 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBytes Are All You Need: Transformers Operating Directly On File Bytes
May 31, 2023Modern deep learning approaches usually transform inputs into a modality-specific form. For example, the most common deep learning approach to image classification involves decoding image file bytes into an RGB tensor which is passed into a neural network. Instead, we investigate performing classification directly on file bytes, without the need for decoding files at inference time. Using file bytes as model inputs enables the development of models which can operate on multiple input modalities. Our model, \emph{ByteFormer}, achieves an ImageNet Top-1 classification accuracy of $77.33\%$ when training and testing directly on TIFF file bytes using a transformer backbone with configuration similar to DeiT-Ti ($72.2\%$ accuracy when operating on RGB images). Without modifications or hyperparameter tuning, ByteFormer achieves $95.42\%$ classification accuracy when operating on WAV files from the Speech Commands v2 dataset (compared to state-of-the-art accuracy of $98.7\%$). Additionally, we demonstrate that ByteFormer has applications in privacy-preserving inference. ByteFormer is capable of performing inference on particular obfuscated input representations with no loss of accuracy. We also demonstrate ByteFormer's ability to perform inference with a hypothetical privacy-preserving camera which avoids forming full images by consistently masking $90\%$ of pixel channels, while still achieving $71.35\%$ accuracy on ImageNet. Our code will be made available at https://github.com/apple/ml-cvnets/tree/main/examples/byteformer.
Reinforce Data, Multiply Impact: Improved Model Accuracy and Robustness with Dataset Reinforcement
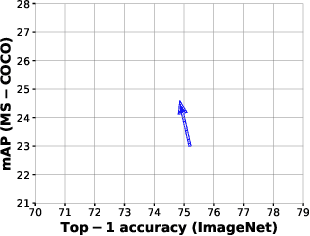
Mar 15, 2023We propose Dataset Reinforcement, a strategy to improve a dataset once such that the accuracy of any model architecture trained on the reinforced dataset is improved at no additional training cost for users. We propose a Dataset Reinforcement strategy based on data augmentation and knowledge distillation. Our generic strategy is designed based on extensive analysis across CNN- and transformer-based models and performing large-scale study of distillation with state-of-the-art models with various data augmentations. We create a reinforced version of the ImageNet training dataset, called ImageNet+, as well as reinforced datasets CIFAR-100+, Flowers-102+, and Food-101+. Models trained with ImageNet+ are more accurate, robust, and calibrated, and transfer well to downstream tasks (e.g., segmentation and detection). As an example, the accuracy of ResNet-50 improves by 1.7% on the ImageNet validation set, 3.5% on ImageNetV2, and 10.0% on ImageNet-R. Expected Calibration Error (ECE) on the ImageNet validation set is also reduced by 9.9%. Using this backbone with Mask-RCNN for object detection on MS-COCO, the mean average precision improves by 0.8%. We reach similar gains for MobileNets, ViTs, and Swin-Transformers. For MobileNetV3 and Swin-Tiny we observe significant improvements on ImageNet-R/A/C of up to 10% improved robustness. Models pretrained on ImageNet+ and fine-tuned on CIFAR-100+, Flowers-102+, and Food-101+, reach up to 3.4% improved accuracy.
RangeAugment: Efficient Online Augmentation with Range Learning
Dec 20, 2022



State-of-the-art automatic augmentation methods (e.g., AutoAugment and RandAugment) for visual recognition tasks diversify training data using a large set of augmentation operations. The range of magnitudes of many augmentation operations (e.g., brightness and contrast) is continuous. Therefore, to make search computationally tractable, these methods use fixed and manually-defined magnitude ranges for each operation, which may lead to sub-optimal policies. To answer the open question on the importance of magnitude ranges for each augmentation operation, we introduce RangeAugment that allows us to efficiently learn the range of magnitudes for individual as well as composite augmentation operations. RangeAugment uses an auxiliary loss based on image similarity as a measure to control the range of magnitudes of augmentation operations. As a result, RangeAugment has a single scalar parameter for search, image similarity, which we simply optimize via linear search. RangeAugment integrates seamlessly with any model and learns model- and task-specific augmentation policies. With extensive experiments on the ImageNet dataset across different networks, we show that RangeAugment achieves competitive performance to state-of-the-art automatic augmentation methods with 4-5 times fewer augmentation operations. Experimental results on semantic segmentation, object detection, foundation models, and knowledge distillation further shows RangeAugment's effectiveness.
