 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
AAU-net: An Adaptive Attention U-net for Breast Lesions Segmentation in Ultrasound Images
Apr 26, 2022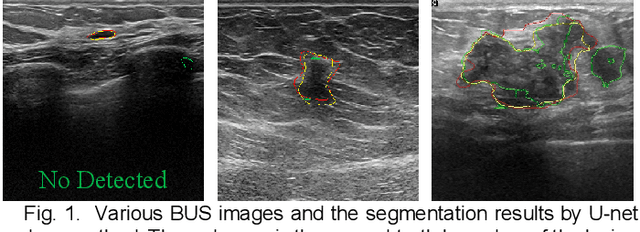
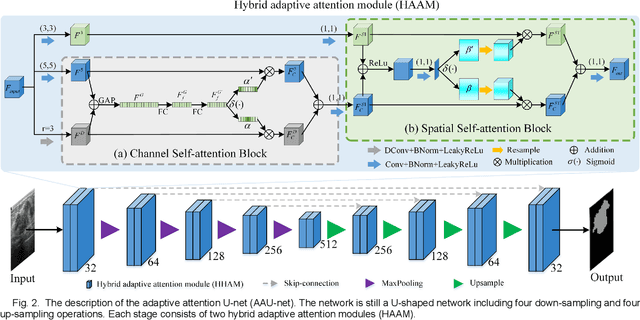
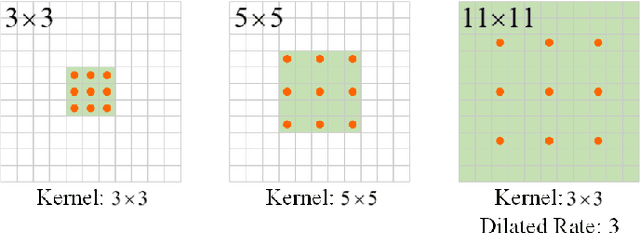
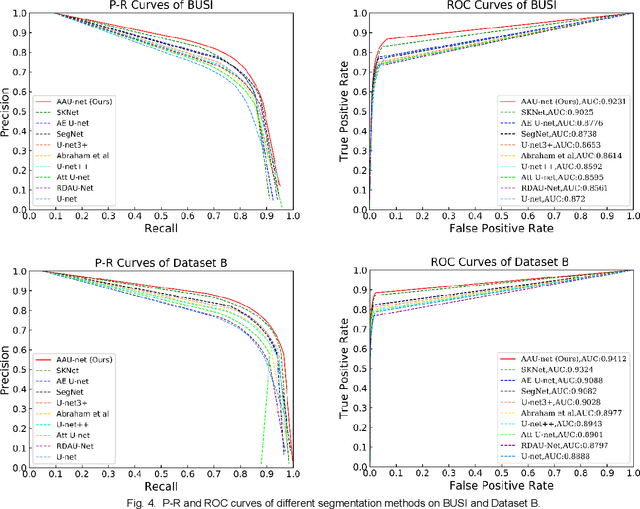
Various deep learning methods have been proposed to segment breast lesion from ultrasound images. However, similar intensity distributions, variable tumor morphology and blurred boundaries present challenges for breast lesions segmentation, especially for malignant tumors with irregular shapes. Considering the complexity of ultrasound images, we develop an adaptive attention U-net (AAU-net) to segment breast lesions automatically and stably from ultrasound images. Specifically, we introduce a hybrid adaptive attention module, which mainly consists of a channel self-attention block and a spatial self-attention block, to replace the traditional convolution operation. Compared with the conventional convolution operation, the design of the hybrid adaptive attention module can help us capture more features under different receptive fields. Different from existing attention mechanisms, the hybrid adaptive attention module can guide the network to adaptively select more robust representation in channel and space dimensions to cope with more complex breast lesions segmentation. Extensive experiments with several state-of-the-art deep learning segmentation methods on three public breast ultrasound datasets show that our method has better performance on breast lesion segmentation. Furthermore, robustness analysis and external experiments demonstrate that our proposed AAU-net has better generalization performance on the segmentation of breast lesions. Moreover, the hybrid adaptive attention module can be flexibly applied to existing network frameworks.
