 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemLLM: Finetuning LLMs to Use An Explicit Read-Write Memory
Apr 17, 2024



While current large language models (LLMs) demonstrate some capabilities in knowledge-intensive tasks, they are limited by relying on their parameters as an implicit storage mechanism. As a result, they struggle with infrequent knowledge and temporal degradation. In addition, the uninterpretable nature of parametric memorization makes it challenging to understand and prevent hallucination. Parametric memory pools and model editing are only partial solutions. Retrieval Augmented Generation (RAG) $\unicode{x2013}$ though non-parametric $\unicode{x2013}$ has its own limitations: it lacks structure, complicates interpretability and makes it hard to effectively manage stored knowledge. In this paper, we introduce MemLLM, a novel method of enhancing LLMs by integrating a structured and explicit read-and-write memory module. MemLLM tackles the aforementioned challenges by enabling dynamic interaction with the memory and improving the LLM's capabilities in using stored knowledge. Our experiments indicate that MemLLM enhances the LLM's performance and interpretability, in language modeling in general and knowledge-intensive tasks in particular. We see MemLLM as an important step towards making LLMs more grounded and factual through memory augmentation.
DecompX: Explaining Transformers Decisions by Propagating Token Decomposition
Jun 05, 2023



An emerging solution for explaining Transformer-based models is to use vector-based analysis on how the representations are formed. However, providing a faithful vector-based explanation for a multi-layer model could be challenging in three aspects: (1) Incorporating all components into the analysis, (2) Aggregating the layer dynamics to determine the information flow and mixture throughout the entire model, and (3) Identifying the connection between the vector-based analysis and the model's predictions. In this paper, we present DecompX to tackle these challenges. DecompX is based on the construction of decomposed token representations and their successive propagation throughout the model without mixing them in between layers. Additionally, our proposal provides multiple advantages over existing solutions for its inclusion of all encoder components (especially nonlinear feed-forward networks) and the classification head. The former allows acquiring precise vectors while the latter transforms the decomposition into meaningful prediction-based values, eliminating the need for norm- or summation-based vector aggregation. According to the standard faithfulness evaluations, DecompX consistently outperforms existing gradient-based and vector-based approaches on various datasets. Our code is available at https://github.com/mohsenfayyaz/DecompX.
RET-LLM: Towards a General Read-Write Memory for Large Language Models
May 23, 2023



Large language models (LLMs) have significantly advanced the field of natural language processing (NLP) through their extensive parameters and comprehensive data utilization. However, existing LLMs lack a dedicated memory unit, limiting their ability to explicitly store and retrieve knowledge for various tasks. In this paper, we propose RET-LLM a novel framework that equips LLMs with a general write-read memory unit, allowing them to extract, store, and recall knowledge from the text as needed for task performance. Inspired by Davidsonian semantics theory, we extract and save knowledge in the form of triplets. The memory unit is designed to be scalable, aggregatable, updatable, and interpretable. Through qualitative evaluations, we demonstrate the superiority of our proposed framework over baseline approaches in question answering tasks. Moreover, our framework exhibits robust performance in handling temporal-based question answering tasks, showcasing its ability to effectively manage time-dependent information.
Diffusion Models for Medical Image Analysis: A Comprehensive Survey
Nov 14, 2022



Denoising diffusion models, a class of generative models, have garnered immense interest lately in various deep-learning problems. A diffusion probabilistic model defines a forward diffusion stage where the input data is gradually perturbed over several steps by adding Gaussian noise and then learns to reverse the diffusion process to retrieve the desired noise-free data from noisy data samples. Diffusion models are widely appreciated for their strong mode coverage and quality of the generated samples despite their known computational burdens. Capitalizing on the advances in computer vision, the field of medical imaging has also observed a growing interest in diffusion models. To help the researcher navigate this profusion, this survey intends to provide a comprehensive overview of diffusion models in the discipline of medical image analysis. Specifically, we introduce the solid theoretical foundation and fundamental concepts behind diffusion models and the three generic diffusion modelling frameworks: diffusion probabilistic models, noise-conditioned score networks, and stochastic differential equations. Then, we provide a systematic taxonomy of diffusion models in the medical domain and propose a multi-perspective categorization based on their application, imaging modality, organ of interest, and algorithms. To this end, we cover extensive applications of diffusion models in the medical domain. Furthermore, we emphasize the practical use case of some selected approaches, and then we discuss the limitations of the diffusion models in the medical domain and propose several directions to fulfill the demands of this field. Finally, we gather the overviewed studies with their available open-source implementations at https://github.com/amirhossein-kz/Awesome-Diffusion-Models-in-Medical-Imaging.