SPIN: An Empirical Evaluation on Sharing Parameters of Isotropic Networks
Jul 21, 2022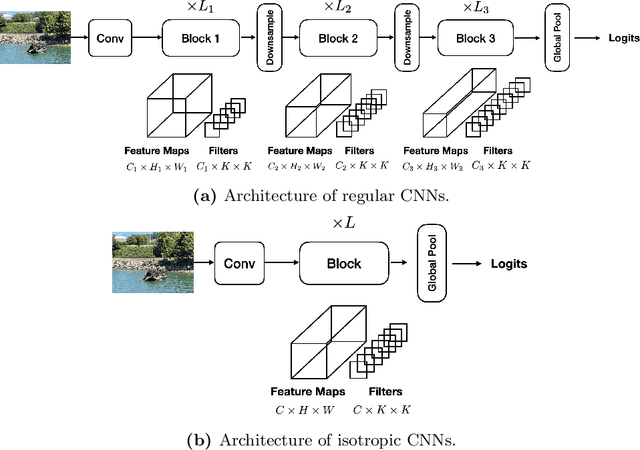
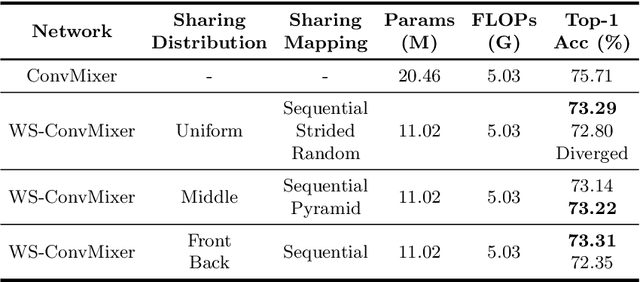
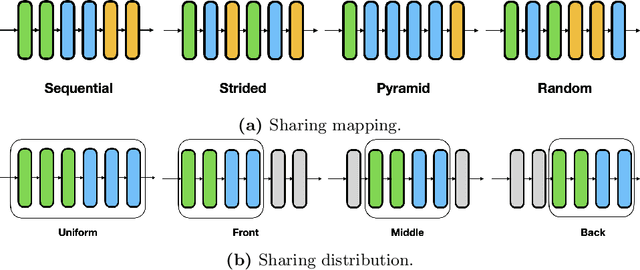
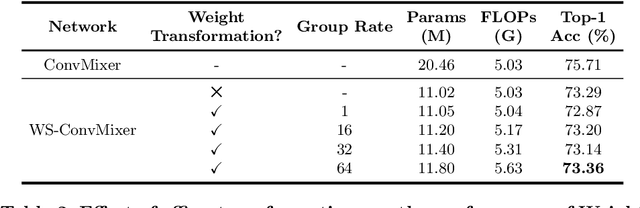
Recent isotropic networks, such as ConvMixer and vision transformers, have found significant success across visual recognition tasks, matching or outperforming non-isotropic convolutional neural networks (CNNs). Isotropic architectures are particularly well-suited to cross-layer weight sharing, an effective neural network compression technique. In this paper, we perform an empirical evaluation on methods for sharing parameters in isotropic networks (SPIN). We present a framework to formalize major weight sharing design decisions and perform a comprehensive empirical evaluation of this design space. Guided by our experimental results, we propose a weight sharing strategy to generate a family of models with better overall efficiency, in terms of FLOPs and parameters versus accuracy, compared to traditional scaling methods alone, for example compressing ConvMixer by 1.9x while improving accuracy on ImageNet. Finally, we perform a qualitative study to further understand the behavior of weight sharing in isotropic architectures. The code is available at https://github.com/apple/ml-spin.
