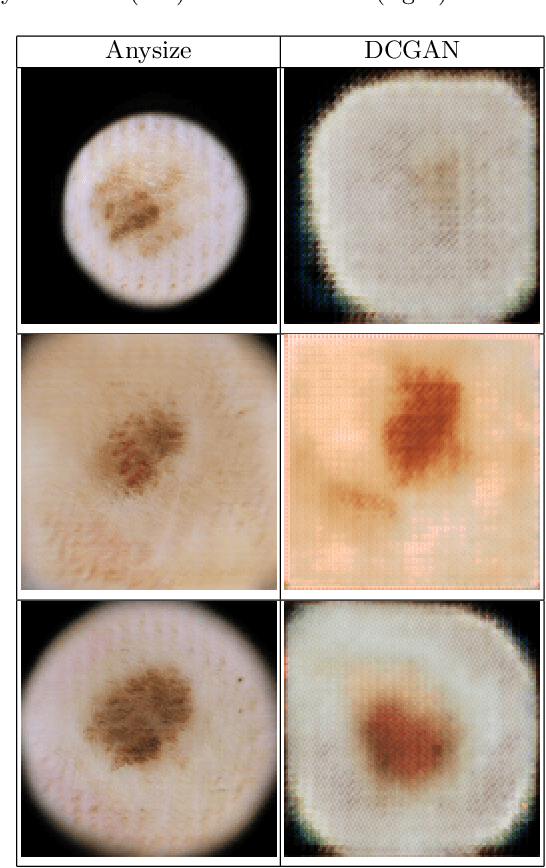
We propose a new type of General Adversarial Network (GAN) to resolve a common issue with Deep Learning. We develop a novel architecture that can be applied to existing latent vector based GAN structures that allows them to generate on-the-fly images of any size. Existing GAN for image generation requires uniform images of matching dimensions. However, publicly available datasets, such as ImageNet contain thousands of different sizes. Resizing image causes deformations and changing the image data, whereas as our network does not require this preprocessing step. We make significant changes to the standard data loading techniques to enable any size image to be loaded for training. We also modify the network in two ways, by adding multiple inputs and a novel dynamic resizing layer. Finally we make adjustments to the discriminator to work on multiple resolutions. These changes can allow multiple resolution datasets to be trained on without any resizing, if memory allows. We validate our results on the ISIC 2019 skin lesion dataset. We demonstrate our method can successfully generate realistic images at different sizes without issue, preserving and understanding spatial relationships, while maintaining feature relationships. We will release the source codes upon paper acceptance.
Spotting Macro- and Micro-expression Intervals in Long Video Sequences
Feb 05, 2020
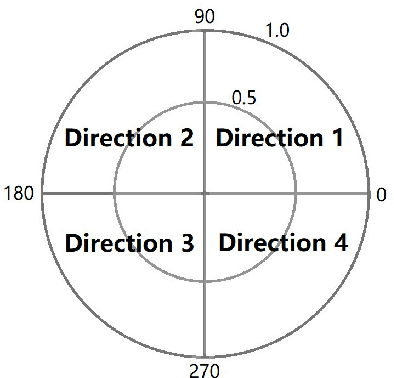

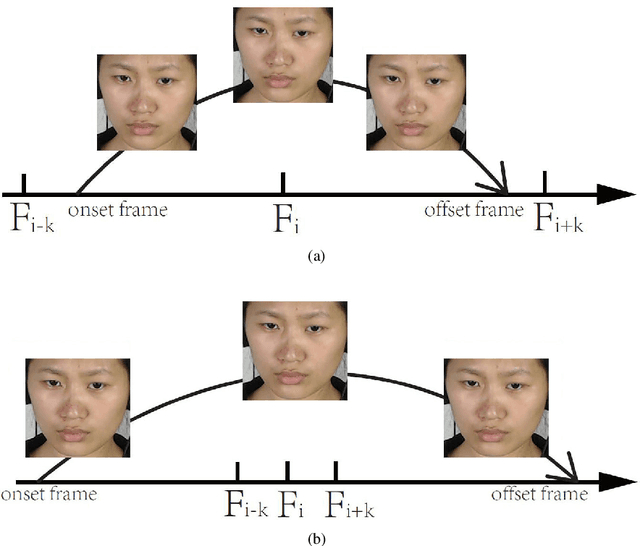
This paper presents baseline results for the Third Facial Micro-Expression Grand Challenge (MEGC 2020). Both macro- and micro-expression intervals in CAS(ME)$^2$ and SAMM Long Videos are spotted by employing the method of Main Directional Maximal Difference Analysis (MDMD). The MDMD method uses the magnitude maximal difference in the main direction of optical flow features to spot facial movements. The single frame prediction results of the original MDMD method are post processed into reasonable video intervals. The metric F1-scores of baseline results are evaluated: for CAS(ME)$^2$, the F1-scores are 0.1196 and 0.0082 for macro- and micro-expressions respectively, and the overall F1-score is 0.0376; for SAMM Long Videos, the F1-scores are 0.0629 and 0.0364 for macro- and micro-expressions respectively, and the overall F1-score is 0.0445. The baseline project codes is publicly available at https://github.com/HeyingGithub/Baseline-project-for-MEGC2020_spotting.
