 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInequality Constrained Stochastic Nonlinear Optimization via Active-Set Sequential Quadratic Programming
Sep 23, 2021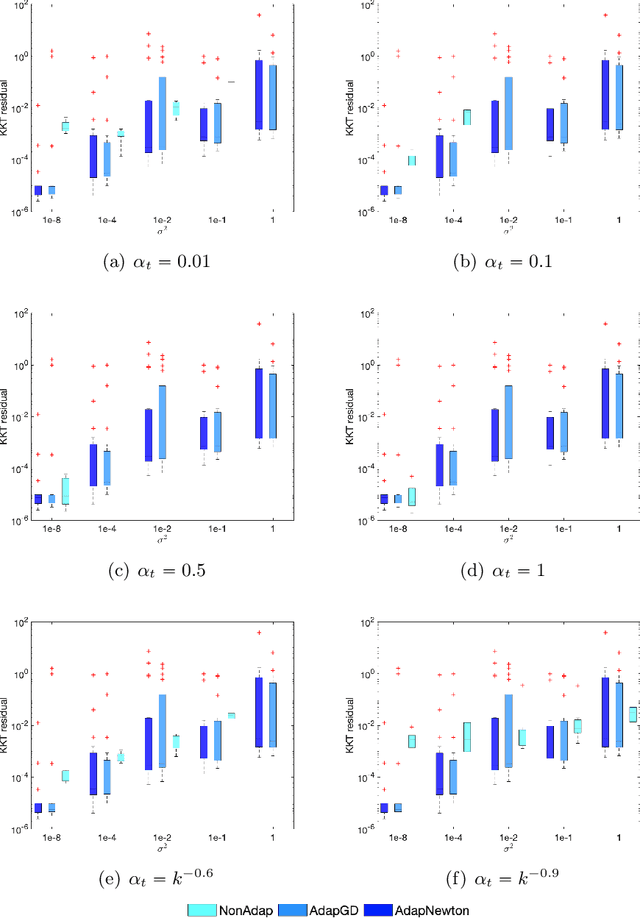
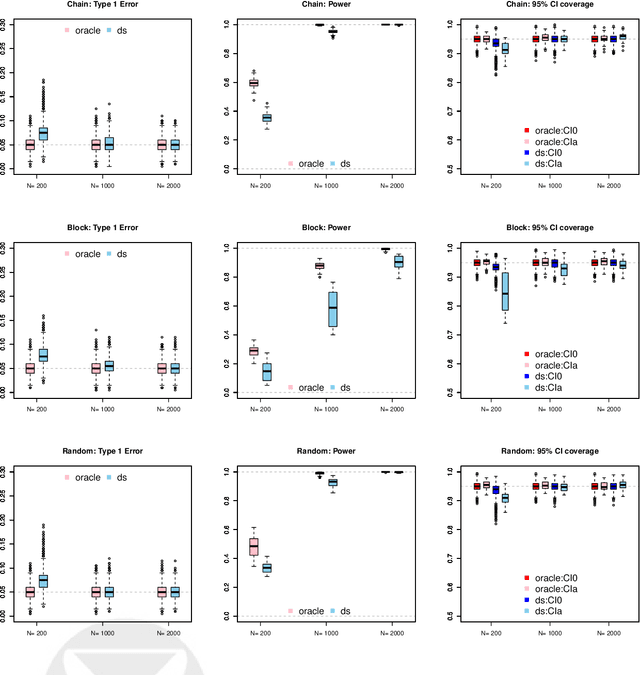
We study nonlinear optimization problems with stochastic objective and deterministic equality and inequality constraints, which emerge in numerous applications including finance, manufacturing, power systems and, recently, deep neural networks. We propose an active-set stochastic sequential quadratic programming algorithm, using a differentiable exact augmented Lagrangian as the merit function. The algorithm adaptively selects the penalty parameters of augmented Lagrangian and performs stochastic line search to decide the stepsize. The global convergence is established: for any initialization, the "liminf" of the KKT residuals converges to zero almost surely. Our algorithm and analysis further develop the prior work \cite{Na2021Adaptive} by allowing nonlinear inequality constraints. We demonstrate the performance of the algorithm on a subset of nonlinear problems collected in the CUTEst test set.