Separable Self-attention for Mobile Vision Transformers
Jun 06, 2022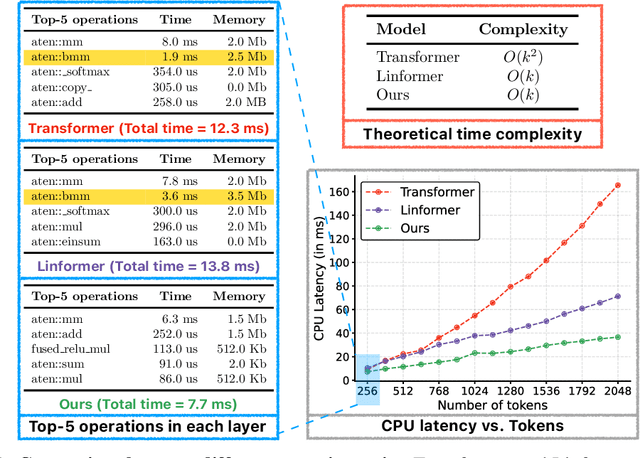

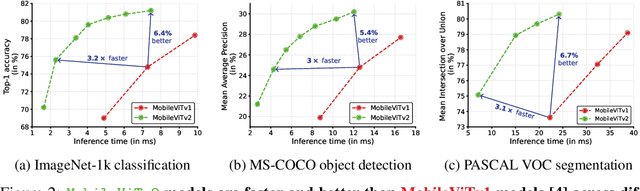

Mobile vision transformers (MobileViT) can achieve state-of-the-art performance across several mobile vision tasks, including classification and detection. Though these models have fewer parameters, they have high latency as compared to convolutional neural network-based models. The main efficiency bottleneck in MobileViT is the multi-headed self-attention (MHA) in transformers, which requires $O(k^2)$ time complexity with respect to the number of tokens (or patches) $k$. Moreover, MHA requires costly operations (e.g., batch-wise matrix multiplication) for computing self-attention, impacting latency on resource-constrained devices. This paper introduces a separable self-attention method with linear complexity, i.e. $O(k)$. A simple yet effective characteristic of the proposed method is that it uses element-wise operations for computing self-attention, making it a good choice for resource-constrained devices. The improved model, MobileViTv2, is state-of-the-art on several mobile vision tasks, including ImageNet object classification and MS-COCO object detection. With about three million parameters, MobileViTv2 achieves a top-1 accuracy of 75.6% on the ImageNet dataset, outperforming MobileViT by about 1% while running $3.2\times$ faster on a mobile device. Our source code is available at: \url{https://github.com/apple/ml-cvnets}
CVNets: High Performance Library for Computer Vision
Jun 04, 2022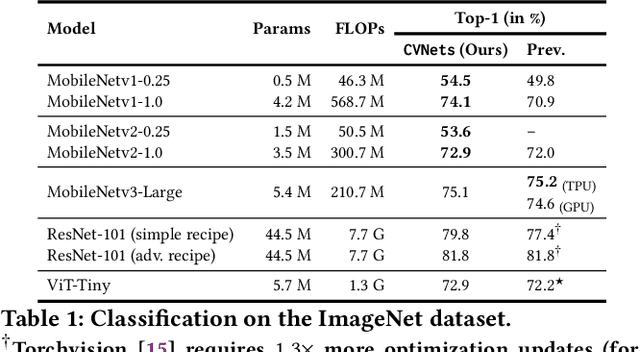
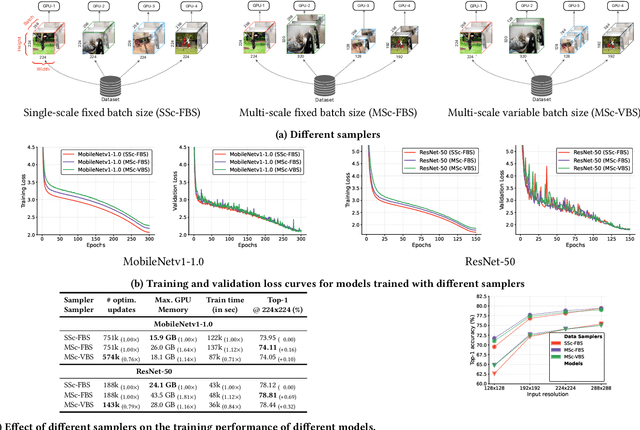
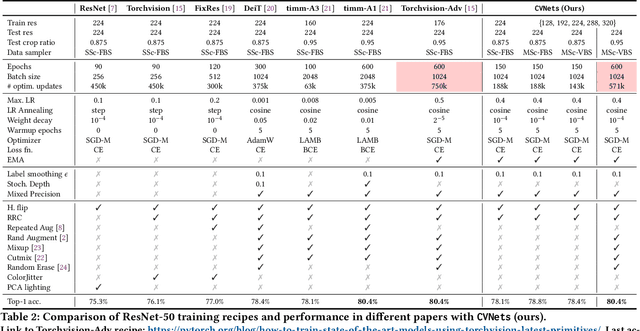
