 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D CNNs with Adaptive Temporal Feature Resolutions
Nov 17, 2020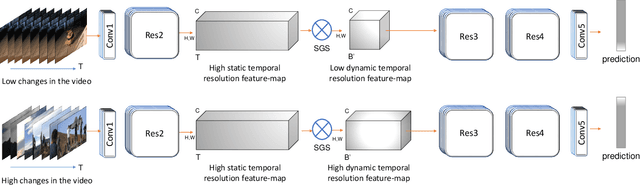

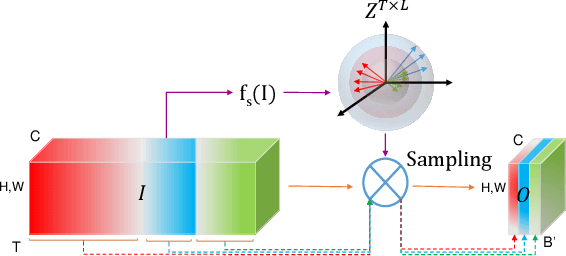

While state-of-the-art 3D Convolutional Neural Networks (CNN) achieve very good results on action recognition datasets, they are computationally very expensive and require many GFLOPs. While the GFLOPs of a 3D CNN can be decreased by reducing the temporal feature resolution within the network, there is no setting that is optimal for all input clips. In this work, we, therefore, introduce a differentiable Similarity Guided Sampling (SGS) module, which can be plugged into any existing 3D CNN architecture. SGS empowers 3D CNNs by learning the similarity of temporal features and grouping similar features together. As a result, the temporal feature resolution is not anymore static but it varies for each input video clip. By integrating SGS as an additional layer within current 3D CNNs, we can convert them into much more efficient 3D CNNs with adaptive temporal feature resolutions (ATFR). Our evaluations show that the proposed module improves the state-of-the-art by reducing the computational cost (GFLOPs)by half while preserving or even improving the accuracy. We evaluate our module by adding it to multiple state-of-the-art 3D CNNs on various datasets such as Kinetics-600, Kinetics-400, mini-Kinetics, Something-Something V2, UCF101, and HMDB51
SCT: Set Constrained Temporal Transformer for Set Supervised Action Segmentation
Mar 31, 2020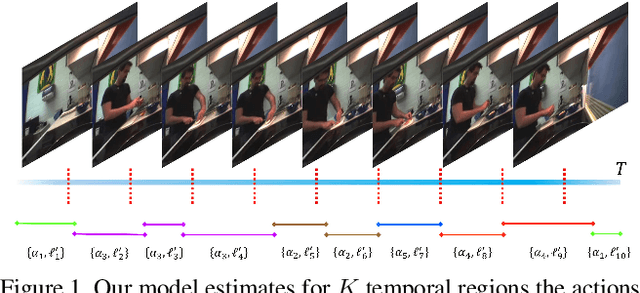
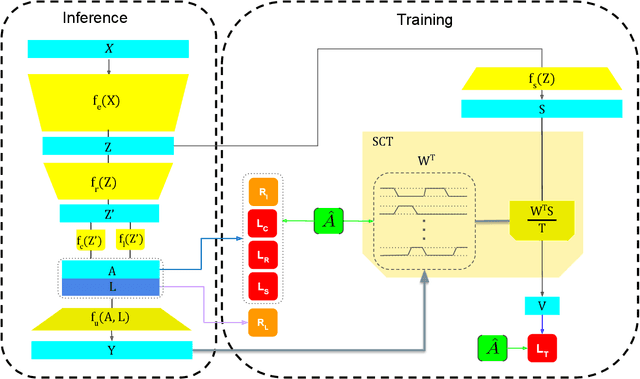


Temporal action segmentation is a topic of increasing interest, however, annotating each frame in a video is cumbersome and costly. Weakly supervised approaches therefore aim at learning temporal action segmentation from videos that are only weakly labeled. In this work, we assume that for each training video only the list of actions is given that occur in the video, but not when, how often, and in which order they occur. In order to address this task, we propose an approach that can be trained end-to-end on such data. The approach divides the video into smaller temporal regions and predicts for each region the action label and its length. In addition, the network estimates the action labels for each frame. By measuring how consistent the frame-wise predictions are with respect to the temporal regions and the annotated action labels, the network learns to divide a video into class-consistent regions. We evaluate our approach on three datasets where the approach achieves state-of-the-art results.
