 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Transformers are Parameter-Efficient Audio-Visual Learners
Dec 15, 2022



Vision transformers (ViTs) have achieved impressive results on various computer vision tasks in the last several years. In this work, we study the capability of frozen ViTs, pretrained only on visual data, to generalize to audio-visual data without finetuning any of its original parameters. To do so, we propose a latent audio-visual hybrid (LAVISH) adapter that adapts pretrained ViTs to audio-visual tasks by injecting a small number of trainable parameters into every layer of a frozen ViT. To efficiently fuse visual and audio cues, our LAVISH adapter uses a small set of latent tokens, which form an attention bottleneck, thus, eliminating the quadratic cost of standard cross-attention. Compared to the existing modality-specific audio-visual methods, our approach achieves competitive or even better performance on various audio-visual tasks while using fewer tunable parameters and without relying on costly audio pretraining or external audio encoders. Our code is available at https://genjib.github.io/project_page/LAVISH/
VindLU: A Recipe for Effective Video-and-Language Pretraining
Dec 09, 2022



The last several years have witnessed remarkable progress in video-and-language (VidL) understanding. However, most modern VidL approaches use complex and specialized model architectures and sophisticated pretraining protocols, making the reproducibility, analysis and comparisons of these frameworks difficult. Hence, instead of proposing yet another new VidL model, this paper conducts a thorough empirical study demystifying the most important factors in the VidL model design. Among the factors that we investigate are (i) the spatiotemporal architecture design, (ii) the multimodal fusion schemes, (iii) the pretraining objectives, (iv) the choice of pretraining data, (v) pretraining and finetuning protocols, and (vi) dataset and model scaling. Our empirical study reveals that the most important design factors include: temporal modeling, video-to-text multimodal fusion, masked modeling objectives, and joint training on images and videos. Using these empirical insights, we then develop a step-by-step recipe, dubbed VindLU, for effective VidL pretraining. Our final model trained using our recipe achieves comparable or better than state-of-the-art results on several VidL tasks without relying on external CLIP pretraining. In particular, on the text-to-video retrieval task, our approach obtains 61.2% on DiDeMo, and 55.0% on ActivityNet, outperforming current SOTA by 7.8% and 6.1% respectively. Furthermore, our model also obtains state-of-the-art video question-answering results on ActivityNet-QA, MSRVTT-QA, MSRVTT-MC and TVQA. Our code and pretrained models are publicly available at: https://github.com/klauscc/VindLU.
Mutual Exclusivity Training and Primitive Augmentation to Induce Compositionality
Nov 28, 2022Recent datasets expose the lack of the systematic generalization ability in standard sequence-to-sequence models. In this work, we analyze this behavior of seq2seq models and identify two contributing factors: a lack of mutual exclusivity bias (i.e., a source sequence already mapped to a target sequence is less likely to be mapped to other target sequences), and the tendency to memorize whole examples rather than separating structures from contents. We propose two techniques to address these two issues respectively: Mutual Exclusivity Training that prevents the model from producing seen generations when facing novel, unseen examples via an unlikelihood-based loss; and prim2primX data augmentation that automatically diversifies the arguments of every syntactic function to prevent memorizing and provide a compositional inductive bias without exposing test-set data. Combining these two techniques, we show substantial empirical improvements using standard sequence-to-sequence models (LSTMs and Transformers) on two widely-used compositionality datasets: SCAN and COGS. Finally, we provide analysis characterizing the improvements as well as the remaining challenges, and provide detailed ablations of our method. Our code is available at https://github.com/owenzx/met-primaug