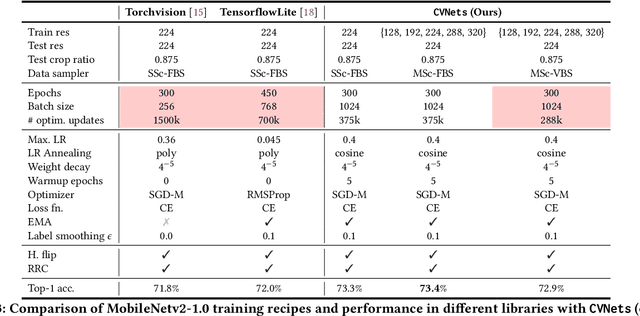
We introduce CVNets, a high-performance open-source library for training deep neural networks for visual recognition tasks, including classification, detection, and segmentation. CVNets supports image and video understanding tools, including data loading, data transformations, novel data sampling methods, and implementations of several standard networks with similar or better performance than previous studies. Our source code is available at: \url{https://github.com/apple/ml-cvnets}.
Token Pooling in Vision Transformers
Oct 11, 2021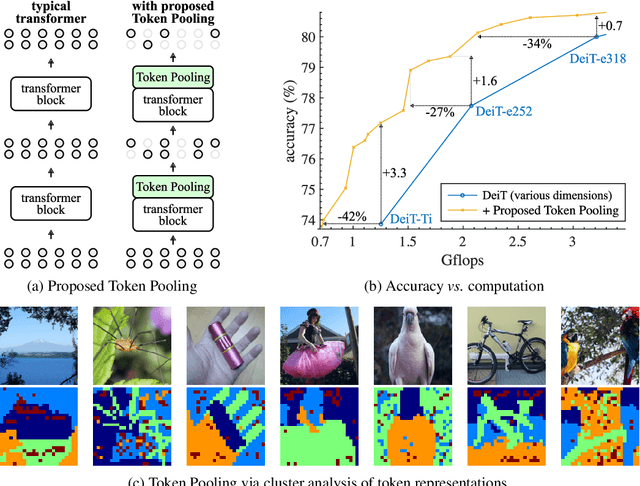
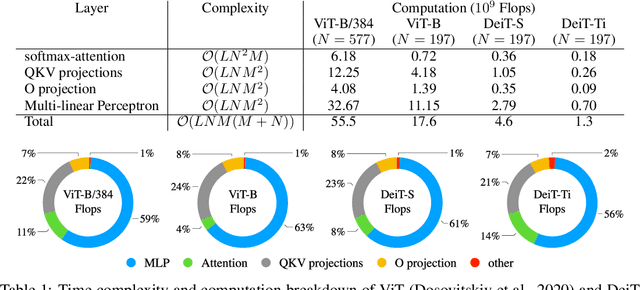
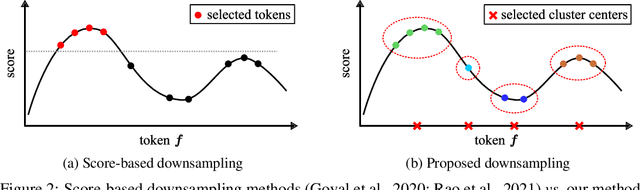
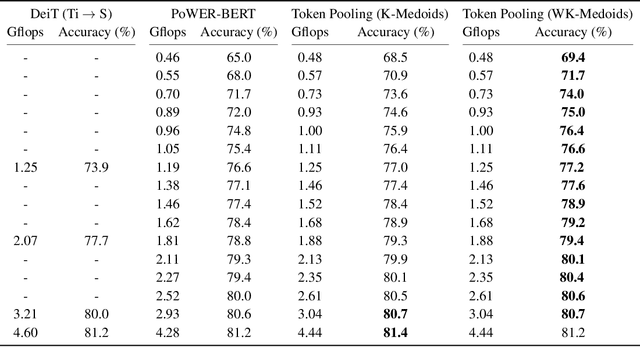
Despite the recent success in many applications, the high computational requirements of vision transformers limit their use in resource-constrained settings. While many existing methods improve the quadratic complexity of attention, in most vision transformers, self-attention is not the major computation bottleneck, e.g., more than 80% of the computation is spent on fully-connected layers. To improve the computational complexity of all layers, we propose a novel token downsampling method, called Token Pooling, efficiently exploiting redundancies in the images and intermediate token representations. We show that, under mild assumptions, softmax-attention acts as a high-dimensional low-pass (smoothing) filter. Thus, its output contains redundancy that can be pruned to achieve a better trade-off between the computational cost and accuracy. Our new technique accurately approximates a set of tokens by minimizing