Translating Clinical Delineation of Diabetic Foot Ulcers into Machine Interpretable Segmentation
Apr 22, 2022
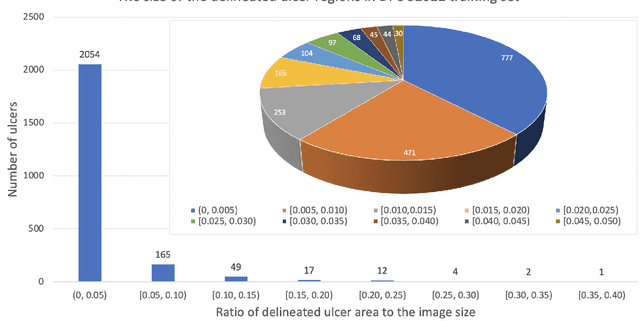
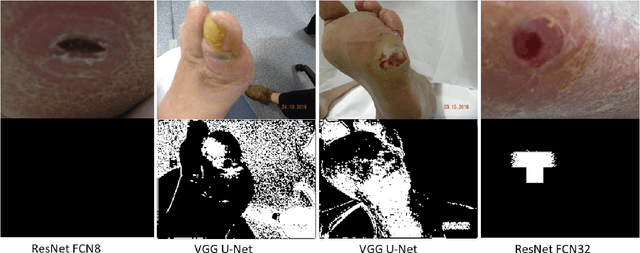
Diabetic foot ulcer is a severe condition that requires close monitoring and management. For training machine learning methods to auto-delineate the ulcer, clinical staff must provide ground truth annotations. In this paper, we propose a new diabetic foot ulcers dataset, namely DFUC2022, the largest segmentation dataset where ulcer regions were manually delineated by clinicians. We assess whether the clinical delineations are machine interpretable by deep learning networks or if image processing refined contour should be used. By providing benchmark results using a selection of popular deep learning algorithms, we draw new insights into the limitations of DFU wound delineation and report on the associated issues. This paper provides some observations on baseline models to facilitate DFUC2022 Challenge in conjunction with MICCAI 2022. The leaderboard will be ranked by Dice score, where the best FCN-based method is 0.5708 and DeepLabv3+ achieved the best score of 0.6277. This paper demonstrates that image processing using refined contour as ground truth can provide better agreement with machine predicted results. DFUC2022 will be released on the 27th April 2022.
V-LinkNet: Learning Contextual Inpainting Across Latent Space of Generative Adversarial Network
Jan 02, 2022
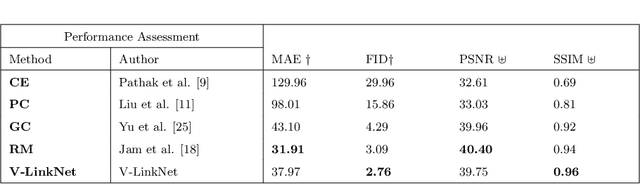

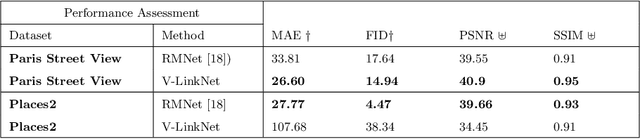
Deep learning methods outperform traditional methods in image inpainting. In order to generate contextual textures, researchers are still working to improve on existing methods and propose models that can extract, propagate, and reconstruct features similar to ground-truth regions. Furthermore, the lack of a high-quality feature transfer mechanism in deeper layers contributes to persistent aberrations on generated inpainted regions. To address these limitations, we propose the V-LinkNet cross-space learning strategy network. To improve learning on contextualised features, we design a loss model that employs both encoders. In addition, we propose a recursive residual transition layer (RSTL). The RSTL extracts high-level semantic information and propagates it down layers. Finally, we compare inpainting performance on the same face with different masks and on different faces with the same masks. To improve image inpainting reproducibility, we propose a standard protocol to overcome biases with various masks and images. We investigate the V-LinkNet components using experimental methods. Our result surpasses the state of the art when evaluated on the CelebA-HQ with the standard protocol. In addition, our model can generalise well when evaluated on Paris Street View, and Places2 datasets with the standard protocol.
