 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Averaging CNN-ELM for Big Data
Oct 07, 2016



Increasing the scalability of machine learning to handle big volume of data is a challenging task. The scale up approach has some limitations. In this paper, we proposed a scale out approach for CNN-ELM based on MapReduce on classifier level. Map process is the CNN-ELM training for certain partition of data. It involves many CNN-ELM models that can be trained asynchronously. Reduce process is the averaging of all CNN-ELM weights as final training result. This approach can save a lot of training time than single CNN-ELM models trained alone. This approach also increased the scalability of machine learning by combining scale out and scale up approaches. We verified our method in extended MNIST data set and not-MNIST data set experiment. However, it has some drawbacks by additional iteration learning parameters that need to be carefully taken and training data distribution that need to be carefully selected. Further researches to use more complex image data set are required.
Adaptive Convolutional ELM For Concept Drift Handling in Online Stream Data
Oct 07, 2016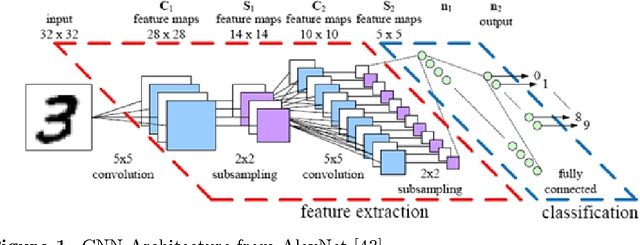



In big data era, the data continuously generated and its distribution may keep changes overtime. These challenges in online stream of data are known as concept drift. In this paper, we proposed the Adaptive Convolutional ELM method (ACNNELM) as enhancement of Convolutional Neural Network (CNN) with a hybrid Extreme Learning Machine (ELM) model plus adaptive capability. This method is aimed for concept drift handling. We enhanced the CNN as convolutional hiererchical features representation learner combined with Elastic ELM (E$^2$LM) as a parallel supervised classifier. We propose an Adaptive OS-ELM (AOS-ELM) for concept drift adaptability in classifier level (named ACNNELM-1) and matrices concatenation ensembles for concept drift adaptability in ensemble level (named ACNNELM-2). Our proposed Adaptive CNNELM is flexible that works well in classifier level and ensemble level while most current methods only proposed to work on either one of the levels. We verified our method in extended MNIST data set and not MNIST data set. We set the experiment to simulate virtual drift, real drift, and hybrid drift event and we demonstrated how our CNNELM adaptability works. Our proposed method works well and gives better accuracy, computation scalability, and concept drifts adaptability compared to the regular ELM and CNN. Further researches are still required to study the optimum parameters and to use more varied image data set.
Optimization of Convolutional Neural Network using Microcanonical Annealing Algorithm
Oct 07, 2016



Convolutional neural network (CNN) is one of the most prominent architectures and algorithm in Deep Learning. It shows a remarkable improvement in the recognition and classification of objects. This method has also been proven to be very effective in a variety of computer vision and machine learning problems. As in other deep learning, however, training the CNN is interesting yet challenging. Recently, some metaheuristic algorithms have been used to optimize CNN using Genetic Algorithm, Particle Swarm Optimization, Simulated Annealing and Harmony Search. In this paper, another type of metaheuristic algorithms with different strategy has been proposed, i.e. Microcanonical Annealing to optimize Convolutional Neural Network. The performance of the proposed method is tested using the MNIST and CIFAR-10 datasets. Although experiment results of MNIST dataset indicate the increase in computation time (1.02x - 1.38x), nevertheless this proposed method can considerably enhance the performance of the original CNN (up to 4.60\%). On the CIFAR10 dataset, currently, state of the art is 96.53\% using fractional pooling, while this proposed method achieves 99.14\%.
Sequence-based Sleep Stage Classification using Conditional Neural Fields
Oct 06, 2016