the reconstruction error caused by downsampling. We solve this optimization problem via cost-efficient clustering. We rigorously analyze and compare to prior downsampling methods. Our experiments show that Token Pooling significantly improves the cost-accuracy trade-off over the state-of-the-art downsampling. Token Pooling is a simple and effective operator that can benefit many architectures. Applied to DeiT, it achieves the same ImageNet top-1 accuracy using 42% fewer computations.
LCS: Learning Compressible Subspaces for Adaptive Network Compression at Inference Time
Oct 08, 2021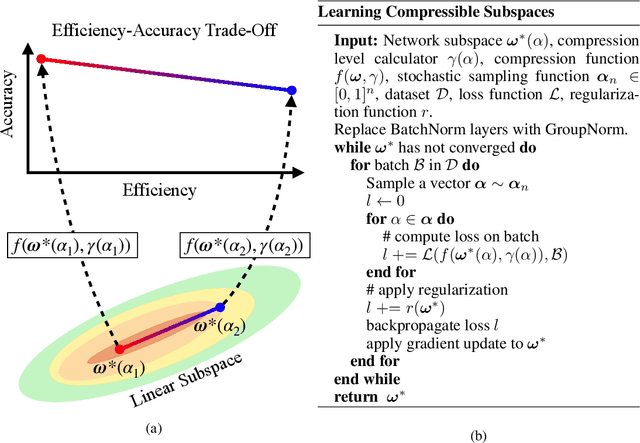

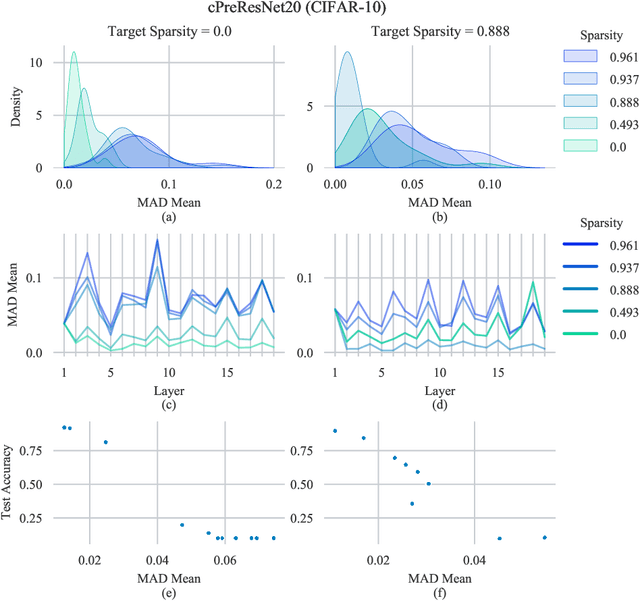
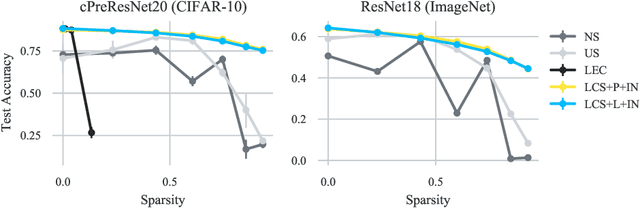
When deploying deep learning models to a device, it is traditionally assumed that available computational resources (compute, memory, and power) remain static. However, real-world computing systems do not always provide stable resource guarantees. Computational resources need to be conserved when load from other processes is high or battery power is low. Inspired by recent works on neural network subspaces, we propose a method for training a "compressible subspace" of neural networks that contains a fine-grained spectrum of models that range from highly efficient to highly accurate. Our models require no retraining, thus our subspace of models can be deployed entirely on-device to allow adaptive network compression at inference time. We present results for achieving arbitrarily fine-grained accuracy-efficiency trade-offs at inference time for structured and unstructured sparsity. We achieve accuracies on-par with standard models when testing