 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGVdoc: Graph-based Visual Document Classification
May 26, 2023



The robustness of a model for real-world deployment is decided by how well it performs on unseen data and distinguishes between in-domain and out-of-domain samples. Visual document classifiers have shown impressive performance on in-distribution test sets. However, they tend to have a hard time correctly classifying and differentiating out-of-distribution examples. Image-based classifiers lack the text component, whereas multi-modality transformer-based models face the token serialization problem in visual documents due to their diverse layouts. They also require a lot of computing power during inference, making them impractical for many real-world applications. We propose, GVdoc, a graph-based document classification model that addresses both of these challenges. Our approach generates a document graph based on its layout, and then trains a graph neural network to learn node and graph embeddings. Through experiments, we show that our model, even with fewer parameters, outperforms state-of-the-art models on out-of-distribution data while retaining comparable performance on the in-distribution test set.
Energy Transformer
Feb 14, 2023



Transformers have become the de facto models of choice in machine learning, typically leading to impressive performance on many applications. At the same time, the architectural development in the transformer world is mostly driven by empirical findings, and the theoretical understanding of their architectural building blocks is rather limited. In contrast, Dense Associative Memory models or Modern Hopfield Networks have a well-established theoretical foundation, but have not yet demonstrated truly impressive practical results. We propose a transformer architecture that replaces the sequence of feedforward transformer blocks with a single large Associative Memory model. Our novel architecture, called Energy Transformer (or ET for short), has many of the familiar architectural primitives that are often used in the current generation of transformers. However, it is not identical to the existing architectures. The sequence of transformer layers in ET is purposely designed to minimize a specifically engineered energy function, which is responsible for representing the relationships between the tokens. As a consequence of this computational principle, the attention in ET is different from the conventional attention mechanism. In this work, we introduce the theoretical foundations of ET, explore it's empirical capabilities using the image completion task, and obtain strong quantitative results on the graph anomaly detection task.
Associative Learning for Network Embedding
Aug 30, 2022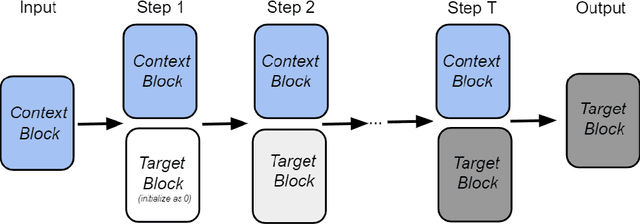
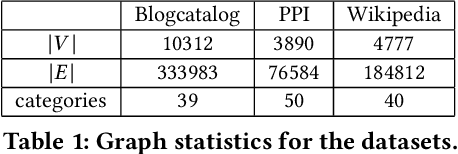
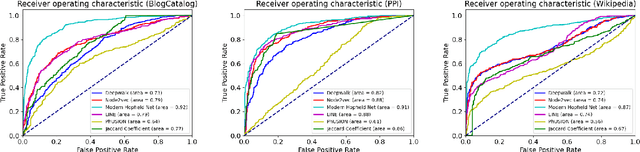

The network embedding task is to represent the node in the network as a low-dimensional vector while incorporating the topological and structural information. Most existing approaches solve this problem by factorizing a proximity matrix, either directly or implicitly. In this work, we introduce a network embedding method from a new perspective, which leverages Modern Hopfield Networks (MHN) for associative learning. Our network learns associations between the content of each node and that node's neighbors. These associations serve as memories in the MHN. The recurrent dynamics of the network make it possible to recover the masked node, given that node's neighbors. Our proposed method is evaluated on different downstream tasks such as node classification and linkage prediction. The results show competitive performance compared to the common matrix factorization techniques and deep learning based methods.
