 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDVideoQA: A Traffic Video Question Answering Dataset for Multi-Object Spatio-Temporal Reasoning in Urban Dynamics
Feb 24, 2026Understanding the complex, multi-agent dynamics of urban traffic remains a fundamental challenge for video language models. This paper introduces Urban Dynamics VideoQA, a benchmark dataset that captures the unscripted real-world behavior of dynamic urban scenes. UDVideoQA is curated from 16 hours of traffic footage recorded at multiple city intersections under diverse traffic, weather, and lighting conditions. It employs an event-driven dynamic blur technique to ensure privacy preservation without compromising scene fidelity. Using a unified annotation pipeline, the dataset contains 28K question-answer pairs generated across 8 hours of densely annotated video, averaging one question per second. Its taxonomy follows a hierarchical reasoning level, spanning basic understanding and attribution to event reasoning, reverse reasoning, and counterfactual inference, enabling systematic evaluation of both visual grounding and causal reasoning. Comprehensive experiments benchmark 10 SOTA VideoLMs on UDVideoQA and 8 models on a complementary video question generation benchmark. Results reveal a persistent perception-reasoning gap, showing models that excel in abstract inference often fail with fundamental visual grounding. While models like Gemini Pro achieve the highest zero-shot accuracy, fine-tuning the smaller Qwen2.5-VL 7B model on UDVideoQA bridges this gap, achieving performance comparable to proprietary systems. In VideoQGen, Gemini 2.5 Pro, and Qwen3 Max generate the most relevant and complex questions, though all models exhibit limited linguistic diversity, underscoring the need for human-centric evaluation. The UDVideoQA suite, including the dataset, annotation tools, and benchmarks for both VideoQA and VideoQGen, provides a foundation for advancing robust, privacy-aware, and real-world multimodal reasoning. UDVideoQA is available at https://ud-videoqa.github.io/UD-VideoQA/UD-VideoQA/.
Roundabout Dilemma Zone Data Mining and Forecasting with Trajectory Prediction and Graph Neural Networks
Sep 01, 2024



Traffic roundabouts, as complex and critical road scenarios, pose significant safety challenges for autonomous vehicles. In particular, the encounter of a vehicle with a dilemma zone (DZ) at a roundabout intersection is a pivotal concern. This paper presents an automated system that leverages trajectory forecasting to predict DZ events, specifically at traffic roundabouts. Our system aims to enhance safety standards in both autonomous and manual transportation. The core of our approach is a modular, graph-structured recurrent model that forecasts the trajectories of diverse agents, taking into account agent dynamics and integrating heterogeneous data, such as semantic maps. This model, based on graph neural networks, aids in predicting DZ events and enhances traffic management decision-making. We evaluated our system using a real-world dataset of traffic roundabout intersections. Our experimental results demonstrate that our dilemma forecasting system achieves a high precision with a low false positive rate of 0.1. This research represents an advancement in roundabout DZ data mining and forecasting, contributing to the assurance of intersection safety in the era of autonomous vehicles.
A Novel Design of Adaptive and Hierarchical Convolutional Neural Networks using Partial Reconfiguration on FPGA
Sep 05, 2019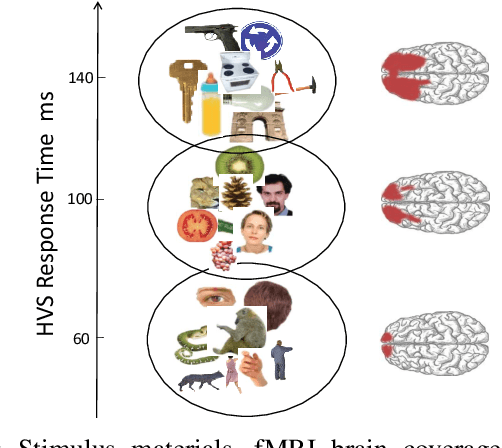
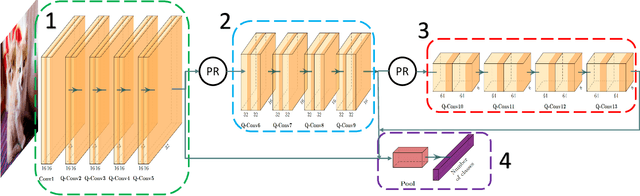
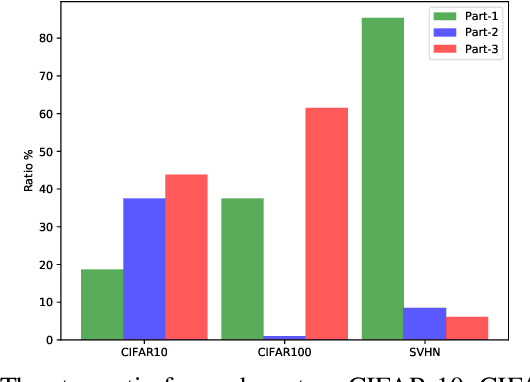
Nowadays most research in visual recognition using Convolutional Neural Networks (CNNs) follows the "deeper model with deeper confidence" belief to gain a higher recognition accuracy. At the same time, deeper model brings heavier computation. On the other hand, for a large chunk of recognition challenges, a system can classify images correctly using simple models or so-called shallow networks. Moreover, the implementation of CNNs faces with the size, weight, and energy constraints on the embedded devices. In this paper, we implement the adaptive switching between shallow and deep networks to reach the highest throughput on a resource-constrained MPSoC with CPU and FPGA. To this end, we develop and present a novel architecture for the CNNs where a gate makes the decision whether using the deeper model is beneficial or not. Due to resource limitation on FPGA, the idea of partial reconfiguration has been used to accommodate deep CNNs on the FPGA resources. We report experimental results on CIFAR-10, CIFAR-100, and SVHN datasets to validate our approach. Using confidence metric as the decision making factor, only 69.8%, 71.8%, and 43.8% of the computation in the deepest network is done for CIFAR-10, CIFAR-100, and SVHN while it can maintain the desired accuracy with the throughput of around 400 images per second for SVHN dataset.