BERT on a Data Diet: Finding Important Examples by Gradient-Based Pruning
Nov 10, 2022Current pre-trained language models rely on large datasets for achieving state-of-the-art performance. However, past research has shown that not all examples in a dataset are equally important during training. In fact, it is sometimes possible to prune a considerable fraction of the training set while maintaining the test performance. Established on standard vision benchmarks, two gradient-based scoring metrics for finding important examples are GraNd and its estimated version, EL2N. In this work, we employ these two metrics for the first time in NLP. We demonstrate that these metrics need to be computed after at least one epoch of fine-tuning and they are not reliable in early steps. Furthermore, we show that by pruning a small portion of the examples with the highest GraNd/EL2N scores, we can not only preserve the test accuracy, but also surpass it. This paper details adjustments and implementation choices which enable GraNd and EL2N to be applied to NLP.
GlobEnc: Quantifying Global Token Attribution by Incorporating the Whole Encoder Layer in Transformers
May 06, 2022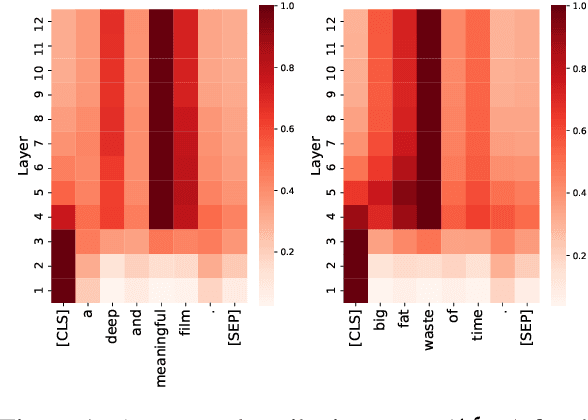
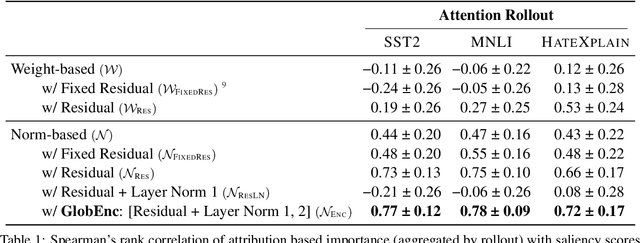
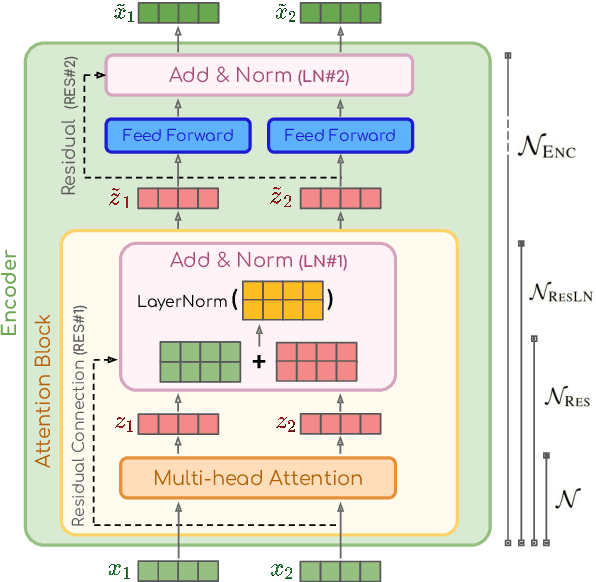

There has been a growing interest in interpreting the underlying dynamics of Transformers. While self-attention patterns were initially deemed as the primary option, recent studies have shown that integrating other components can yield more accurate explanations. This paper introduces a novel token attribution analysis method that incorporates all the components in the encoder block and aggregates this throughout layers. Through extensive quantitative and qualitative experiments, we demonstrate that our method can produce faithful and meaningful global token attributions. Our experiments reveal that incorporating almost every encoder component results in increasingly more accurate analysis in both local (single layer) and global (the whole model) settings. Our global attribution analysis significantly outperforms previous methods on various tasks regarding correlation with gradient-based saliency scores. Our code is freely available at https://github.com/mohsenfayyaz/GlobEnc.