our uncompressed models, and maintain high accuracy for sparsity rates above 90% when testing our compressed models. We also demonstrate that our algorithm extends to quantization at variable bit widths, achieving accuracy on par with individually trained networks.
MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer
Oct 05, 2021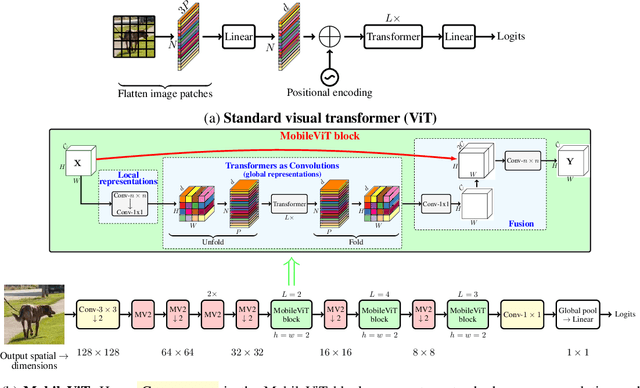


Light-weight convolutional neural networks (CNNs) are the de-facto for mobile vision tasks. Their spatial inductive biases allow them to learn representations with fewer parameters across different vision tasks. However, these networks are spatially local. To learn global representations, self-attention-based vision trans-formers (ViTs) have been adopted. Unlike CNNs, ViTs are heavy-weight. In this paper, we ask the following question: is it possible to combine the strengths of CNNs and ViTs to build a light-weight and low latency network for mobile vision tasks? Towards this end, we introduce MobileViT, a light-weight and general-purpose vision transformer for mobile devices. MobileViT presents a different perspective for the global processing of information with transformers, i.e., transformers as convolutions. Our results show that MobileViT significantly outperforms CNN- and ViT-based networks across different tasks and datasets. On the ImageNet-1k dataset, MobileViT achieves top-1 accuracy of 78.4% with about 6 million parameters, which is 3.2% and 6.2% more accurate than MobileNetv3 (CNN-based) and DeIT (ViT-based) for a similar number of parameters. On the MS-COCO object detection task, MobileViT is 5.7% more accurate than Mo-bileNetv3 for a similar number of parameters.