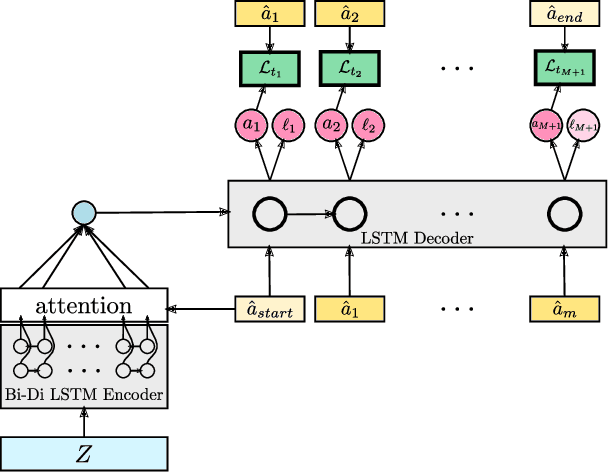
Holistic Large Scale Video Understanding
Apr 25, 2019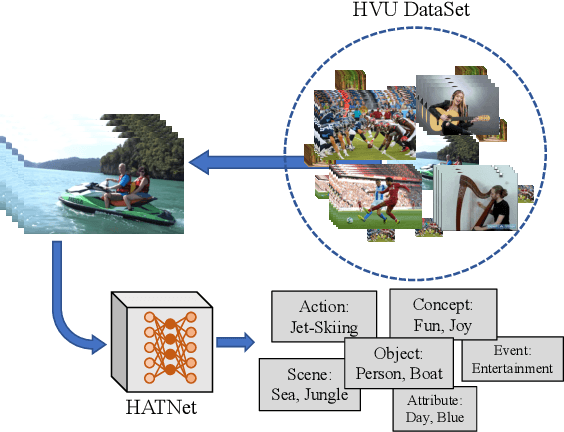

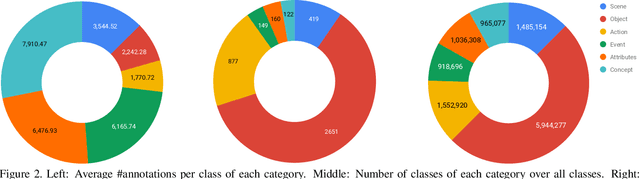

Action recognition has been advanced in recent years by benchmarks with rich annotations. However, research is still mainly limited to human action or sports recognition - focusing on a highly specific video understanding task and thus leaving a significant gap towards describing the overall content of a video. We fill in this gap by presenting a large-scale "Holistic Video Understanding Dataset"~(HVU). HVU is organized hierarchically in a semantic taxonomy that focuses on multi-label and multi-task video understanding as a comprehensive problem that encompasses the recognition of multiple semantic aspects in the dynamic scene. HVU contains approx.~577k videos in total with 13M annotations for training and validation set spanning over {4378} classes. HVU encompasses semantic aspects defined on categories of scenes, objects, actions, events, attributes and concepts, which naturally captures the real-world scenarios. Further, we introduce a new spatio-temporal deep neural network architecture called "Holistic Appearance and Temporal Network"~(HATNet) that builds on fusing 2D and 3D architectures into one by combining intermediate representations of appearance and temporal cues. HATNet focuses on the multi-label and multi-task learning problem and is trained in an end-to-end manner. The experiments show that HATNet trained on HVU outperforms current state-of-the-art methods on challenging human action datasets: HMDB51, UCF101, and Kinetics. The dataset and codes will be made publicly available.
Weakly Supervised Action Segmentation Using Mutual Consistency
Apr 05, 2019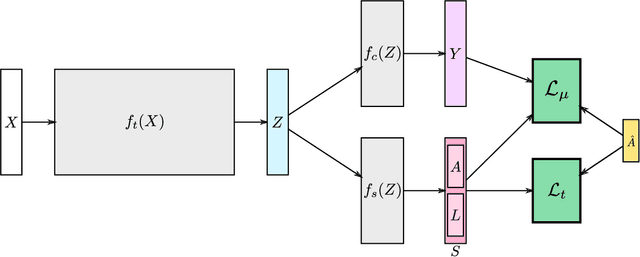

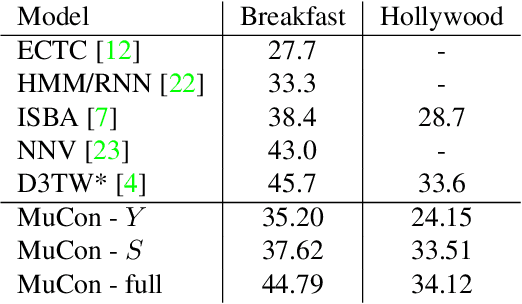
Action segmentation is the task of predicting the actions in each frame of a video. Because of the high cost of preparing training videos with full supervision for action segmentation, weakly supervised approaches which are able to learn only from transcripts are very appealing. In this paper, we propose a new approach for weakly supervised action segmentation based on a two branch network. The two branches of our network predict two redundant but different representations for action segmentation. During training we introduce a new mutual consistency loss (MuCon) that enforces that these two representations are consistent. Using MuCon and a transcript prediction loss, our network achieves state-of-the-art results for action segmentation and action alignment while being fully differentiable and faster to train since it does not require a costly alignment step during training.
