 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Predictive Belief Representations
Nov 15, 2018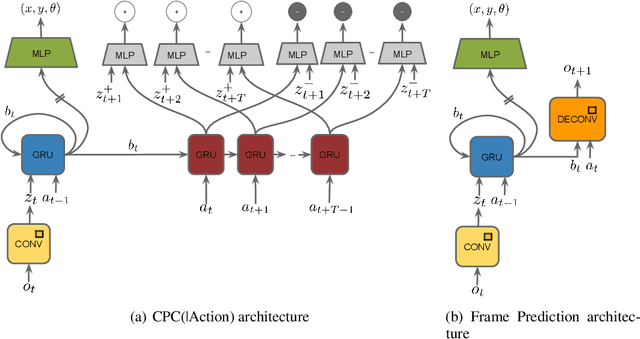
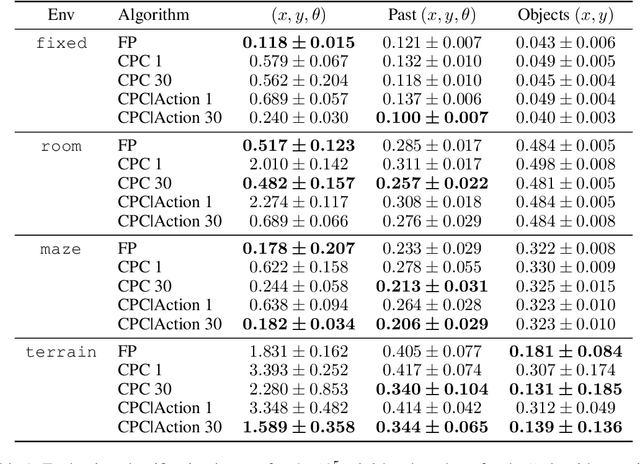
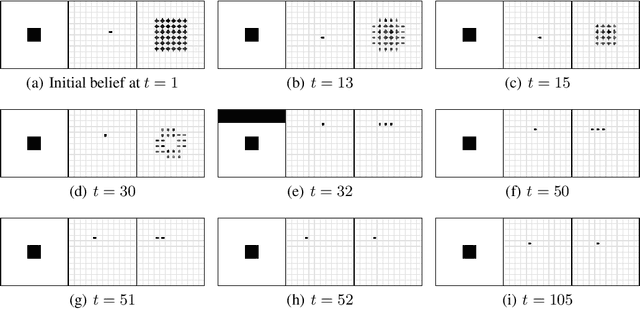
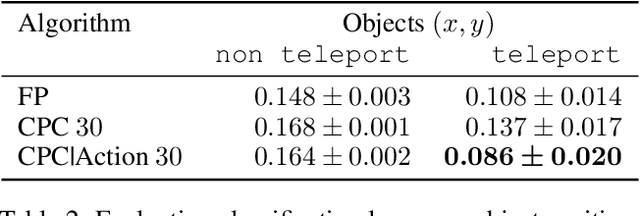
Unsupervised representation learning has succeeded with excellent results in many applications. It is an especially powerful tool to learn a good representation of environments with partial or noisy observations. In partially observable domains it is important for the representation to encode a belief state, a sufficient statistic of the observations seen so far. In this paper, we investigate whether it is possible to learn such a belief representation using modern neural architectures. Specifically, we focus on one-step frame prediction and two variants of contrastive predictive coding (CPC) as the objective functions to learn the representations. To evaluate these learned representations, we test how well they can predict various pieces of information about the underlying state of the environment, e.g., position of the agent in a 3D maze. We show that all three methods are able to learn belief representations of the environment, they encode not only the state information, but also its uncertainty, a crucial aspect of belief states. We also find that for CPC multi-step predictions and action-conditioning are critical for accurate belief representations in visually complex environments. The ability of neural representations to capture the belief information has the potential to spur new advances for learning and planning in partially observable domains, where leveraging uncertainty is essential for optimal decision making.