Metaphors in Pre-Trained Language Models: Probing and Generalization Across Datasets and Languages
Mar 26, 2022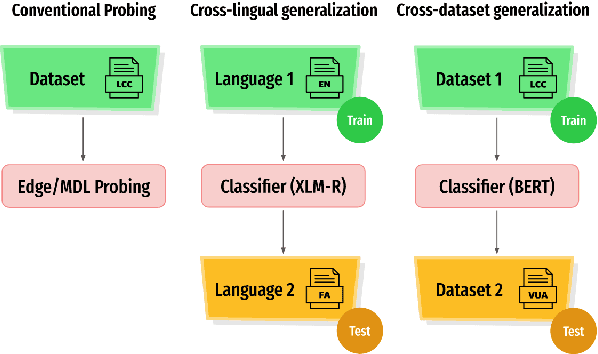

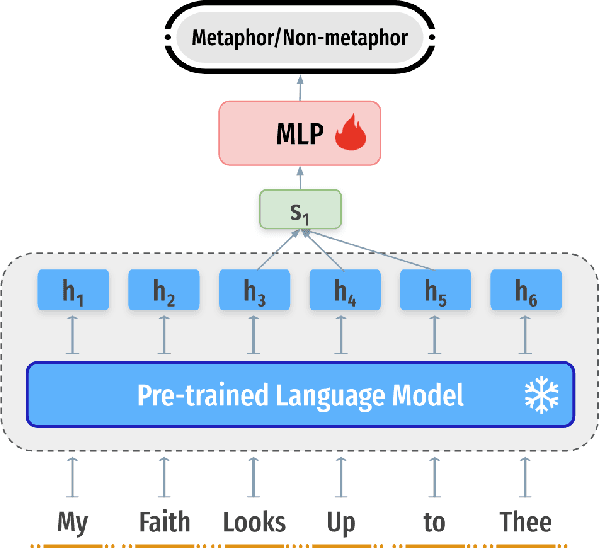
Human languages are full of metaphorical expressions. Metaphors help people understand the world by connecting new concepts and domains to more familiar ones. Large pre-trained language models (PLMs) are therefore assumed to encode metaphorical knowledge useful for NLP systems. In this paper, we investigate this hypothesis for PLMs, by probing metaphoricity information in their encodings, and by measuring the cross-lingual and cross-dataset generalization of this information. We present studies in multiple metaphor detection datasets and in four languages (i.e., English, Spanish, Russian, and Farsi). Our extensive experiments suggest that contextual representations in PLMs do encode metaphorical knowledge, and mostly in their middle layers. The knowledge is transferable between languages and datasets, especially when the annotation is consistent across training and testing sets. Our findings give helpful insights for both cognitive and NLP scientists.