AVID: Adversarial Visual Irregularity Detection
Jul 17, 2018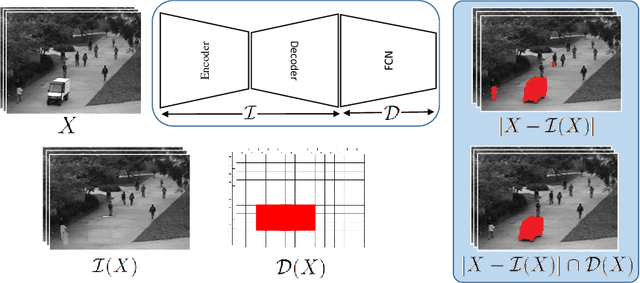
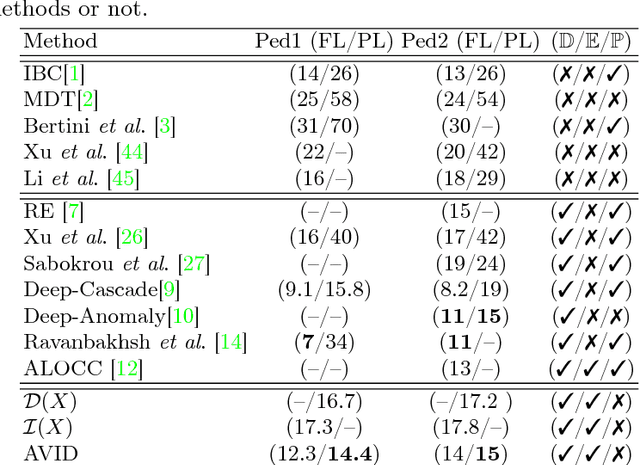

Real-time detection of irregularities in visual data is very invaluable and useful in many prospective applications including surveillance, patient monitoring systems, etc. With the surge of deep learning methods in the recent years, researchers have tried a wide spectrum of methods for different applications. However, for the case of irregularity or anomaly detection in videos, training an end-to-end model is still an open challenge, since often irregularity is not well-defined and there are not enough irregular samples to use during training. In this paper, inspired by the success of generative adversarial networks (GANs) for training deep models in unsupervised or self-supervised settings, we propose an end-to-end deep network for detection and fine localization of irregularities in videos (and images). Our proposed architecture is composed of two networks, which are trained in competing with each other while collaborating to find the irregularity. One network works as a pixel-level irregularity Inpainter, and the other works as a patch-level Detector. After an adversarial self-supervised training, in which I tries to fool D into accepting its inpainted output as regular (normal), the two networks collaborate to detect and fine-segment the irregularity in any given testing video. Our results on three different datasets show that our method can outperform the state-of-the-art and fine-segment the irregularity.