Towards Neural Numeric-To-Text Generation From Temporal Personal Health Data
Jul 11, 2022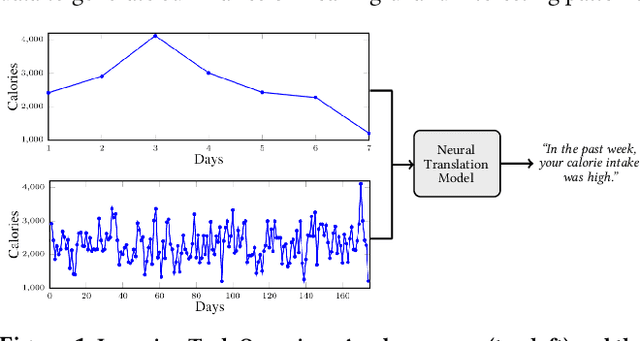
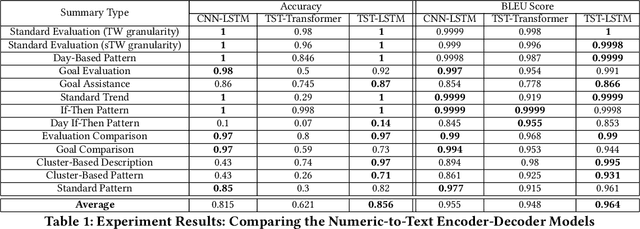
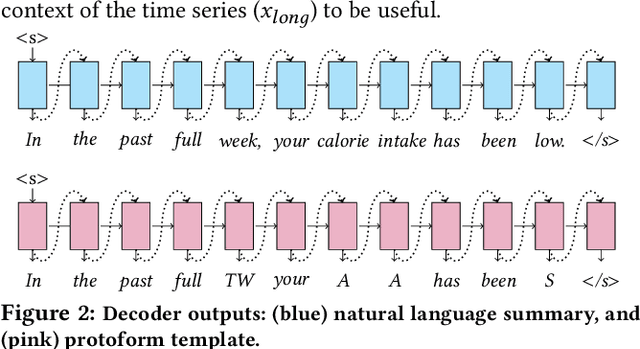
With an increased interest in the production of personal health technologies designed to track user data (e.g., nutrient intake, step counts), there is now more opportunity than ever to surface meaningful behavioral insights to everyday users in the form of natural language. This knowledge can increase their behavioral awareness and allow them to take action to meet their health goals. It can also bridge the gap between the vast collection of personal health data and the summary generation required to describe an individual's behavioral tendencies. Previous work has focused on rule-based time-series data summarization methods designed to generate natural language summaries of interesting patterns found within temporal personal health data. We examine recurrent, convolutional, and Transformer-based encoder-decoder models to automatically generate natural language summaries from numeric temporal personal health data. We showcase the effectiveness of our models on real user health data logged in MyFitnessPal and show that we can automatically generate high-quality natural language summaries. Our work serves as a first step towards the ambitious goal of automatically generating novel and meaningful temporal summaries from personal health data.
FETILDA: An Effective Framework For Fin-tuned Embeddings For Long Financial Text Documents
Jun 14, 2022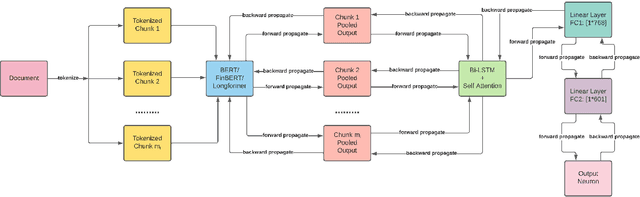
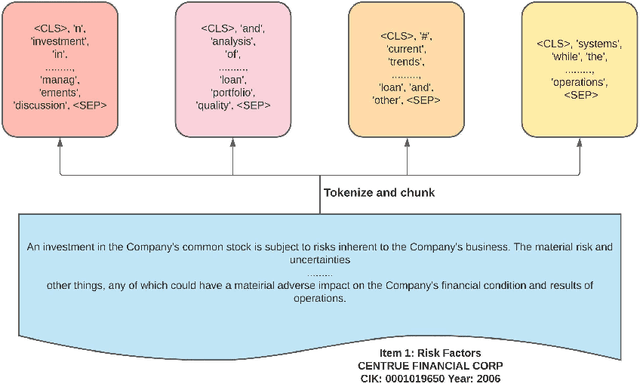

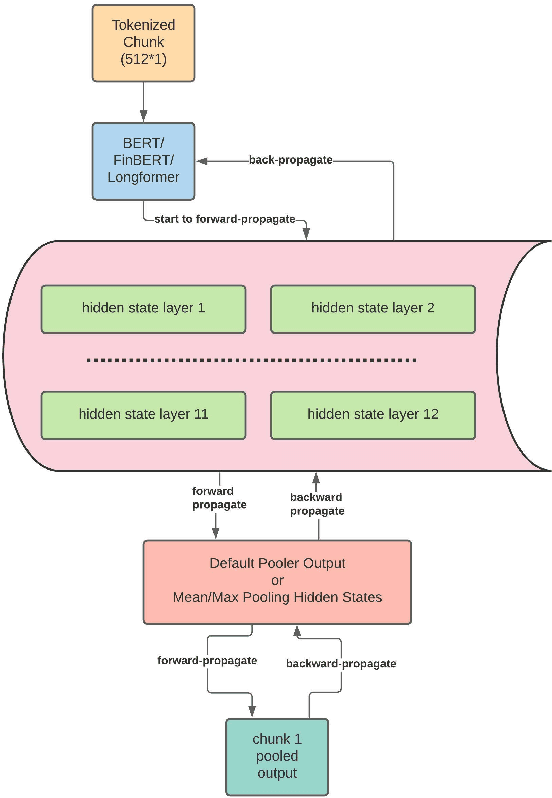
Unstructured data, especially text, continues to grow rapidly in various domains. In particular, in the financial sphere, there is a wealth of accumulated unstructured financial data, such as the textual disclosure documents that companies submit on a regular basis to regulatory agencies, such as the Securities and Exchange Commission (SEC). These documents are typically very long and tend to contain valuable soft information about a company's performance. It is therefore of great interest to learn predictive models from these long textual documents, especially for