ATS: Adaptive Token Sampling For Efficient Vision Transformers
Nov 30, 2021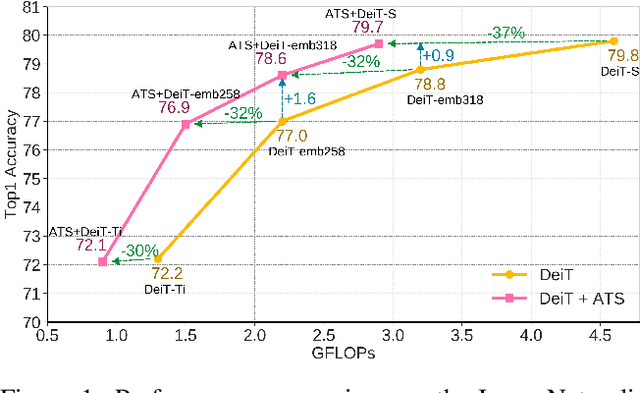
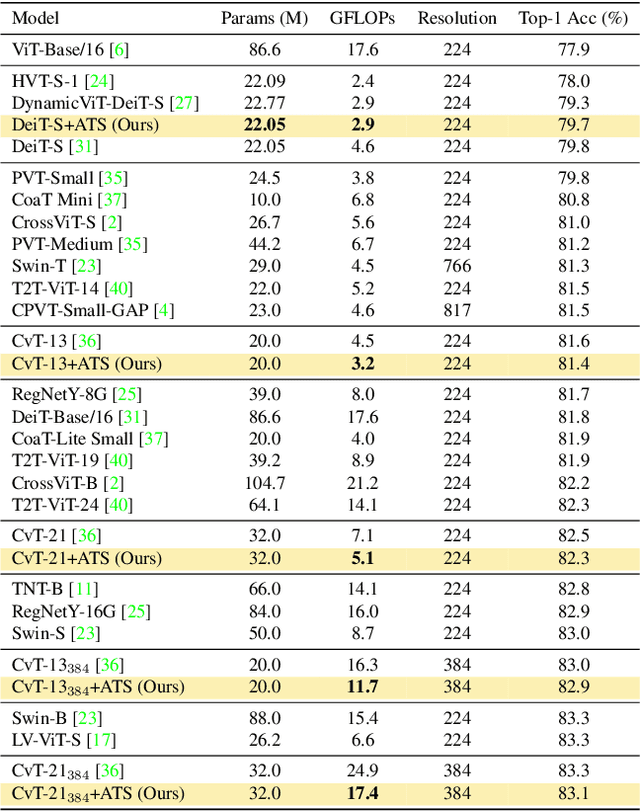
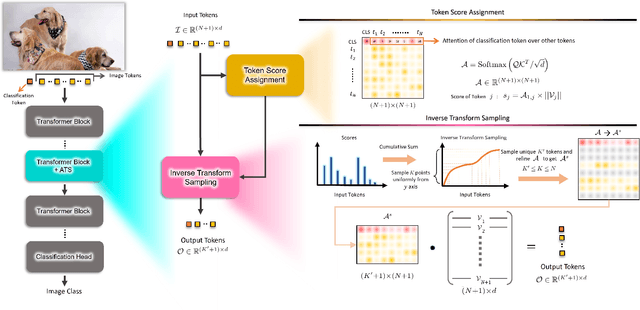

While state-of-the-art vision transformer models achieve promising results for image classification, they are computationally very expensive and require many GFLOPs. Although the GFLOPs of a vision transformer can be decreased by reducing the number of tokens in the network, there is no setting that is optimal for all input images. In this work, we, therefore, introduce a differentiable parameter-free Adaptive Token Sampling (ATS) module, which can be plugged into any existing vision transformer architecture. ATS empowers vision transformers by scoring and adaptively sampling significant tokens. As a result, the number of tokens is not anymore static but it varies for each input image. By integrating ATS as an additional layer within current transformer blocks, we can convert them into much more efficient vision transformers with an adaptive number of tokens. Since ATS is a parameter-free module, it can be added to off-the-shelf pretrained vision transformers as a plug-and-play module, thus reducing their GFLOPs without any additional training. However, due to its differentiable design, one can also train a vision transformer equipped with ATS. We evaluate our module on the ImageNet dataset by adding it to multiple state-of-the-art vision transformers. Our evaluations show that the proposed module improves the state-of-the-art by reducing the computational cost (GFLOPs) by 37% while preserving the accuracy.