The Reactor: A fast and sample-efficient Actor-Critic agent for Reinforcement Learning
Jun 19, 2018



In this work we present a new agent architecture, called Reactor, which combines multiple algorithmic and architectural contributions to produce an agent with higher sample-efficiency than Prioritized Dueling DQN (Wang et al., 2016) and Categorical DQN (Bellemare et al., 2017), while giving better run-time performance than A3C (Mnih et al., 2016). Our first contribution is a new policy evaluation algorithm called Distributional Retrace, which brings multi-step off-policy updates to the distributional reinforcement learning setting. The same approach can be used to convert several classes of multi-step policy evaluation algorithms designed for expected value evaluation into distributional ones. Next, we introduce the \b{eta}-leave-one-out policy gradient algorithm which improves the trade-off between variance and bias by using action values as a baseline. Our final algorithmic contribution is a new prioritized replay algorithm for sequences, which exploits the temporal locality of neighboring observations for more efficient replay prioritization. Using the Atari 2600 benchmarks, we show that each of these innovations contribute to both the sample efficiency and final agent performance. Finally, we demonstrate that Reactor reaches state-of-the-art performance after 200 million frames and less than a day of training.
Observe and Look Further: Achieving Consistent Performance on Atari
May 29, 2018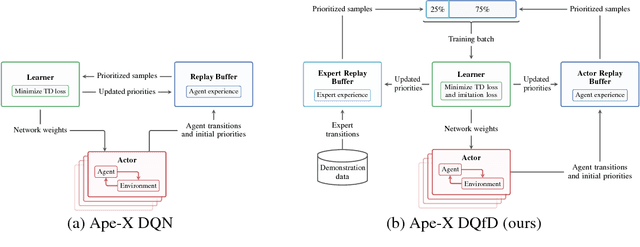
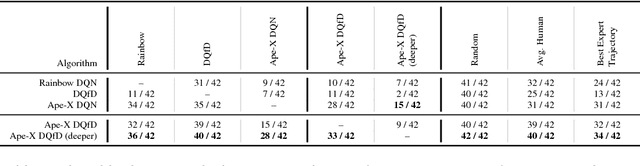
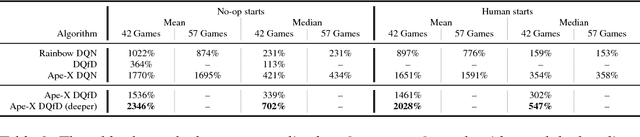
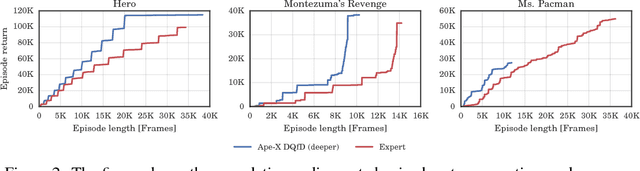
Despite significant advances in the field of deep Reinforcement Learning (RL), today's algorithms still fail to learn human-level policies consistently over a set of diverse tasks such as Atari 2600 games. We identify three key challenges that any algorithm needs to master in order to perform well on all games: processing diverse reward distributions, reasoning over long time horizons, and exploring efficiently. In this paper, we propose an algorithm that addresses each of these challenges and is able to learn human-level policies on nearly all Atari games. A new transformed Bellman operator allows our algorithm to process rewards of varying densities and scales; an auxiliary temporal consistency loss allows us to train stably using a discount factor of $\gamma = 0.999$ (instead of $\gamma = 0.99$) extending the effective planning horizon by an order of magnitude; and we ease the exploration problem by using human demonstrations that guide the agent towards rewarding states. When tested on a set of 42 Atari games, our algorithm exceeds the performance of an average human on 40 games using a common set of hyper parameters. Furthermore, it is the first deep RL algorithm to solve the first level of Montezuma's Revenge.