forecasting numerical key performance indicators (KPIs). Whereas there has been a great progress in pre-trained language models (LMs) that learn from tremendously large corpora of textual data, they still struggle in terms of effective representations for long documents. Our work fills this critical need, namely how to develop better models to extract useful information from long textual documents and learn effective features that can leverage the soft financial and risk information for text regression (prediction) tasks. In this paper, we propose and implement a deep learning framework that splits long documents into chunks and utilizes pre-trained LMs to process and aggregate the chunks into vector representations, followed by self-attention to extract valuable document-level features. We evaluate our model on a collection of 10-K public disclosure reports from US banks, and another dataset of reports submitted by US companies. Overall, our framework outperforms strong baseline methods for textual modeling as well as a baseline regression model using only numerical data. Our work provides better insights into how utilizing pre-trained domain-specific and fine-tuned long-input LMs in representing long documents can improve the quality of representation of textual data, and therefore, help in improving predictive analyses.
Keyphrase Extraction Using Neighborhood Knowledge Based on Word Embeddings
Nov 13, 2021
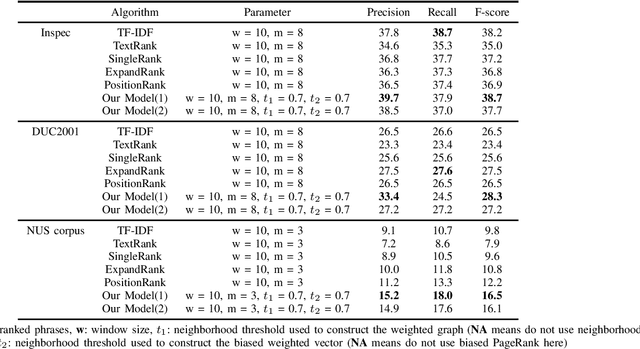
Keyphrase extraction is the task of finding several interesting phrases in a text document, which provide a list of the main topics within the document. Most existing graph-based models use co-occurrence links as cohesion indicators to model the relationship of syntactic elements. However, a word may have different forms of expression within the document, and may have several synonyms as well. Simply using co-occurrence information cannot capture this information. In this paper, we enhance the graph-based ranking model by leveraging word embeddings as background knowledge to add semantic information to the inter-word graph. Our approach is evaluated on established benchmark datasets and empirical results show that the word embedding neighborhood information improves the model performance.