Spatio-Temporal Channel Correlation Networks for Action Classification
Jun 25, 2018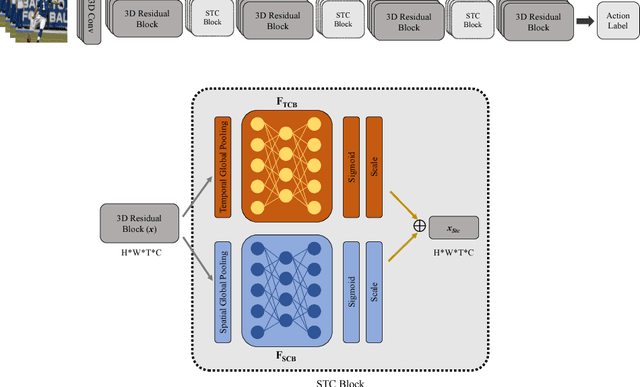
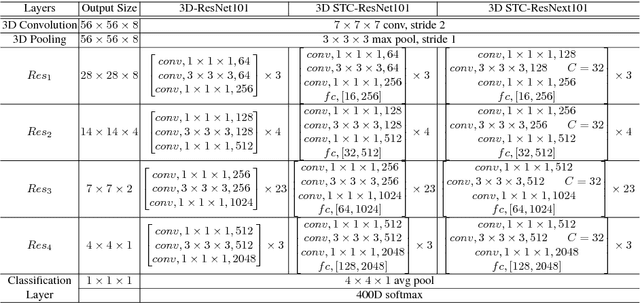
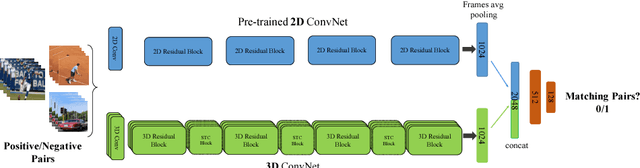
The work in this paper is driven by the question if spatio-temporal correlations are enough for 3D convolutional neural networks (CNN)? Most of the traditional 3D networks use local spatio-temporal features. We introduce a new block that models correlations between channels of a 3D CNN with respect to temporal and spatial features. This new block can be added as a residual unit to different parts of 3D CNNs. We name our novel block 'Spatio-Temporal Channel Correlation' (STC). By embedding this block to the current state-of-the-art architectures such as ResNext and ResNet, we improved the performance by 2-3\% on Kinetics dataset. Our experiments show that adding STC blocks to current state-of-the-art architectures outperforms the state-of-the-art methods on the HMDB51, UCF101 and Kinetics datasets. The other issue in training 3D CNNs is about training them from scratch with a huge labeled dataset to get a reasonable performance. So the knowledge learned in 2D CNNs is completely ignored. Another contribution in this work is a simple and effective technique to transfer knowledge from a pre-trained 2D CNN to a randomly initialized 3D CNN for a stable weight initialization. This allows us to significantly reduce the number of training samples for 3D CNNs. Thus, by fine-tuning this network, we beat the performance of generic and recent methods in 3D CNNs, which were trained on large video datasets, e.g. Sports-1M, and fine-tuned on the target datasets, e.g. HMDB51/UCF101.
Online Signature Verification using Deep Representation: A new Descriptor
Jun 24, 2018
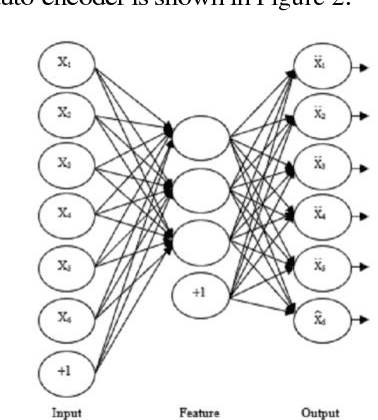
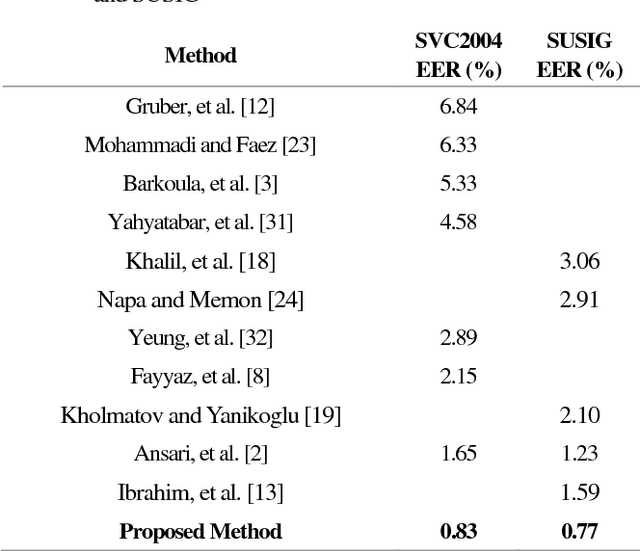
This paper presents an accurate method for verifying online signatures. The main difficulty of signature verification come from: (1) Lacking enough training samples (2) The methods must be spatial change invariant. To deal with these difficulties and modeling the signatures efficiently, we propose a method that a one-class classifier per each user is built on discriminative features. First, we pre-train a sparse auto-encoder using a large number of unlabeled signatures, then we applied the discriminative features, which are learned by auto-encoder to represent the training and testing signatures as a self-thought learning method (i.e. we have introduced a signature descriptor). Finally, user's signatures are modeled and classified using a one-class classifier. The proposed method is independent on signature datasets thanks to self-taught learning. The experimental results indicate significant error reduction and accuracy enhancement in comparison with state-of-the-art methods on SVC2004 and SUSIG datasets.