DKM: Differentiable K-Means Clustering Layer for Neural Network Compression
Aug 28, 2021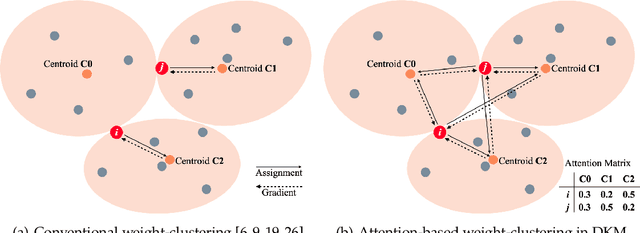
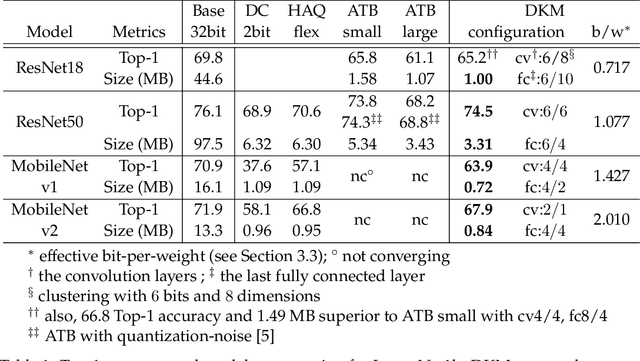
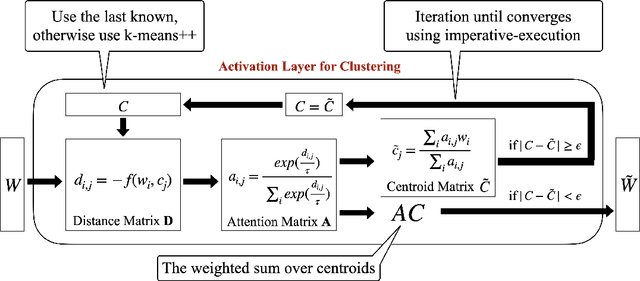
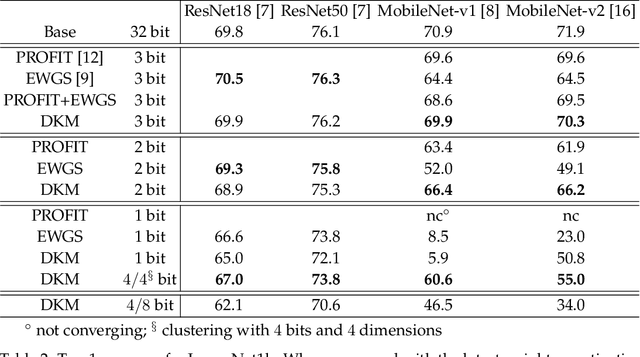
Deep neural network (DNN) model compression for efficient on-device inference is becoming increasingly important to reduce memory requirements and keep user data on-device. To this end, we propose a novel differentiable k-means clustering layer (DKM) and its application to train-time weight clustering-based DNN model compression. DKM casts k-means clustering as an attention problem and enables joint optimization of the parameters and clustering centroids. Unlike prior works that rely on additional regularizers and parameters, DKM-based compression keeps the original loss function and model architecture fixed. We evaluated DKM-based compression on various DNN models for computer vision and natural language processing (NLP) tasks. Our results demonstrate that DMK delivers superior compression and accuracy trade-off on ImageNet1k and GLUE benchmarks. For example, DKM-based compression can offer 74.5% top-1 ImageNet1k accuracy on ResNet50 DNN model with 3.3MB model size (29.4x model compression factor). For MobileNet-v1, which is a challenging DNN to compress, DKM delivers 62.8% top-1 ImageNet1k accuracy with 0.74 MB model size (22.4x model compression factor). This result is 6.8% higher top-1 accuracy and 33% relatively smaller model size than the current state-of-the-art DNN compression algorithms. Additionally, DKM enables compression of DistilBERT model by 11.8x with minimal (1.1%) accuracy loss on GLUE NLP benchmarks.