Development of Diabetic Foot Ulcer Datasets: An Overview
Jan 01, 2022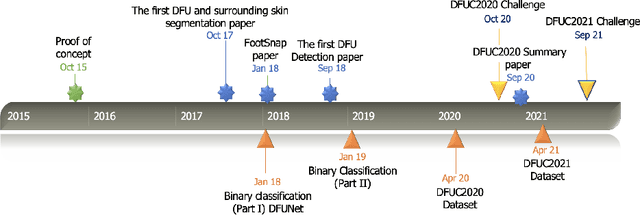
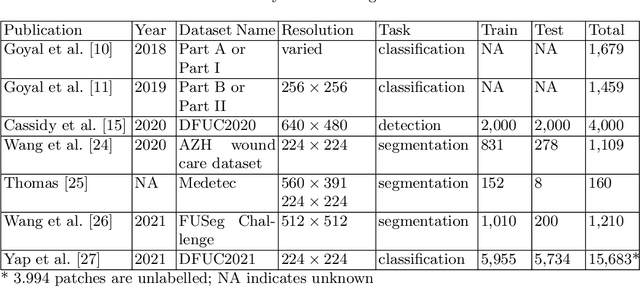
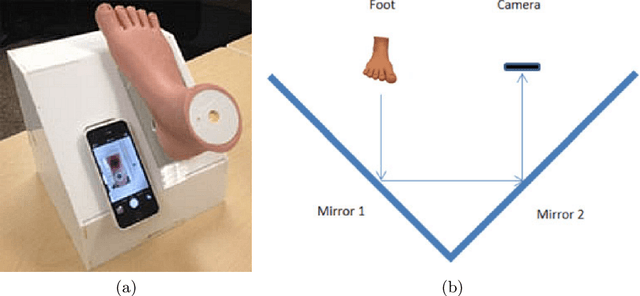
This paper provides conceptual foundation and procedures used in the development of diabetic foot ulcer datasets over the past decade, with a timeline to demonstrate progress. We conduct a survey on data capturing methods for foot photographs, an overview of research in developing private and public datasets, the related computer vision tasks (detection, segmentation and classification), the diabetic foot ulcer challenges and the future direction of the development of the datasets. We report the distribution of dataset users by country and year. Our aim is to share the technical challenges that we encountered together with good practices in dataset development, and provide motivation for other researchers to participate in data sharing in this domain.