Noisy Networks for Exploration
Feb 15, 2018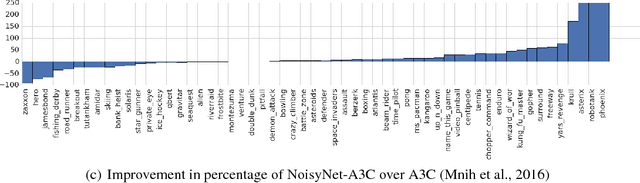
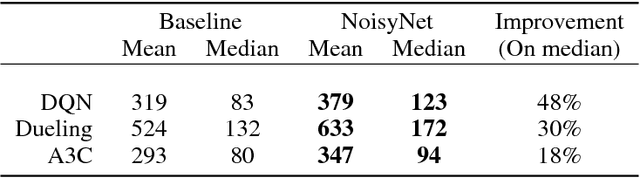
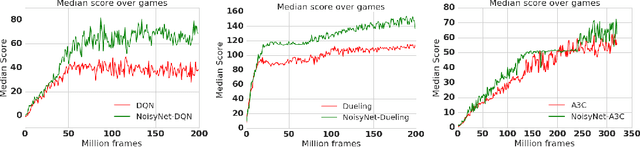
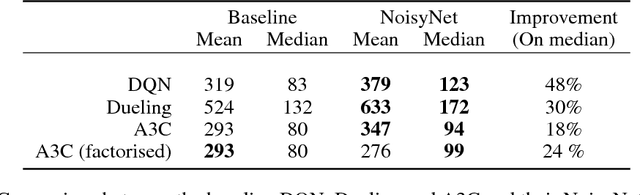
We introduce NoisyNet, a deep reinforcement learning agent with parametric noise added to its weights, and show that the induced stochasticity of the agent's policy can be used to aid efficient exploration. The parameters of the noise are learned with gradient descent along with the remaining network weights. NoisyNet is straightforward to implement and adds little computational overhead. We find that replacing the conventional exploration heuristics for A3C, DQN and dueling agents (entropy reward and $\epsilon$-greedy respectively) with NoisyNet yields substantially higher scores for a wide range of Atari games, in some cases advancing the agent from sub to super-human performance.
Minimax Regret Bounds for Reinforcement Learning
Jul 01, 2017We consider the problem of provably optimal exploration in reinforcement learning for finite horizon MDPs. We show that an optimistic modification to value iteration achieves a regret bound of $\tilde{O}( \sqrt{HSAT} + H^2S^2A+H\sqrt{T})$ where $H$ is the time horizon, $S$ the number of states, $A$ the number of actions and $T$ the number of time-steps. This result improves over the best previous known bound $\tilde{O}(HS \sqrt{AT})$ achieved by the UCRL2 algorithm of Jaksch et al., 2010. The key significance of our new results is that when $T\geq H^3S^3A$ and $SA\geq H$, it leads to a regret of $\tilde{O}(\sqrt{HSAT})$ that matches the established lower bound of $\Omega(\sqrt{HSAT})$ up to a logarithmic factor. Our analysis contains two key insights. We use careful application of concentration inequalities to the optimal value function as a whole, rather than to the transitions probabilities (to improve scaling in $S$), and we define Bernstein-based "exploration bonuses" that use the empirical variance of the estimated values at the next states (to improve scaling in $H$).