Perceiver-VL: Efficient Vision-and-Language Modeling with Iterative Latent Attention
Nov 21, 2022We present Perceiver-VL, a vision-and-language framework that efficiently handles high-dimensional multimodal inputs such as long videos and text. Powered by the iterative latent cross-attention of Perceiver, our framework scales with linear complexity, in contrast to the quadratic complexity of self-attention used in many state-of-the-art transformer-based models. To further improve the efficiency of our framework, we also study applying LayerDrop on cross-attention layers and introduce a mixed-stream architecture for cross-modal retrieval. We evaluate Perceiver-VL on diverse video-text and image-text benchmarks, where Perceiver-VL achieves the lowest GFLOPs and latency while maintaining competitive performance. In addition, we also provide comprehensive analyses of various aspects of our framework, including pretraining data, scalability of latent size and input size, dropping cross-attention layers at inference to reduce latency, modality aggregation strategy, positional encoding, and weight initialization strategy. Our code and checkpoints are available at: https://github.com/zinengtang/Perceiver_VL
Evaluating the Factual Consistency of Large Language Models Through Summarization
Nov 15, 2022



While large language models (LLMs) have proven to be effective on a large variety of tasks, they are also known to hallucinate information. To measure whether an LLM prefers factually consistent continuations of its input, we propose a new benchmark called FIB(Factual Inconsistency Benchmark) that focuses on the task of summarization. Specifically, our benchmark involves comparing the scores an LLM assigns to a factually consistent versus a factually inconsistent summary for an input news article. For factually consistent summaries, we use human-written reference summaries that we manually verify as factually consistent. To generate summaries that are factually inconsistent, we generate summaries from a suite of summarization models that we have manually annotated as factually inconsistent. A model's factual consistency is then measured according to its accuracy, i.e.\ the proportion of documents where it assigns a higher score to the factually consistent summary. To validate the usefulness of FIB, we evaluate 23 large language models ranging from 1B to 176B parameters from six different model families including BLOOM and OPT. We find that existing LLMs generally assign a higher score to factually consistent summaries than to factually inconsistent summaries. However, if the factually inconsistent summaries occur verbatim in the document, then LLMs assign a higher score to these factually inconsistent summaries than factually consistent summaries. We validate design choices in our benchmark including the scoring method and source of distractor summaries. Our code and benchmark data can be found at https://github.com/r-three/fib.
Are Hard Examples also Harder to Explain? A Study with Human and Model-Generated Explanations