Diabetic Foot Ulcer Grand Challenge 2021: Evaluation and Summary
Nov 19, 2021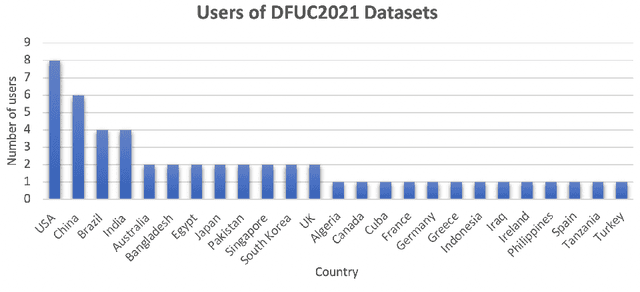

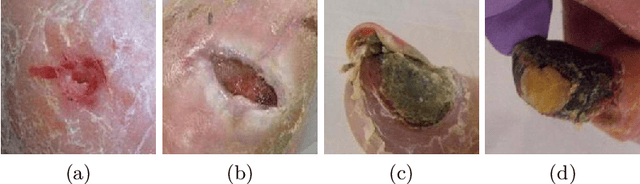
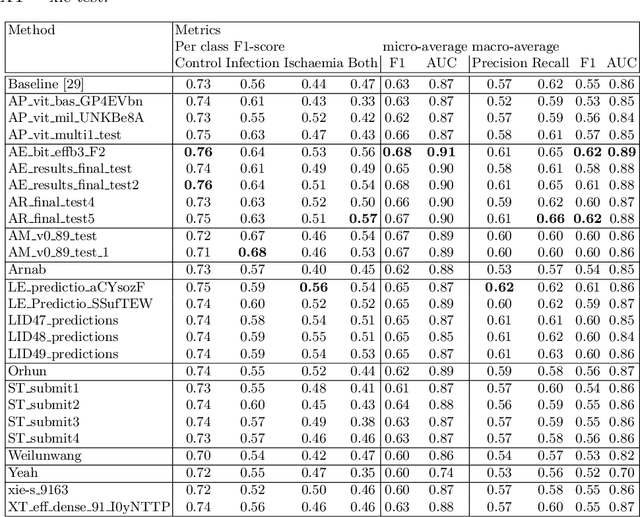
Diabetic foot ulcer classification systems use the presence of wound infection (bacteria present within the wound) and ischaemia (restricted blood supply) as vital clinical indicators for treatment and prediction of wound healing. Studies investigating the use of automated computerised methods of classifying infection and ischaemia within diabetic foot wounds are limited due to a paucity of publicly available datasets and severe data imbalance in those few that exist. The Diabetic Foot Ulcer Challenge 2021 provided participants with a more substantial dataset comprising a total of 15,683 diabetic foot ulcer patches, with 5,955 used for training, 5,734 used for testing and an additional 3,994 unlabelled patches to promote the development of semi-supervised and weakly-supervised deep learning techniques. This paper provides an evaluation of the methods used in the Diabetic Foot Ulcer Challenge 2021, and summarises the results obtained from each network. The best performing network was an ensemble of the results of the top 3 models, with a macro-average F1-score of 0.6307.
FacialGAN: Style Transfer and Attribute Manipulation on Synthetic Faces
Oct 18, 2021



Facial image manipulation is a generation task where the output face is shifted towards an intended target direction in terms of facial attribute and styles. Recent works have achieved great success in various editing techniques such as style transfer and attribute translation. However, current approaches are either focusing on pure style transfer, or on the translation of predefined sets of attributes with restricted interactivity. To address this issue, we propose FacialGAN, a novel framework enabling simultaneous rich style transfers and interactive facial attributes manipulation. While preserving the identity of a source image, we transfer the diverse styles of a target image to the source image. We then incorporate the geometry information of a segmentation mask to provide a fine-grained manipulation of facial attributes. Finally, a multi-objective learning strategy is introduced to optimize the loss of each specific tasks. Experiments on the CelebA-HQ dataset, with CelebAMask-HQ as semantic mask labels, show our model's capacity in producing visually compelling results in style transfer, attribute manipulation, diversity and face verification. For reproducibility, we provide an interactive open-source tool to perform facial manipulations, and the Pytorch implementation of the model.