Local AdaGrad-Type Algorithm for Stochastic Convex-Concave Minimax Problems
Jun 18, 2021
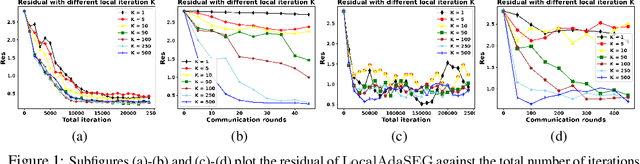
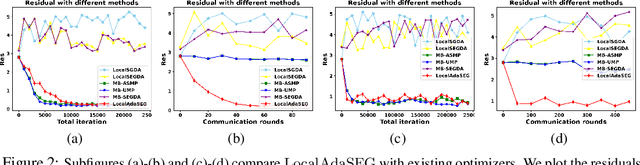
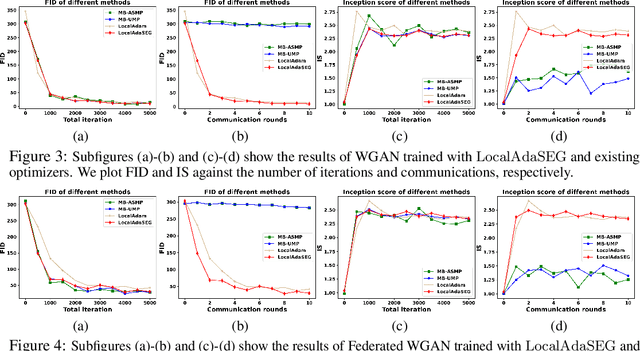
Large scale convex-concave minimax problems arise in numerous applications, including game theory, robust training, and training of generative adversarial networks. Despite their wide applicability, solving such problems efficiently and effectively is challenging in the presence of large amounts of data using existing stochastic minimax methods. We study a class of stochastic minimax methods and develop a communication-efficient distributed stochastic extragradient algorithm, LocalAdaSEG, with an adaptive learning rate suitable for solving convex-concave minimax problem in the Parameter-Server model. LocalAdaSEG has three main features: (i) periodic communication strategy reduces the communication cost between workers and the server; (ii) an adaptive learning rate that is computed locally and allows for tuning-free implementation; and (iii) theoretically, a nearly linear speed-up with respect to the dominant variance term, arising from estimation of the stochastic gradient, is proven in both the smooth and nonsmooth convex-concave settings. LocalAdaSEG is used to solve a stochastic bilinear game, and train generative adversarial network. We compare LocalAdaSEG against several existing optimizers for minimax problems and demonstrate its efficacy through several experiments in both the homogeneous and heterogeneous settings.
Robust Inference for High-Dimensional Linear Models via Residual Randomization
Jun 14, 2021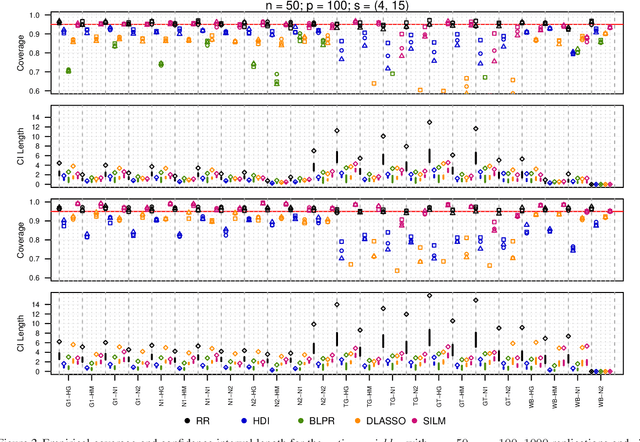

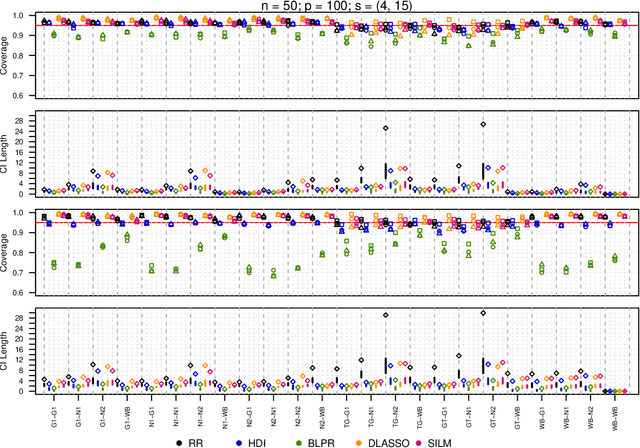
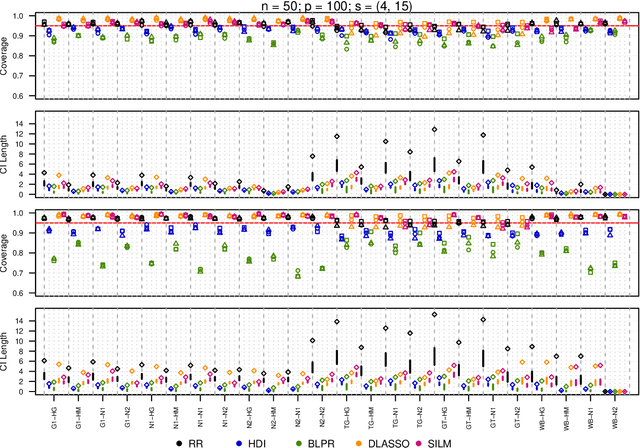
We propose a residual randomization procedure designed for robust Lasso-based inference in the high-dimensional setting. Compared to earlier work that focuses on sub-Gaussian errors, the proposed procedure is designed to work robustly in settings that also include heavy-tailed covariates and errors. Moreover, our procedure can be valid under clustered errors, which is important in practice, but has been largely overlooked by earlier work. Through extensive simulations, we illustrate our method's wider range of applicability as suggested by theory. In particular, we show that our method outperforms state-of-art methods in challenging, yet more realistic, settings where the distribution of covariates is heavy-tailed or the sample size is small, while it remains competitive in standard, ``well behaved" settings previously studied in the literature.