Taylor Swift: Taylor Driven Temporal Modeling for Swift Future Frame Prediction
Oct 27, 2021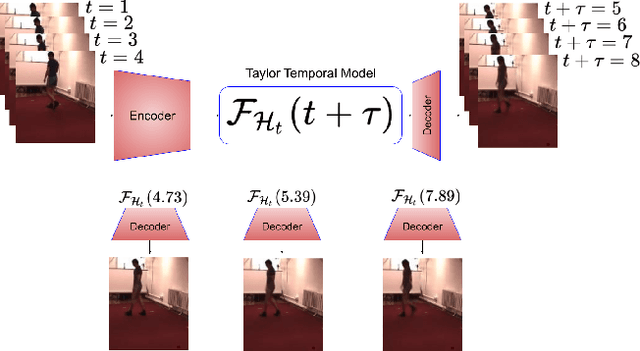
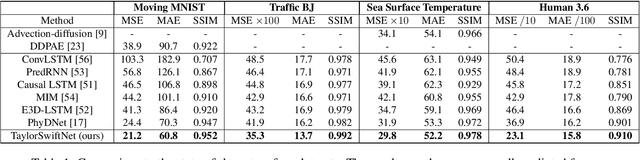
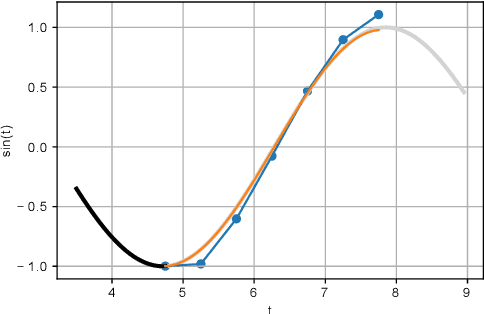

While recurrent neural networks (RNNs) demonstrate outstanding capabilities in future video frame prediction, they model dynamics in a discrete time space and sequentially go through all frames until the desired future temporal step is reached. RNNs are therefore prone to accumulate the error as the number of future frames increases. In contrast, partial differential equations (PDEs) model physical phenomena like dynamics in continuous time space, however, current PDE-based approaches discretize the PDEs using e.g., the forward Euler method. In this work, we therefore propose to approximate the motion in a video by a continuous function using the Taylor series. To this end, we introduce TayloSwiftNet, a novel convolutional neural network that learns to estimate the higher order terms of the Taylor series for a given input video. TayloSwiftNet can swiftly predict any desired future frame in just one forward pass and change the temporal resolution on-the-fly. The experimental results on various datasets demonstrate the superiority of our model.