Sleep signals from a polysomnographic database are sequences in nature. Commonly employed analysis and classification methods, however, ignored this fact and treated the sleep signals as non-sequence data. Treating the sleep signals as sequences, this paper compared two powerful unsupervised feature extractors and three sequence-based classifiers regarding accuracy and computational (training and testing) time after 10-folds cross-validation. The compared feature extractors are Deep Belief Networks (DBN) and Fuzzy C-Means (FCM) clustering. Whereas the compared sequence-based classifiers are Hidden Markov Models (HMM), Conditional Random Fields (CRF) and its variants, i.e., Hidden-state CRF (HCRF) and Latent-Dynamic CRF (LDCRF); and Conditional Neural Fields (CNF) and its variant (LDCNF). In this study, we use two datasets. The first dataset is an open (public) polysomnographic dataset downloadable from the Internet, while the second dataset is our polysomnographic dataset (also available for download). For the first dataset, the combination of FCM and CNF gives the highest accuracy (96.75\%) with relatively short training time (0.33 hours). For the second dataset, the combination of DBN and CRF gives the accuracy of 99.96\% but with 1.02 hours training time, whereas the combination of DBN and CNF gives slightly less accuracy (99.69\%) but also less computation time (0.89 hours).
Metaheuristic Algorithms for Convolution Neural Network
Oct 06, 2016



A typical modern optimization technique is usually either heuristic or metaheuristic. This technique has managed to solve some optimization problems in the research area of science, engineering, and industry. However, implementation strategy of metaheuristic for accuracy improvement on convolution neural networks (CNN), a famous deep learning method, is still rarely investigated. Deep learning relates to a type of machine learning technique, where its aim is to move closer to the goal of artificial intelligence of creating a machine that could successfully perform any intellectual tasks that can be carried out by a human. In this paper, we propose the implementation strategy of three popular metaheuristic approaches, that is, simulated annealing, differential evolution, and harmony search, to optimize CNN. The performances of these metaheuristic methods in optimizing CNN on classifying MNIST and CIFAR dataset were evaluated and compared. Furthermore, the proposed methods are also compared with the original CNN. Although the proposed methods show an increase in the computation time, their accuracy has also been improved (up to 7.14 percent).
* Article ID 1537325, 13 pages. Received 29 January 2016; Revised 15 April 2016; Accepted 10 May 2016. Academic Editor: Martin Hagan. in Hindawi Publishing. Computational Intelligence and Neuroscience Volume 2016 (2016)
Adaptive Online Sequential ELM for Concept Drift Tackling
Oct 06, 2016



A machine learning method needs to adapt to over time changes in the environment. Such changes are known as concept drift. In this paper, we propose concept drift tackling method as an enhancement of Online Sequential Extreme Learning Machine (OS-ELM) and Constructive Enhancement OS-ELM (CEOS-ELM) by adding adaptive capability for classification and regression problem. The scheme is named as adaptive OS-ELM (AOS-ELM). It is a single classifier scheme that works well to handle real drift, virtual drift, and hybrid drift. The AOS-ELM also works well for sudden drift and recurrent context change type. The scheme is a simple unified method implemented in simple lines of code. We evaluated AOS-ELM on regression and classification problem by using concept drift public data set (SEA and STAGGER) and other public data sets such as MNIST, USPS, and IDS. Experiments show that our method gives higher kappa value compared to the multiclassifier ELM ensemble. Even though AOS-ELM in practice does not need hidden nodes increase, we address some issues related to the increasing of the hidden nodes such as error condition and rank values. We propose taking the rank of the pseudoinverse matrix as an indicator parameter to detect underfitting condition.
* Hindawi Publishing. Computational Intelligence and Neuroscience Volume 2016 (2016), Article ID 8091267, 17 pages Received 29 January 2016, Accepted 17 May 2016. Special Issue on "Advances in Neural Networks and Hybrid-Metaheuristics: Theory, Algorithms, and Novel Engineering Applications". Academic Editor: Stefan Haufe
A New Data Representation Based on Training Data Characteristics to Extract Drug Named-Entity in Medical Text
Oct 06, 2016