Semantic Video Segmentation: A Review on Recent Approaches
Jun 16, 2018
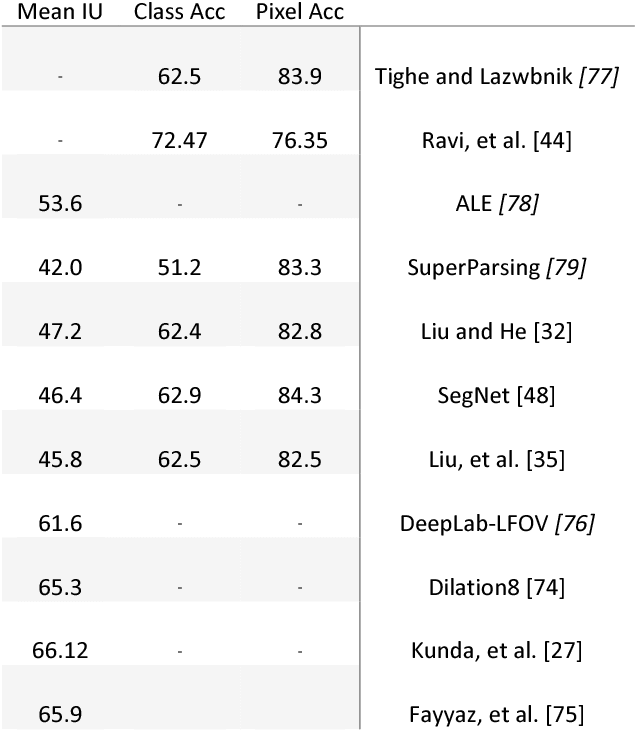

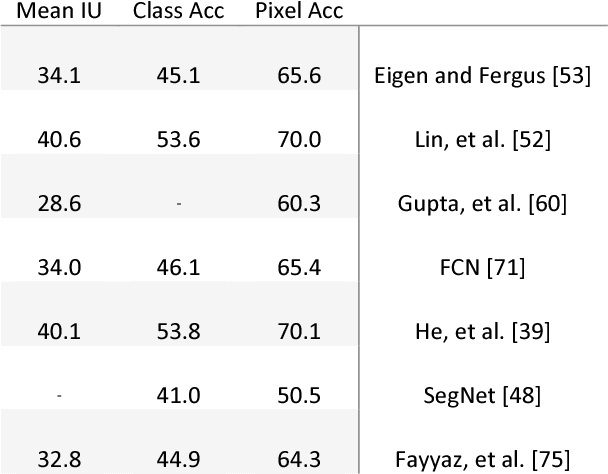
This paper gives an overview on semantic segmentation consists of an explanation of this field, it's status and relation with other vision fundamental tasks, different datasets and common evaluation parameters that have been used by researchers. This survey also includes an overall review on a variety of recent approaches (RDF, MRF, CRF, etc.) and their advantages and challenges and shows the superiority of CNN-based semantic segmentation systems on CamVid and NYUDv2 datasets. In addition, some areas that is ideal for future work have mentioned.