TKD: Temporal Knowledge Distillation for Active Perception
Mar 04, 2019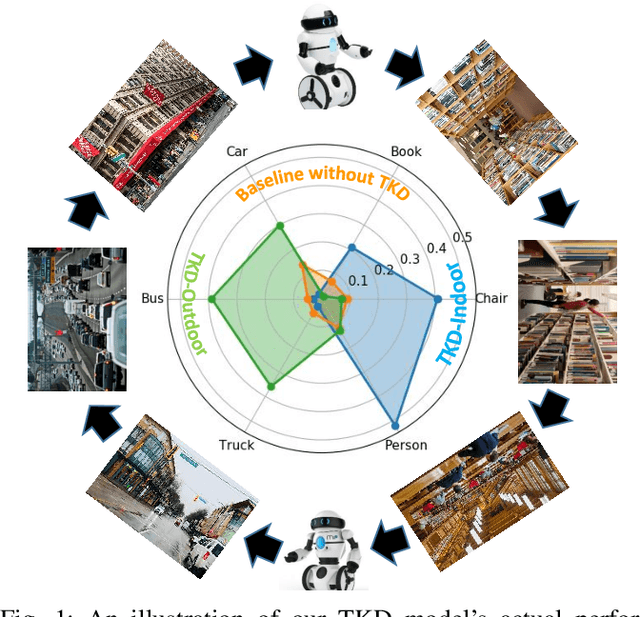
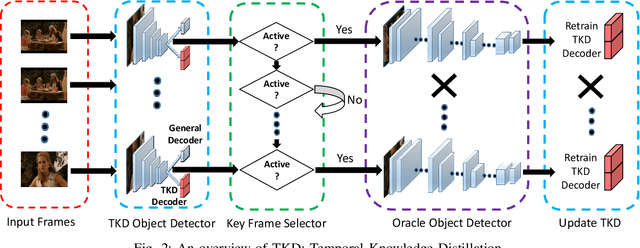
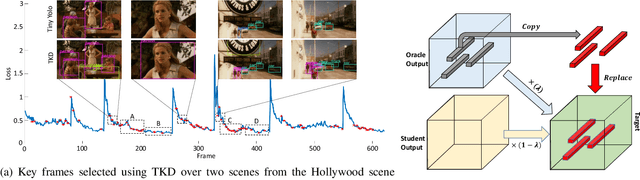
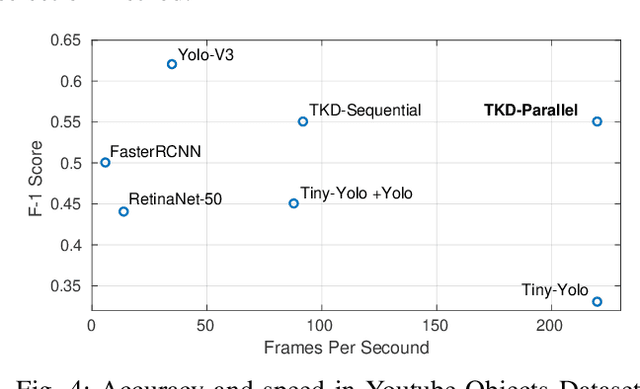
Deep neural networks based methods have been proved to achieve outstanding performance on object detection and classification tasks. Despite significant performance improvement, due to the deep structures, they still require prohibitive runtime to process images and maintain the highest possible performance for real-time applications. Observing the phenomenon that human vision system (HVS) relies heavily on the temporal dependencies among frames from the visual input to conduct recognition efficiently, we propose a novel framework dubbed as TKD: temporal knowledge distillation. This framework distills the temporal knowledge from a heavy neural networks based model over selected video frames (the perception of the moments) to a light-weight model. To enable the distillation, we put forward two novel procedures: 1) an Long-short Term Memory (LSTM) based key frame selection method; and 2) a novel teacher-bounded loss design. To validate, we conduct comprehensive empirical evaluations using different object detection methods over multiple datasets including Youtube-Objects and Hollywood scene dataset. Our results show consistent improvement in accuracy-speed trad-offs for object detection over the frames of the dynamic scene, compare to other modern object recognition methods.