Symmetric Skip Connection Wasserstein GAN for High-Resolution Facial Image Inpainting
Jan 11, 2020
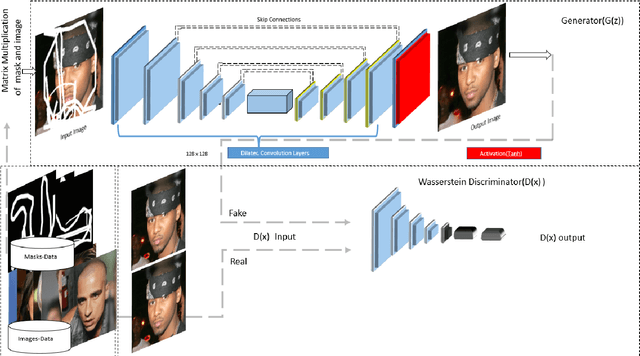
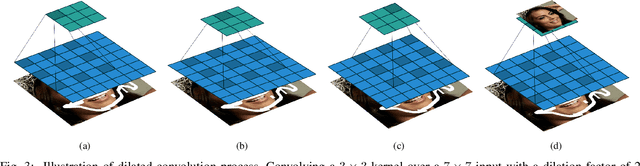

We propose a Symmetric Skip Connection Wasserstein Generative Adversarial Network (S-WGAN) for high-resolution facial image inpainting. The architecture is an encoder-decoder with convolutional blocks, linked by skip connections. The encoder is a feature extractor that captures data abstractions of an input image to learn an end-to-end mapping from an input (binary masked image) to the ground-truth. The decoder uses the learned abstractions to reconstruct the image. With skip connections, S-WGAN transfers image details to the decoder. Also, we propose a Wasserstein-Perceptual loss function to preserve colour and maintain realism on a reconstructed image. We evaluate our method and the state-of-the-art methods on CelebA-HQ dataset. Our results show S-WGAN produces sharper and more realistic images when visually compared with other methods. The quantitative measures show our proposed S-WGAN achieves the best Structure Similarity Index Measure of 0.94.