One essential task in information extraction from the medical corpus is drug name recognition. Compared with text sources come from other domains, the medical text is special and has unique characteristics. In addition, the medical text mining poses more challenges, e.g., more unstructured text, the fast growing of new terms addition, a wide range of name variation for the same drug. The mining is even more challenging due to the lack of labeled dataset sources and external knowledge, as well as multiple token representations for a single drug name that is more common in the real application setting. Although many approaches have been proposed to overwhelm the task, some problems remained with poor F-score performance (less than 0.75). This paper presents a new treatment in data representation techniques to overcome some of those challenges. We propose three data representation techniques based on the characteristics of word distribution and word similarities as a result of word embedding training. The first technique is evaluated with the standard NN model, i.e., MLP (Multi-Layer Perceptrons). The second technique involves two deep network classifiers, i.e., DBN (Deep Belief Networks), and SAE (Stacked Denoising Encoders). The third technique represents the sentence as a sequence that is evaluated with a recurrent NN model, i.e., LSTM (Long Short Term Memory). In extracting the drug name entities, the third technique gives the best F-score performance compared to the state of the art, with its average F-score being 0.8645.
* Hindawi Publishing. Computational Intelligence and Neuroscience Volume 2016 (2016), Article ID 3483528, 24 pages Received 27 May 2016; Revised 8 August 2016; Accepted 18 September 2016. Special Issue on "Smart Data: Where the Big Data Meets the Semantics". Academic Editor: Trong H. Duong
Multiple Regularizations Deep Learning for Paddy Growth Stages Classification from LANDSAT-8
Oct 06, 2016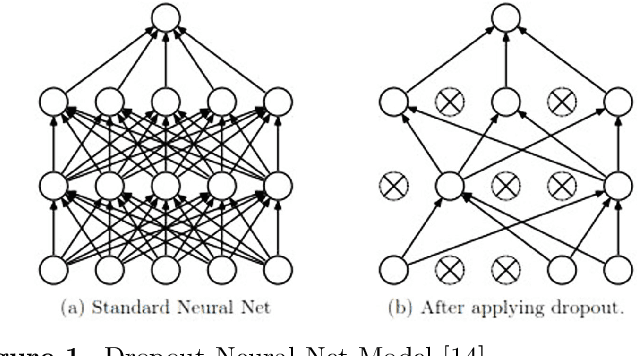
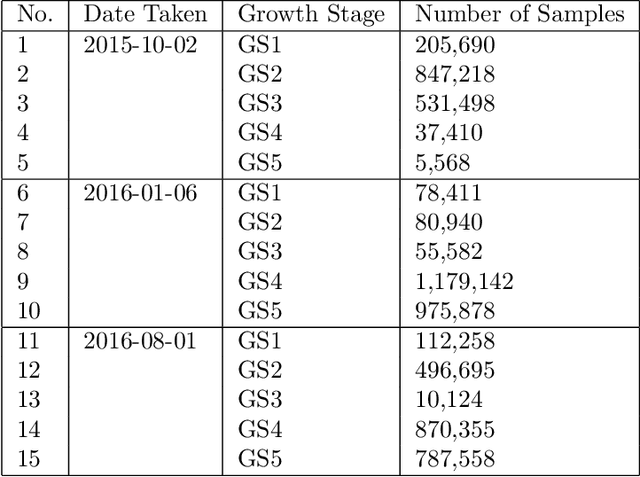
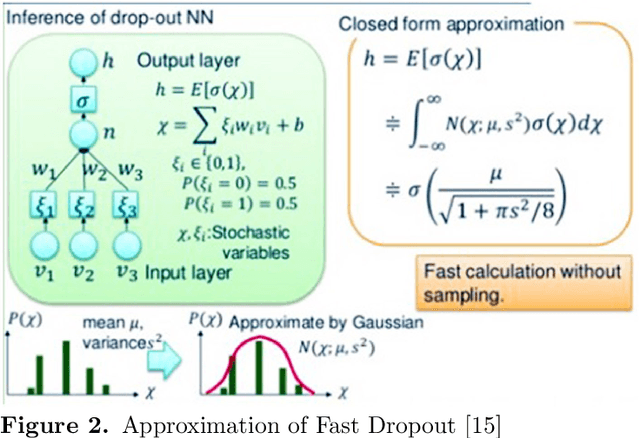
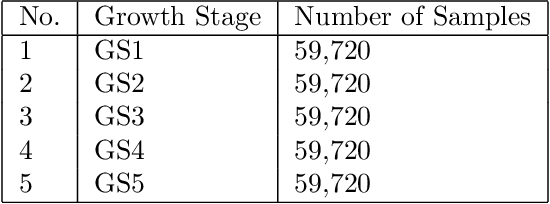
This study uses remote sensing technology that can provide information about the condition of the earth's surface area, fast, and spatially. The study area was in Karawang District, lying in the Northern part of West Java-Indonesia. We address a paddy growth stages classification using LANDSAT 8 image data obtained from multi-sensor remote sensing image taken in October 2015 to August 2016. This study pursues a fast and accurate classification of paddy growth stages by employing multiple regularizations learning on some deep learning methods such as DNN (Deep Neural Networks) and 1-D CNN (1-D Convolutional Neural Networks). The used regularizations are Fast Dropout, Dropout, and Batch Normalization. To evaluate the effectiveness, we also compared our method with other machine learning methods such as (Logistic Regression, SVM, Random Forest, and XGBoost). The data used are seven bands of LANDSAT-8 spectral data samples that correspond to paddy growth stages data obtained from i-Sky (eye in the sky) Innovation system. The growth stages are determined based on paddy crop phenology profile from time series of LANDSAT-8 images. The classification results show that MLP using multiple regularization Dropout and Batch Normalization achieves the highest accuracy for this dataset.
Ischemic Stroke Identification Based on EEG and EOG using 1D Convolutional Neural Network and Batch Normalization
Oct 06, 2016