Edge-augmented Graph Transformers: Global Self-attention is Enough for Graphs
Aug 07, 2021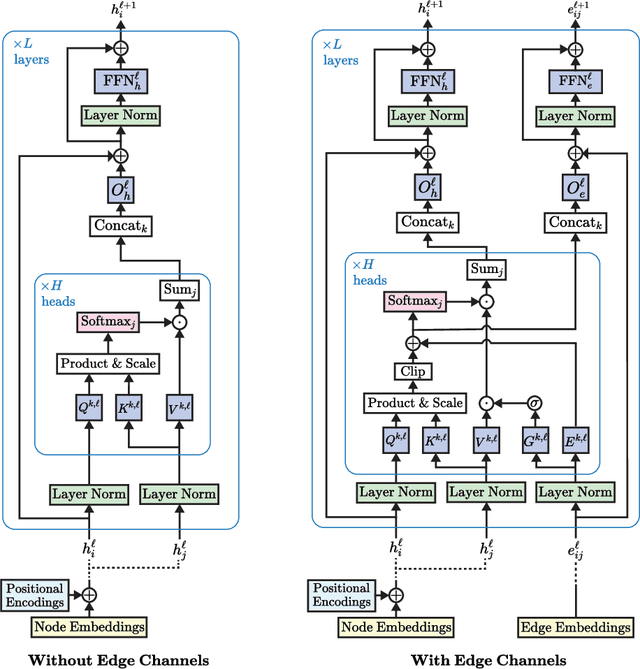
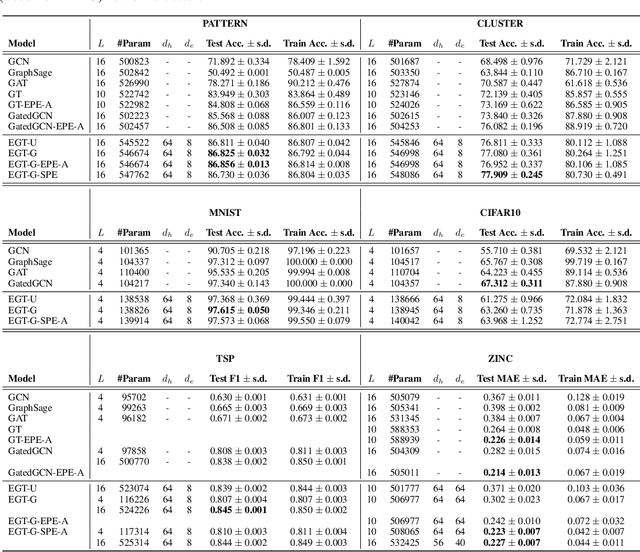
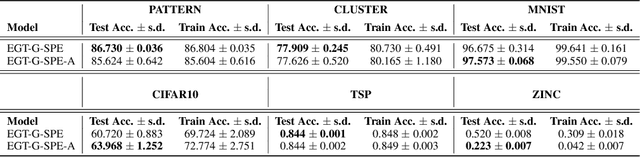
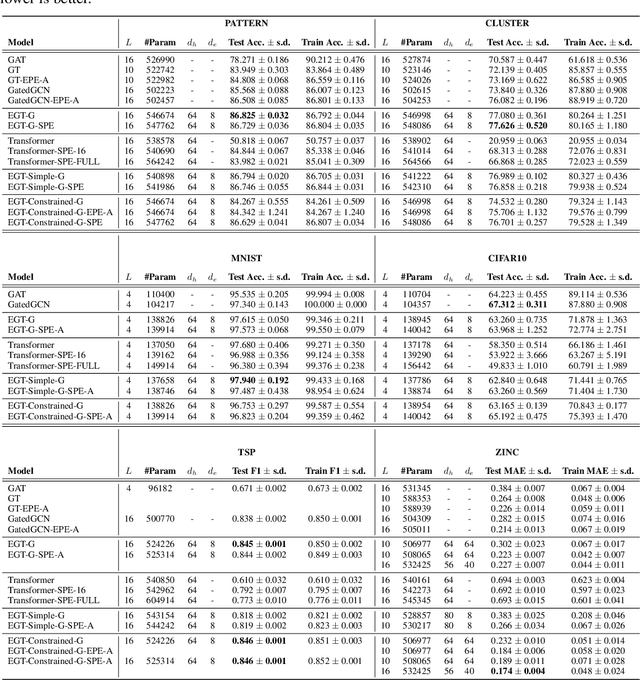
Transformer neural networks have achieved state-of-the-art results for unstructured data such as text and images but their adoption for graph-structured data has been limited. This is partly due to the difficulty in incorporating complex structural information in the basic transformer framework. We propose a simple yet powerful extension to the transformer - residual edge channels. The resultant framework, which we call Edge-augmented Graph Transformer (EGT), can directly accept, process and output structural information as well as node information. This simple addition allows us to use global self-attention, the key element of transformers, directly for graphs and comes with the benefit of long-range interaction among nodes. Moreover, the edge channels allow the structural information to evolve from layer to layer, and prediction tasks on edges can be derived directly from these channels. In addition to that, we introduce positional encodings based on Singular Value Decomposition which can improve the performance of EGT. Our framework, which relies on global node feature aggregation, achieves better performance compared to Graph Convolutional Networks (GCN), which rely on local feature aggregation within a neighborhood. We verify the performance of EGT in a supervised learning setting on a wide range of experiments on benchmark datasets. Our findings indicate that convolutional aggregation is not an essential inductive bias for graphs and global self-attention can serve as a flexible and adaptive alternative to graph convolution.