Convex Relaxation Regression: Black-Box Optimization of Smooth Functions by Learning Their Convex Envelopes
Mar 03, 2016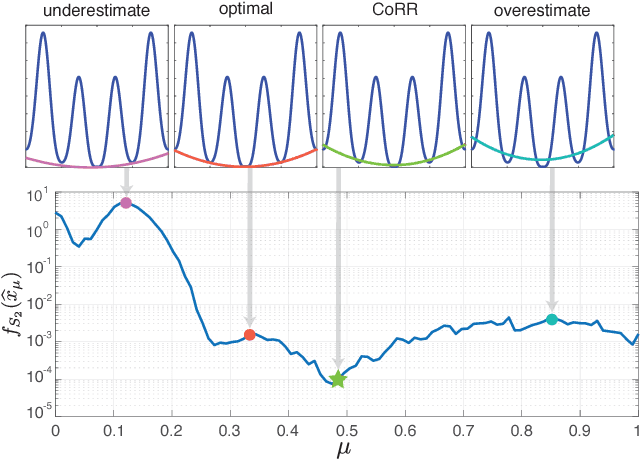
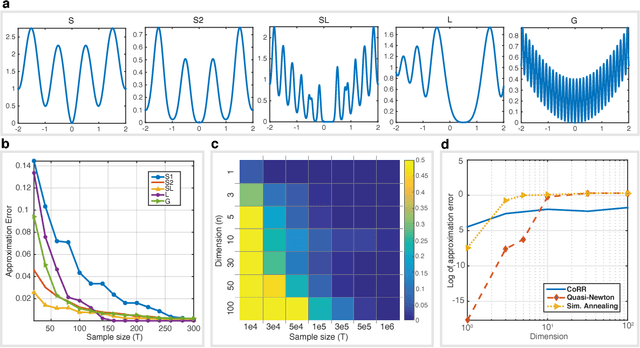
Finding efficient and provable methods to solve non-convex optimization problems is an outstanding challenge in machine learning and optimization theory. A popular approach used to tackle non-convex problems is to use convex relaxation techniques to find a convex surrogate for the problem. Unfortunately, convex relaxations typically must be found on a problem-by-problem basis. Thus, providing a general-purpose strategy to estimate a convex relaxation would have a wide reaching impact. Here, we introduce Convex Relaxation Regression (CoRR), an approach for learning convex relaxations for a class of smooth functions. The main idea behind our approach is to estimate the convex envelope of a function $f$ by evaluating $f$ at a set of $T$ random points and then fitting a convex function to these function evaluations. We prove that with probability greater than $1-\delta$, the solution of our algorithm converges to the global optimizer of $f$ with error $\mathcal{O} \Big( \big(\frac{\log(1/\delta) }{T} \big)^{\alpha} \Big)$ for some $\alpha> 0$. Our approach enables the use of convex optimization tools to solve a class of non-convex optimization problems.
Online Stochastic Optimization under Correlated Bandit Feedback
May 19, 2014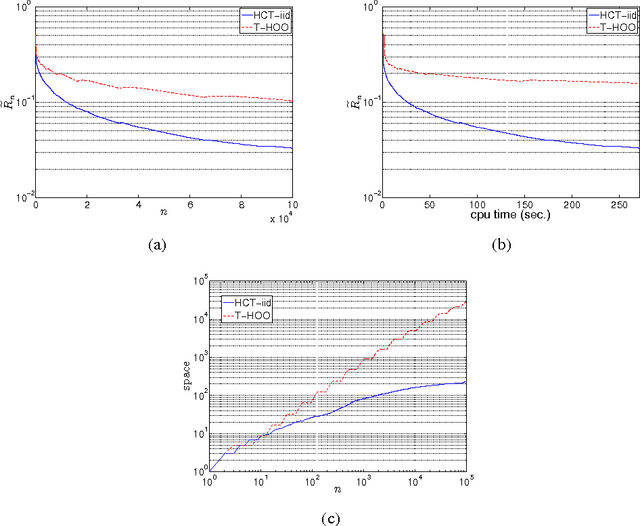
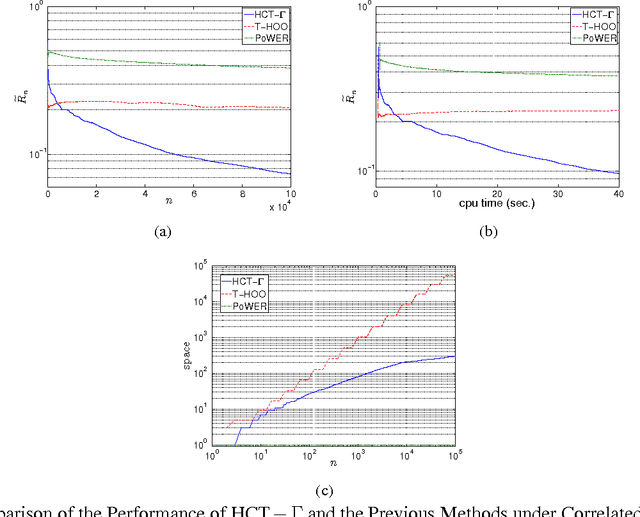
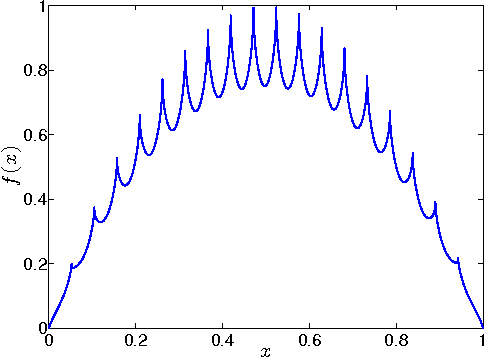