Towards Principled Design of Deep Convolutional Networks: Introducing SimpNet
Feb 17, 2018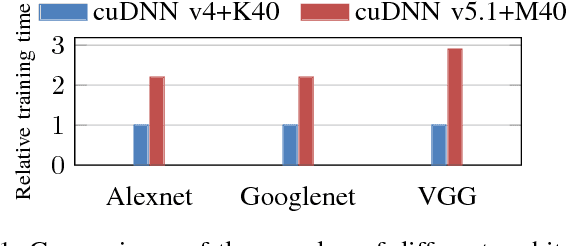
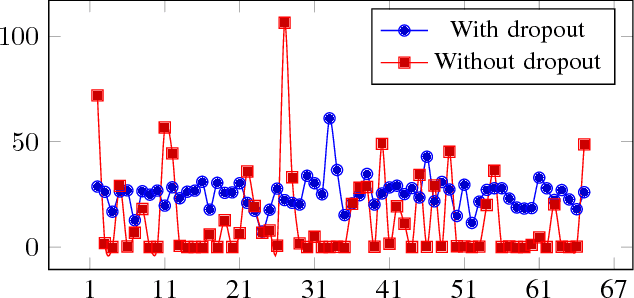


Major winning Convolutional Neural Networks (CNNs), such as VGGNet, ResNet, DenseNet, \etc, include tens to hundreds of millions of parameters, which impose considerable computation and memory overheads. This limits their practical usage in training and optimizing for real-world applications. On the contrary, light-weight architectures, such as SqueezeNet, are being proposed to address this issue. However, they mainly suffer from low accuracy, as they have compromised between the processing power and efficiency. These inefficiencies mostly stem from following an ad-hoc designing procedure. In this work, we discuss and propose several crucial design principles for an efficient architecture design and elaborate intuitions concerning different aspects of the design procedure. Furthermore, we introduce a new layer called {\it SAF-pooling} to improve the generalization power of the network while keeping it simple by choosing best features. Based on such principles, we propose a simple architecture called {\it SimpNet}. We empirically show that SimpNet provides a good trade-off between the computation/memory efficiency and the accuracy solely based on these primitive but crucial principles. SimpNet outperforms the deeper and more complex architectures such as VGGNet, ResNet, WideResidualNet \etc, on several well-known benchmarks, while having 2 to 25 times fewer number of parameters and operations. We obtain state-of-the-art results (in terms of a balance between the accuracy and the number of involved parameters) on standard datasets, such as CIFAR10, CIFAR100, MNIST and SVHN. The implementations are available at \href{url}{https://github.com/Coderx7/SimpNet}.
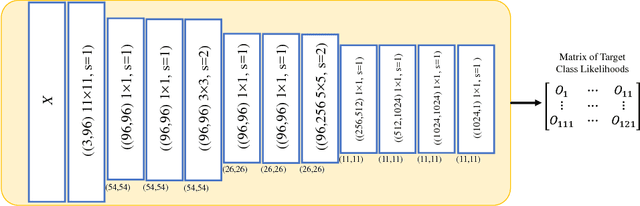
Lets keep it simple, Using simple architectures to outperform deeper and more complex architectures
Feb 14, 2018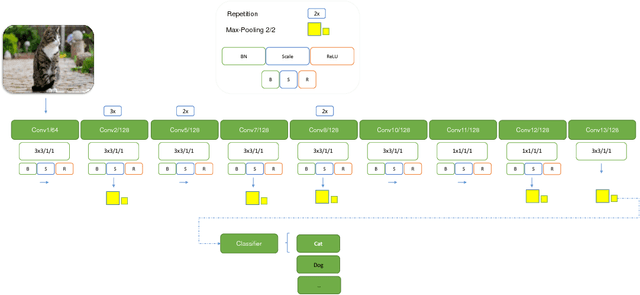

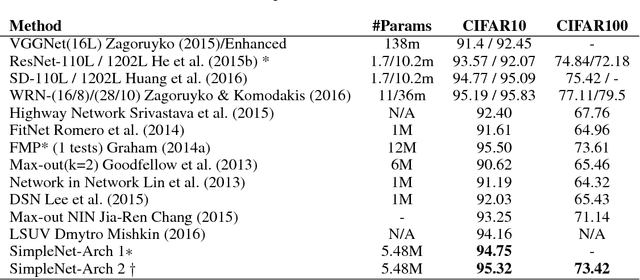
Major winning Convolutional Neural Networks (CNNs), such as AlexNet, VGGNet, ResNet, GoogleNet, include tens to hundreds of millions of parameters, which impose considerable computation and memory overhead. This limits their practical use for training, optimization and memory efficiency. On the contrary, light-weight architectures, being proposed to address this issue, mainly suffer from low accuracy. These inefficiencies mostly stem from following an ad hoc procedure. We propose a simple architecture, called SimpleNet, based on a set of designing principles, with which we empirically show, a well-crafted yet simple and reasonably deep architecture can perform on par with deeper and more complex architectures. SimpleNet provides a good tradeoff between the computation/memory efficiency and the accuracy. Our simple 13-layer architecture outperforms most of the deeper and complex architectures to date such as VGGNet, ResNet, and GoogleNet on several well-known benchmarks while having 2 to 25 times fewer number of parameters and operations. This makes it very handy for embedded system or system with computational and memory limitations. We achieved state-of-the-art result on CIFAR10 outperforming several heavier architectures, near state of the art on MNIST and competitive results on CIFAR100 and SVHN. Models are made available at: https://github.com/Coderx7/SimpleNet