Can a Fruit Fly Learn Word Embeddings?
Jan 18, 2021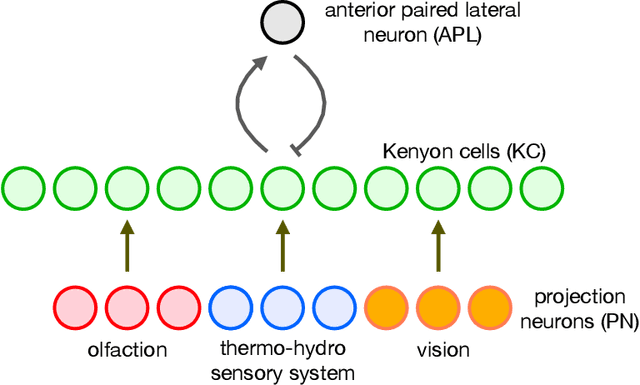
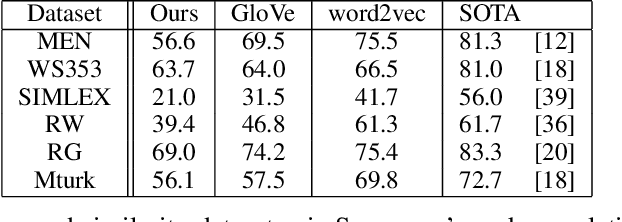
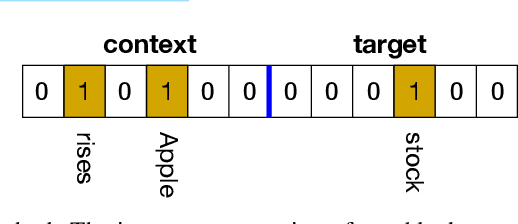

The mushroom body of the fruit fly brain is one of the best studied systems in neuroscience. At its core it consists of a population of Kenyon cells, which receive inputs from multiple sensory modalities. These cells are inhibited by the anterior paired lateral neuron, thus creating a sparse high dimensional representation of the inputs. In this work we study a mathematical formalization of this network motif and apply it to learning the correlational structure between words and their context in a corpus of unstructured text, a common natural language processing (NLP) task. We show that this network can learn semantic representations of words and can generate both static and context-dependent word embeddings. Unlike conventional methods (e.g., BERT, GloVe) that use dense representations for word embedding, our algorithm encodes semantic meaning of words and their context in the form of sparse binary hash codes. The quality of the learned representations is evaluated on word similarity analysis, word-sense disambiguation, and document classification. It is shown that not only can the fruit fly network motif achieve performance comparable to existing methods in NLP, but, additionally, it uses only a fraction of the computational resources (shorter training time and smaller memory footprint).