In this paper we consider the problem of online stochastic optimization of a locally smooth function under bandit feedback. We introduce the high-confidence tree (HCT) algorithm, a novel any-time $\mathcal{X}$-armed bandit algorithm, and derive regret bounds matching the performance of existing state-of-the-art in terms of dependency on number of steps and smoothness factor. The main advantage of HCT is that it handles the challenging case of correlated rewards, whereas existing methods require that the reward-generating process of each arm is an identically and independent distributed (iid) random process. HCT also improves on the state-of-the-art in terms of its memory requirement as well as requiring a weaker smoothness assumption on the mean-reward function in compare to the previous anytime algorithms. Finally, we discuss how HCT can be applied to the problem of policy search in reinforcement learning and we report preliminary empirical results.
Sequential Transfer in Multi-armed Bandit with Finite Set of Models
Jul 25, 2013
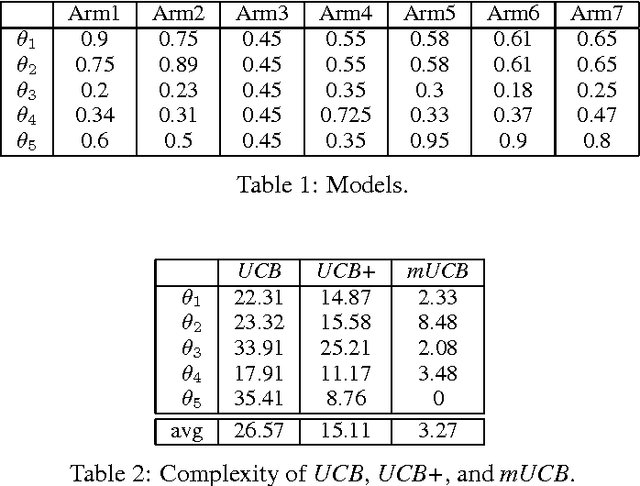
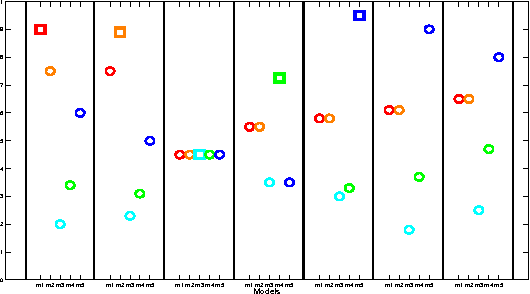
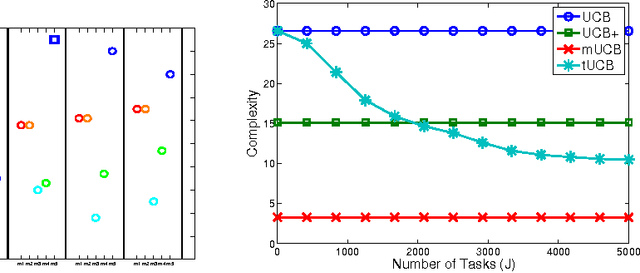
Learning from prior tasks and transferring that experience to improve future performance is critical for building lifelong learning agents. Although results in supervised and reinforcement learning show that transfer may significantly improve the learning performance, most of the literature on transfer is focused on batch learning tasks. In this paper we study the problem of \textit{sequential transfer in online learning}, notably in the multi-armed bandit framework, where the objective is to minimize the cumulative regret over a sequence of tasks by incrementally transferring knowledge from prior tasks. We introduce a novel bandit algorithm based on a method-of-moments approach for the estimation of the possible tasks and derive regret bounds for it.