Nov 14, 2022Recent work on explainable NLP has shown that few-shot prompting can enable large pretrained language models (LLMs) to generate grammatical and factual natural language explanations for data labels. In this work, we study the connection between explainability and sample hardness by investigating the following research question - "Are LLMs and humans equally good at explaining data labels for both easy and hard samples?" We answer this question by first collecting human-written explanations in the form of generalizable commonsense rules on the task of Winograd Schema Challenge (Winogrande dataset). We compare these explanations with those generated by GPT-3 while varying the hardness of the test samples as well as the in-context samples. We observe that (1) GPT-3 explanations are as grammatical as human explanations regardless of the hardness of the test samples, (2) for easy examples, GPT-3 generates highly supportive explanations but human explanations are more generalizable, and (3) for hard examples, human explanations are significantly better than GPT-3 explanations both in terms of label-supportiveness and generalizability judgements. We also find that hardness of the in-context examples impacts the quality of GPT-3 explanations. Finally, we show that the supportiveness and generalizability aspects of human explanations are also impacted by sample hardness, although by a much smaller margin than models. Supporting code and data are available at https://github.com/swarnaHub/ExplanationHardness
Evaluating and Improving Factuality in Multimodal Abstractive Summarization
Nov 04, 2022Current metrics for evaluating factuality for abstractive document summarization have achieved high correlations with human judgment, but they do not account for the vision modality and thus are not adequate for vision-and-language summarization. We propose CLIPBERTScore, a simple weighted combination of CLIPScore and BERTScore to leverage the robustness and strong factuality detection performance between image-summary and document-summary, respectively. Next, due to the lack of meta-evaluation benchmarks to evaluate the quality of multimodal factuality metrics, we collect human judgments of factuality with respect to documents and images. We show that this simple combination of two metrics in the zero-shot setting achieves higher correlations than existing factuality metrics for document summarization, outperforms an existing multimodal summarization metric, and performs competitively with strong multimodal factuality metrics specifically fine-tuned for the task. Our thorough analysis demonstrates the robustness and high correlation of CLIPBERTScore and its components on four factuality metric-evaluation benchmarks. Finally, we demonstrate two practical downstream applications of our CLIPBERTScore metric: for selecting important images to focus on during training, and as a reward for reinforcement learning to improve factuality of multimodal summary generation w.r.t automatic and human evaluation. Our data and code are publicly available at https://github.com/meetdavidwan/faithful-multimodal-summ
Exclusive Supermask Subnetwork Training for Continual Learning
Oct 18, 2022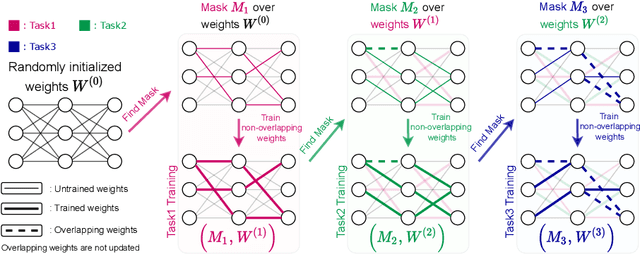
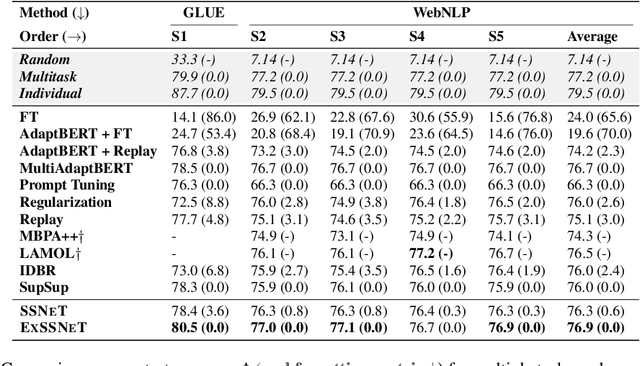
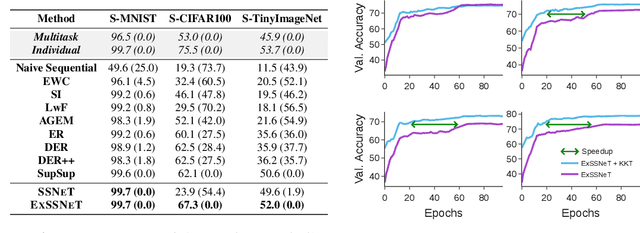
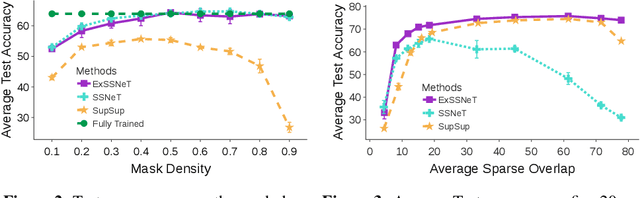
Continual Learning (CL) methods mainly focus on avoiding catastrophic forgetting and learning representations that are transferable to new tasks. Recently, Wortsman et al. (2020) proposed a CL method, SupSup, which uses a randomly initialized, fixed base network (model) and finds a supermask for each new task that selectively keeps or removes each weight to produce a subnetwork. They prevent forgetting as the network weights are not being updated. Although there is no forgetting, the performance of the supermask is sub-optimal because fixed weights restrict its representational power. Furthermore, there is no accumulation or transfer of knowledge inside the model when new tasks are learned. Hence, we propose ExSSNeT (Exclusive Supermask SubNEtwork Training), which performs exclusive and non-overlapping subnetwork weight training. This avoids conflicting updates to the shared weights by subsequent tasks to improve performance while still preventing forgetting. Furthermore, we propose a novel KNN-based Knowledge Transfer (KKT) module that dynamically initializes a new task's mask based on previous tasks for improving knowledge transfer. We demonstrate that ExSSNeT outperforms SupSup and other strong previous methods on both text classification and vision tasks while preventing forgetting. Moreover, ExSSNeT is particularly advantageous for sparse masks that activate 2-10% of the model parameters, resulting in an average improvement of 8.3% over SupSup. Additionally, ExSSNeT scales to a large number of tasks (100), and our KKT module helps to learn new tasks faster while improving overall performance. Our code is available at https://github.com/prateeky2806/exessnet
TVLT: Textless Vision-Language Transformer
Sep 28, 2022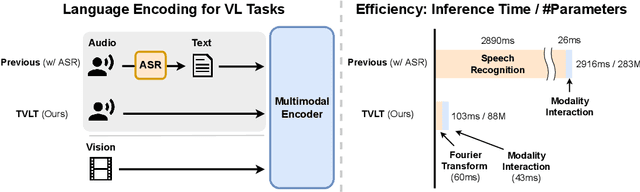
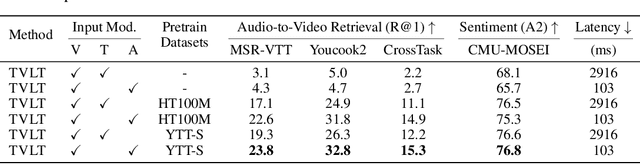

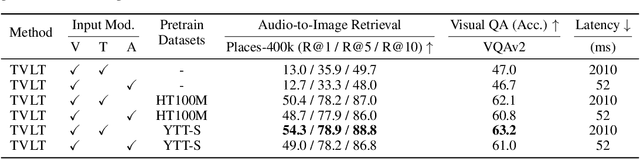
In this work, we present the Textless Vision-Language Transformer (TVLT), where homogeneous transformer blocks take raw visual and audio inputs for vision-and-language representation learning with minimal modality-specific design, and do not use text-specific modules such as tokenization or automatic speech recognition (ASR). TVLT is trained by reconstructing masked patches of continuous video frames and audio spectrograms (masked autoencoding) and contrastive modeling to align video and audio. TVLT attains performance comparable to its text-based counterpart, on various multimodal tasks, such as visual question answering, image retrieval, video retrieval, and multimodal sentiment analysis, with 28x faster inference speed and only 1/3 of the parameters. Our findings suggest the possibility of learning compact and efficient visual-linguistic representations from low-level visual and audio signals without assuming the prior existence of text. Our code and checkpoints are available at: https://github.com/zinengtang/TVLT
Summarization Programs: Interpretable Abstractive Summarization with Neural Modular Trees
Sep 21, 2022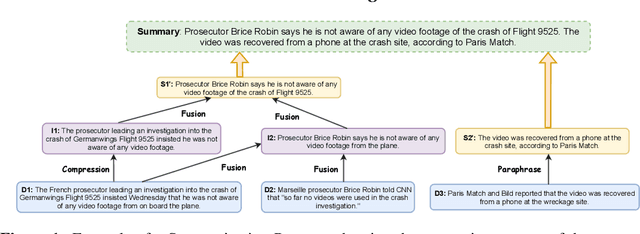
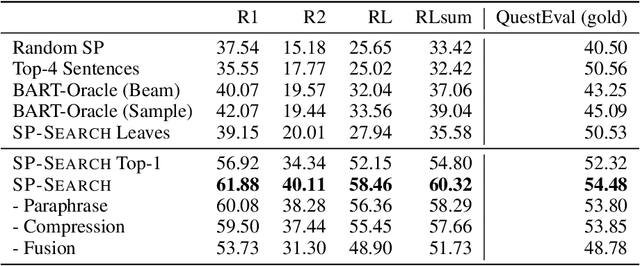
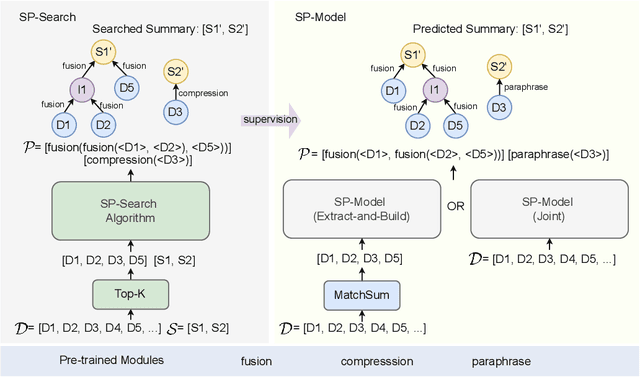
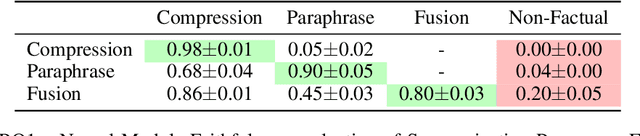
Current abstractive summarization models either suffer from a lack of clear interpretability or provide incomplete rationales by only highlighting parts of the source document. To this end, we propose the Summarization Program (SP), an interpretable modular framework consisting of an (ordered) list of binary trees, each encoding the step-by-step generative process of an abstractive summary sentence from the source document. A Summarization Program contains one root node per summary sentence, and a distinct tree connects each summary sentence (root node) to the document sentences (leaf nodes) from which it is derived, with the connecting nodes containing intermediate generated sentences. Edges represent different modular operations involved in summarization such as sentence fusion, compression, and paraphrasing. We first propose an efficient best-first search method over neural modules, SP-Search that identifies SPs for human summaries by directly optimizing for ROUGE scores. Next, using these programs as automatic supervision, we propose seq2seq models that generate Summarization Programs, which are then executed to obtain final summaries. We demonstrate that SP-Search effectively represents the generative process behind human summaries using modules that are typically faithful to their intended behavior. We also conduct a simulation study to show that Summarization Programs improve the interpretability of summarization models by allowing humans to better simulate model reasoning. Summarization Programs constitute a promising step toward interpretable and modular abstractive summarization, a complex task previously addressed primarily through blackbox end-to-end neural systems. Our code is available at https://github.com/swarnaHub/SummarizationPrograms