3D-CNN for Facial Micro- and Macro-expression Spotting on Long Video Sequences using Temporal Oriented Reference Frame
Jun 10, 2021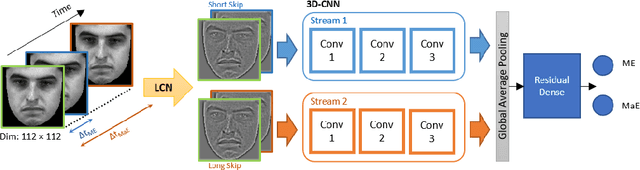
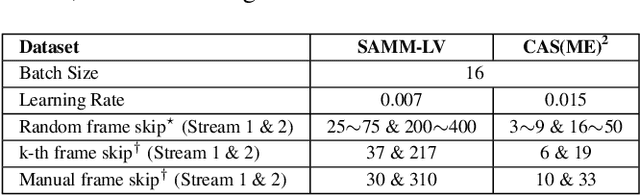
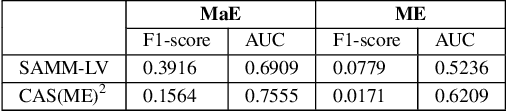
Facial expression spotting is the preliminary step for micro- and macro-expression analysis. The task of reliably spotting such expressions in video sequences is currently unsolved. The current best systems depend upon optical flow methods to extract regional motion features, before categorisation of that motion into a specific class of facial movement. Optical flow is susceptible to drift error, which introduces a serious problem for motions with long-term dependencies, such as high frame-rate macro-expression. We propose a purely deep learning solution which, rather than track frame differential motion, compares via a convolutional model, each frame with two temporally local reference frames. Reference frames are sampled according to calculated micro- and macro-expression durations. We show that our solution achieves state-of-the-art performance (F1-score of 0.126) in a dataset of high frame-rate (200 fps) long video sequences (SAMM-LV) and is competitive in a low frame-rate (30 fps) dataset (CAS(ME)2). In this paper, we document our deep learning model and parameters, including how we use local contrast normalisation, which we show is critical for optimal results. We surpass a limitation in existing methods, and advance the state of deep learning in the domain of facial expression spotting.
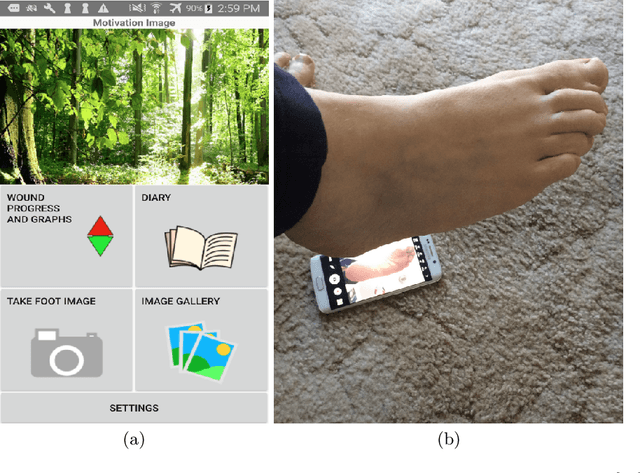
A Cloud-based Deep Learning Framework for Remote Detection of Diabetic Foot Ulcers
May 17, 2021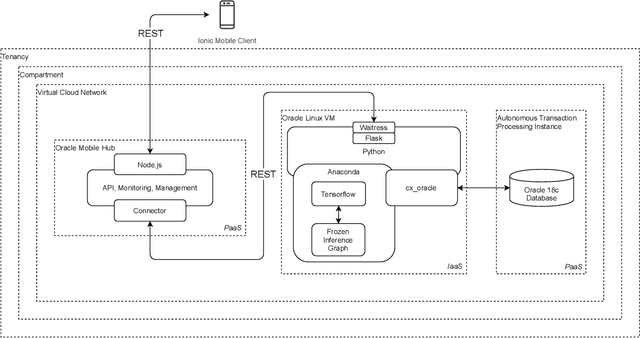

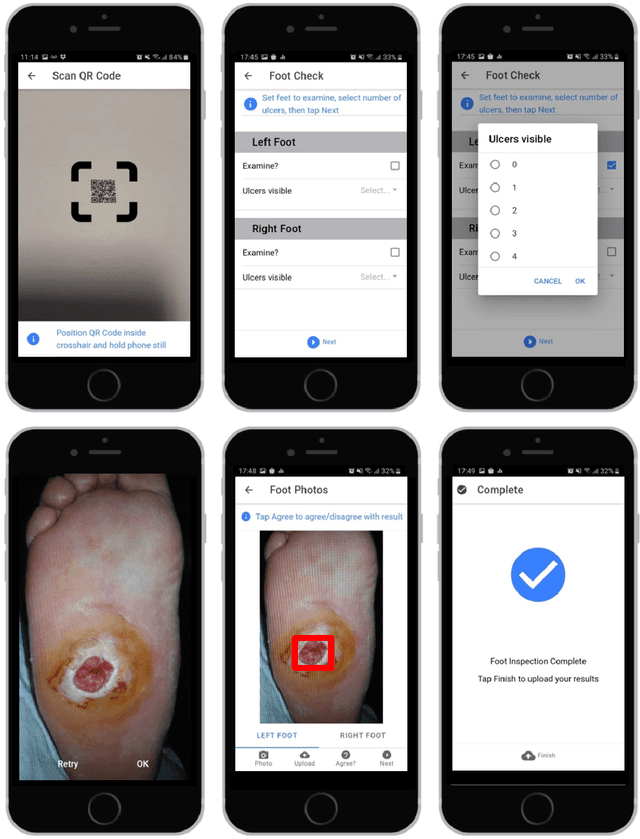