Personalized Food Recommendation as Constrained Question Answering over a Large-scale Food Knowledge Graph
Jan 05, 2021
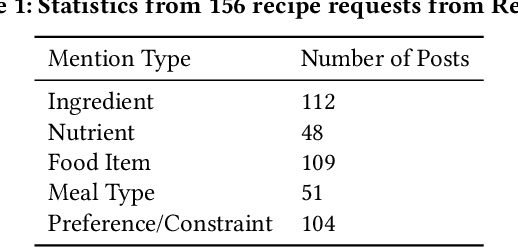
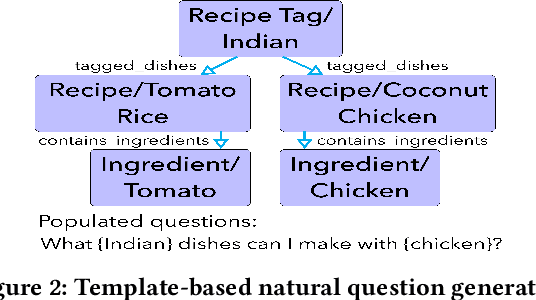

Food recommendation has become an important means to help guide users to adopt healthy dietary habits. Previous works on food recommendation either i) fail to consider users' explicit requirements, ii) ignore crucial health factors (e.g., allergies and nutrition needs), or iii) do not utilize the rich food knowledge for recommending healthy recipes. To address these limitations, we propose a novel problem formulation for food recommendation, modeling this task as constrained question answering over a large-scale food knowledge base/graph (KBQA). Besides the requirements from the user query, personalized requirements from the user's dietary preferences and health guidelines are handled in a unified way as additional constraints to the QA system. To validate this idea, we create a QA style dataset for personalized food recommendation based on a large-scale food knowledge graph and health guidelines. Furthermore, we propose a KBQA-based personalized food recommendation framework which is equipped with novel techniques for handling negations and numerical comparisons in the queries. Experimental results on the benchmark show that our approach significantly outperforms non-personalized counterparts (average 59.7% absolute improvement across various evaluation metrics), and is able to recommend more relevant and healthier recipes.
Iterative Deep Graph Learning for Graph Neural Networks: Better and Robust Node Embeddings
Jun 21, 2020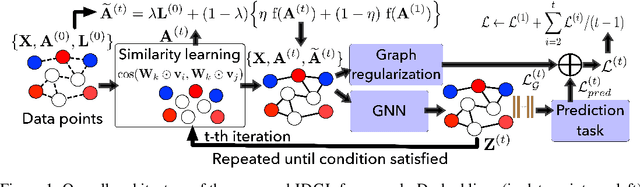
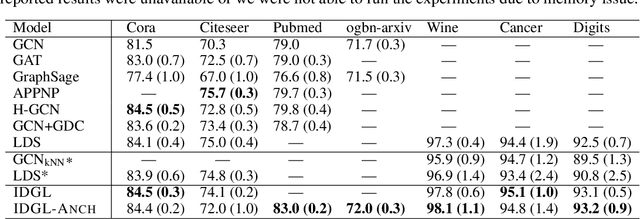
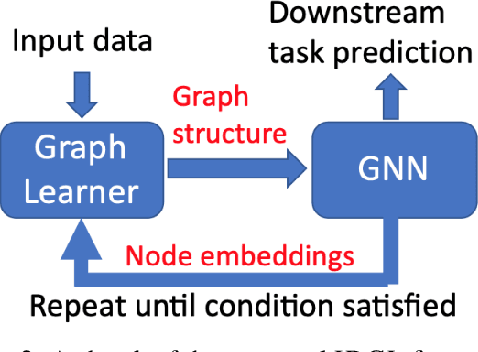
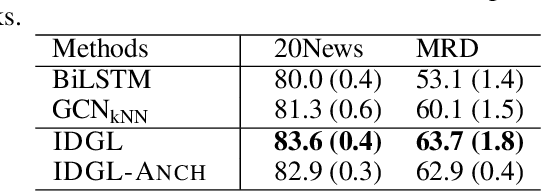
In this paper, we propose an end-to-end graph learning framework, namely Iterative Deep Graph Learning (IDGL), for jointly and iteratively learning graph structure and graph embedding. The key rationale of IDGL is to learn a better graph structure based on better node embeddings, and vice versa (i.e., better node embeddings based on a better graph structure). Our iterative method dynamically stops when the learned graph approaches close enough to the graph optimized for the prediction task. In addition, we cast the graph learning problem as a similarity metric learning problem and leverage adaptive graph regularization for controlling the quality of the learned graph. Finally, combining the anchor-based approximation technique, we further propose a scalable version of IDGL, namely IDGL-ANCH, which significantly reduces the time and space complexity of IDGL without compromising the performance. Our extensive experiments on nine benchmarks show that our proposed IDGL models can consistently outperform or match state-of-the-art baselines. Furthermore, IDGL can be more robust to adversarial graphs and cope with both transductive and inductive learning.