In 2015, stroke was the number one cause of death in Indonesia. The majority type of stroke is ischemic. The standard tool for diagnosing stroke is CT-Scan. For developing countries like Indonesia, the availability of CT-Scan is very limited and still relatively expensive. Because of the availability, another device that potential to diagnose stroke in Indonesia is EEG. Ischemic stroke occurs because of obstruction that can make the cerebral blood flow (CBF) on a person with stroke has become lower than CBF on a normal person (control) so that the EEG signal have a deceleration. On this study, we perform the ability of 1D Convolutional Neural Network (1DCNN) to construct classification model that can distinguish the EEG and EOG stroke data from EEG and EOG control data. To accelerate training process our model we use Batch Normalization. Involving 62 person data object and from leave one out the scenario with five times repetition of measurement we obtain the average of accuracy 0.86 (F-Score 0.861) only at 200 epoch. This result is better than all over shallow and popular classifiers as the comparator (the best result of accuracy 0.69 and F-Score 0.72 ). The feature used in our study were only 24 handcrafted feature with simple feature extraction process.
Combining Generative and Discriminative Neural Networks for Sleep Stages Classification
Oct 06, 2016

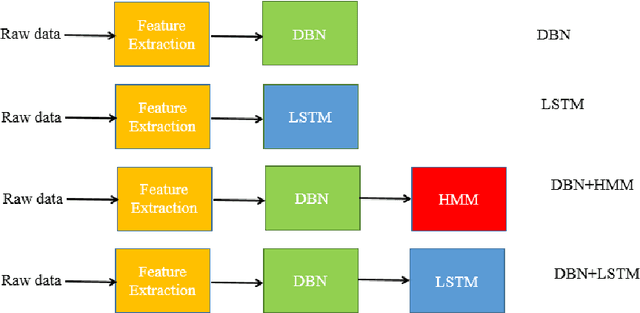

Sleep stages pattern provides important clues in diagnosing the presence of sleep disorder. By analyzing sleep stages pattern and extracting its features from EEG, EOG, and EMG signals, we can classify sleep stages. This study presents a novel classification model for predicting sleep stages with a high accuracy. The main idea is to combine the generative capability of Deep Belief Network (DBN) with a discriminative ability and sequence pattern recognizing capability of Long Short-term Memory (LSTM). We use DBN that is treated as an automatic higher level features generator. The input to DBN is 28 "handcrafted" features as used in previous sleep stages studies. We compared our method with other techniques which combined DBN with Hidden Markov Model (HMM).In this study, we exploit the sequence or time series characteristics of sleep dataset. To the best of our knowledge, most of the present sleep analysis from polysomnogram relies only on single instanced label (nonsequence) for classification. In this study, we used two datasets: an open data set that is treated as a benchmark; the other dataset is our sleep stages dataset (available for download) to verify the results further. Our experiments showed that the combination of DBN with LSTM gives better overall accuracy 98.75\% (Fscore=0.9875) for benchmark dataset and 98.94\% (Fscore=0.9894) for MKG dataset. This result is better than the state of the art of sleep stages classification that was 91.31\%.