This research proposes a mobile and cloud-based framework for the automatic detection of diabetic foot ulcers and conducts an investigation of its performance. The system uses a cross-platform mobile framework which enables the deployment of mobile apps to multiple platforms using a single TypeScript code base. A deep convolutional neural network was deployed to a cloud-based platform where the mobile app could send photographs of patient's feet for inference to detect the presence of diabetic foot ulcers. The functionality and usability of the system were tested in two clinical settings: Salford Royal NHS Foundation Trust and Lancashire Teaching Hospitals NHS Foundation Trust. The benefits of the system, such as the potential use of the app by patients to identify and monitor their condition are discussed.
Foreground-guided Facial Inpainting with Fidelity Preservation
May 07, 2021
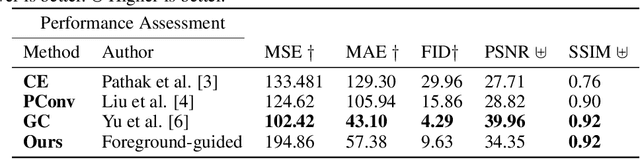
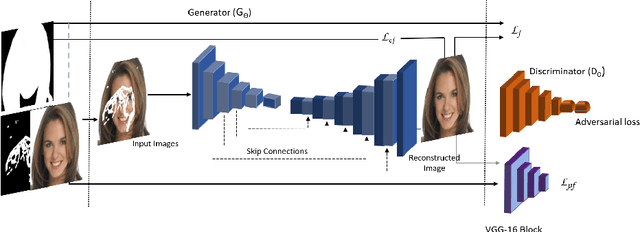
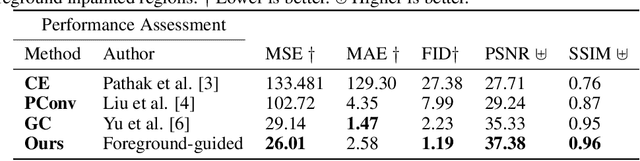
Facial image inpainting, with high-fidelity preservation for image realism, is a very challenging task. This is due to the subtle texture in key facial features (component) that are not easily transferable. Many image inpainting techniques have been proposed with outstanding capabilities and high quantitative performances recorded. However, with facial inpainting, the features are more conspicuous and the visual quality of the blended inpainted regions are more important qualitatively. Based on these facts, we design a foreground-guided facial inpainting framework that can extract and generate facial features using convolutional neural network layers. It introduces the use of foreground segmentation masks to preserve the fidelity. Specifically, we propose a new loss function with semantic capability reasoning of facial expressions, natural and unnatural features (make-up). We conduct our experiments using the CelebA-HQ dataset, segmentation masks from CelebAMask-HQ (for foreground guidance) and Quick Draw Mask (for missing regions). Our proposed method achieved comparable quantitative results when compare to the state of the art but qualitatively, it demonstrated high-fidelity preservation of facial components.