Long Short View Feature Decomposition via Contrastive Video Representation Learning
Sep 23, 2021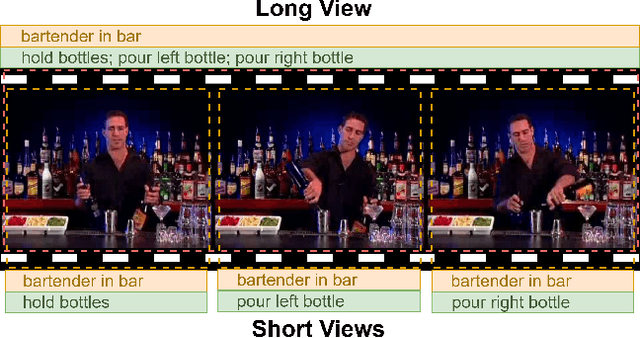
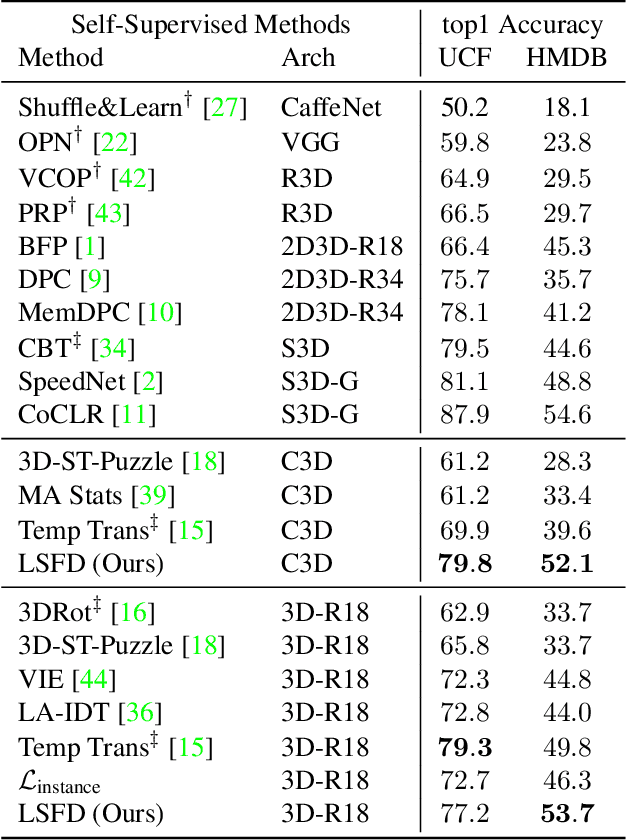
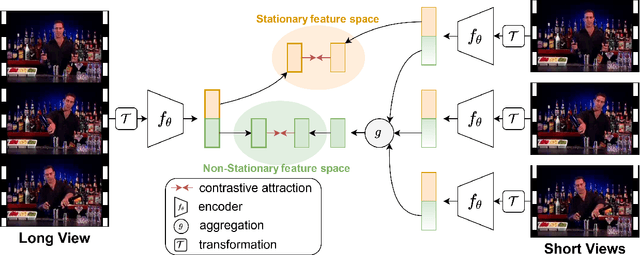
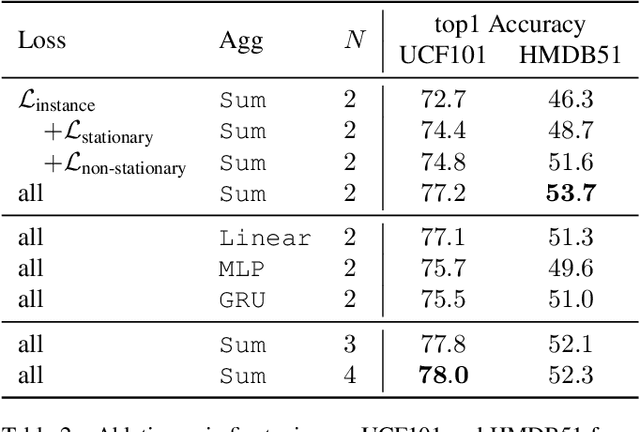
Self-supervised video representation methods typically focus on the representation of temporal attributes in videos. However, the role of stationary versus non-stationary attributes is less explored: Stationary features, which remain similar throughout the video, enable the prediction of video-level action classes. Non-stationary features, which represent temporally varying attributes, are more beneficial for downstream tasks involving more fine-grained temporal understanding, such as action segmentation. We argue that a single representation to capture both types of features is sub-optimal, and propose to decompose the representation space into stationary and non-stationary features via contrastive learning from long and short views, i.e. long video sequences and their shorter sub-sequences. Stationary features are shared between the short and long views, while non-stationary features aggregate the short views to match the corresponding long view. To empirically verify our approach, we demonstrate that our stationary features work particularly well on an action recognition downstream task, while our non-stationary features perform better on action segmentation. Furthermore, we analyse the learned representations and find that stationary features capture more temporally stable, static attributes, while non-stationary features encompass more temporally varying ones.