SAMM Long Videos: A Spontaneous Facial Micro- and Macro-Expressions Dataset
Nov 04, 2019

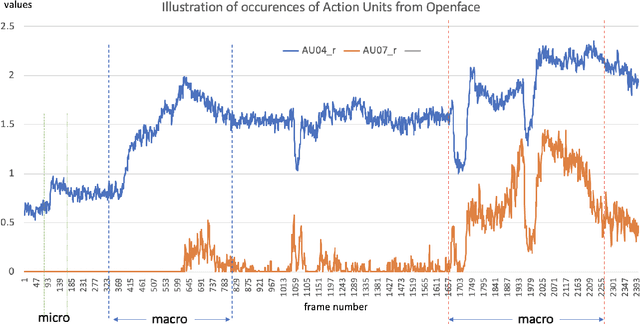
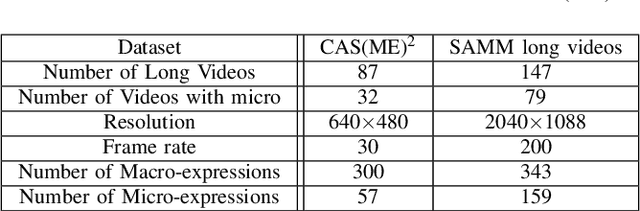
With the growth of popularity of facial microexpressions in recent years, the demand for long videos with micro- and macro-expressions is increasing. Extended from SAMM, a micro-expressions dataset released in 2016, this short report presents SAMM Long Videos dataset for spontaneous micro- and macro-expressions recognition and spotting. SAMM Long Videos dataset consists of 147 long videos with 343 macro-expressions and 159 micro-expressions. The dataset isFACS-coded with detailed Action Units (AUs). We compareour dataset with the Chinese Academy of Sciences MacroExpressions and Micro-Expressions (CAS(ME)2) dataset, which is the only available fully annotated dataset with micro- and macro-expressions. Further, we preprocess the long videos using OpenFace, which includes face alignment and detection of facial movements based on the AUs. We will release the long videos for the next micro-expressions, and macro-expressions spotting challenge and future research uses.
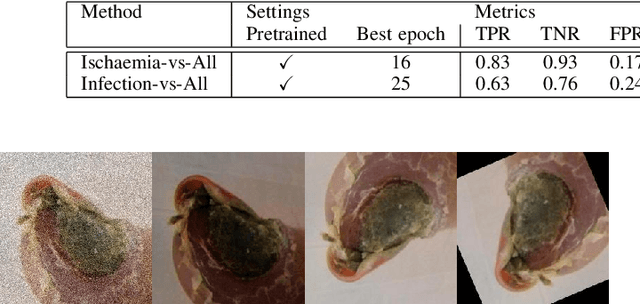
Recognition of Ischaemia and Infection in Diabetic Foot Ulcers: Dataset and Techniques
Sep 11, 2019
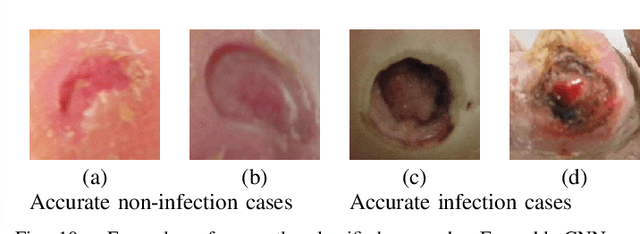
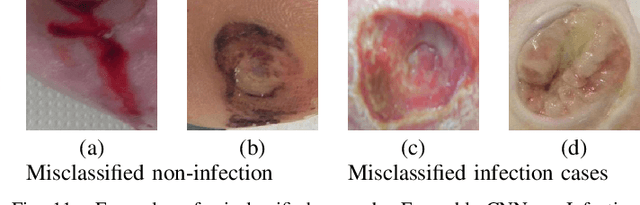

Diabetic Foot Ulcers (DFU) detection using computerized methods is an emerging research area with the evolution of machine learning algorithms. However, existing research focuses on detecting and segmenting the ulcers. According to DFU medical classification systems, i.e. University of Texas Classification and SINBAD Classification, the presence of infection (bacteria in the wound) and ischaemia (inadequate blood supply) has important clinical implication for DFU assessment, which were used to predict the risk of amputation. In this work, we propose a new dataset and novel techniques to identify the presence of infection and ischaemia. We introduce a very comprehensive DFU dataset with ground truth labels of ischaemia and infection cases. For hand-crafted machine learning approach, we propose new feature descriptor, namely Superpixel Color Descriptor. Then, we propose a technique using Ensemble Convolutional Neural Network (CNN) model for ischaemia and infection recognition. The novelty lies in our proposed natural data-augmentation method, which clearly identifies the region of interest on foot images and focuses on finding the salient features existing in this area. Finally, we evaluate the performance of our proposed techniques on binary classification, i.e. ischaemia versus non-ischaemia and infection versus non-infection. Overall, our proposed method performs better in the classification of ischaemia than infection. We found that our proposed Ensemble CNN deep learning algorithms performed better for both classification tasks than hand-crafted machine learning algorithms, with 90% accuracy in ischaemia classification and 73% in infection classification.