Regret Bounds for Reinforcement Learning with Policy Advice
Jul 17, 2013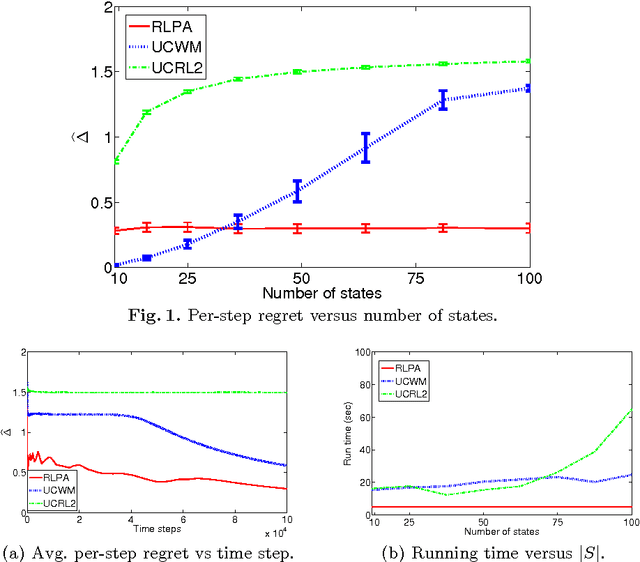
In some reinforcement learning problems an agent may be provided with a set of input policies, perhaps learned from prior experience or provided by advisors. We present a reinforcement learning with policy advice (RLPA) algorithm which leverages this input set and learns to use the best policy in the set for the reinforcement learning task at hand. We prove that RLPA has a sub-linear regret of \tilde O(\sqrt{T}) relative to the best input policy, and that both this regret and its computational complexity are independent of the size of the state and action space. Our empirical simulations support our theoretical analysis. This suggests RLPA may offer significant advantages in large domains where some prior good policies are provided.
On the Sample Complexity of Reinforcement Learning with a Generative Model
Jun 27, 2012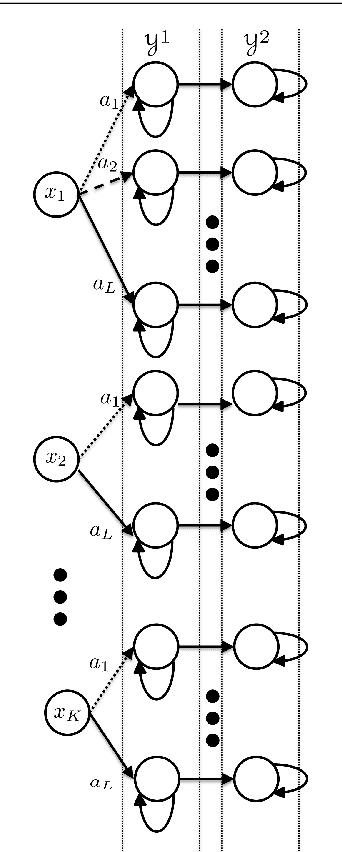
We consider the problem of learning the optimal action-value function in the discounted-reward Markov decision processes (MDPs). We prove a new PAC bound on the sample-complexity of model-based value iteration algorithm in the presence of the generative model, which indicates that for an MDP with N state-action pairs and the discount factor \gamma\in[0,1) only O(N\log(N/\delta)/((1-\gamma)^3\epsilon^2)) samples are required to find an \epsilon-optimal estimation of the action-value function with the probability 1-\delta. We also prove a matching lower bound of \Theta (N\log(N/\delta)/((1-\gamma)^3\epsilon^2)) on the sample complexity of estimating the optimal action-value function by every RL algorithm. To the best of our knowledge, this is the first matching result on the sample complexity of estimating the optimal (action-) value function in which the upper bound matches the lower bound of RL in terms of N, \epsilon, \delta and 1/(1-\gamma). Also, both our lower bound and our upper bound significantly improve on the state-of-the-art in terms of 1/(1-\gamma).