High-dimensional Functional Graphical Model Structure Learning via Neighborhood Selection Approach
May 06, 2021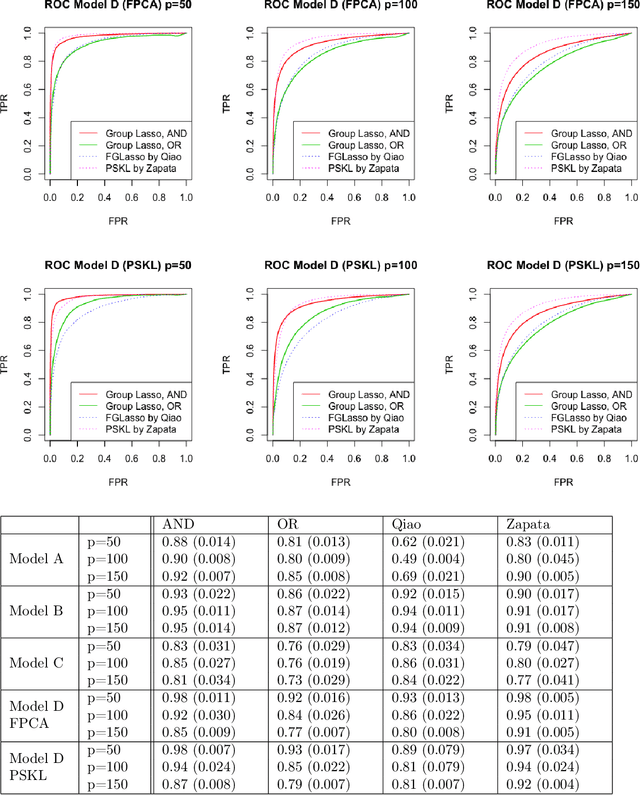
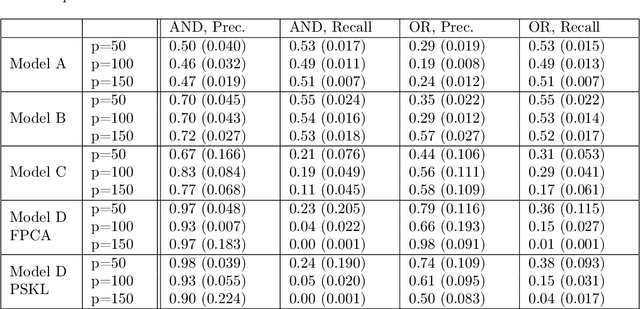
Undirected graphical models have been widely used to model the conditional independence structure of high-dimensional random vector data for years. In many modern applications such as EEG and fMRI data, the observations are multivariate random functions rather than scalars. To model the conditional independence of this type of data, functional graphical models are proposed and have attracted an increasing attention in recent years. In this paper, we propose a neighborhood selection approach to estimate Gaussian functional graphical models. We first estimate the neighborhood of all nodes via function-on-function regression, and then we can recover the whole graph structure based on the neighborhood information. By estimating conditional structure directly, we can circumvent the need of a well-defined precision operator which generally does not exist. Besides, we can better explore the effect of the choice of function basis for dimension reduction. We give a criterion for choosing the best function basis and motivate two practically useful choices, which we justified by both theory and experiments and show that they are better than expanding each function onto its own FPCA basis as in previous literature. In addition, the neighborhood selection approach is computationally more efficient than fglasso as it is more easy to do parallel computing. The statistical consistency of our proposed methods in high-dimensional setting are supported by both theory and experiment.
Instrumental Variable Value Iteration for Causal Offline Reinforcement Learning
Feb 19, 2021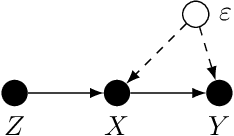
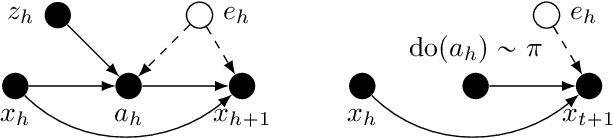
In offline reinforcement learning (RL) an optimal policy is learnt solely from a priori collected observational data. However, in observational data, actions are often confounded by unobserved variables. Instrumental variables (IVs), in the context of RL, are the variables whose influence on the state variables are all mediated through the action. When a valid instrument is present, we can recover the confounded transition dynamics through observational data. We study a confounded Markov decision process where the transition dynamics admit an additive nonlinear functional form. Using IVs, we derive a conditional moment restriction (CMR) through which we can identify transition dynamics based on observational data. We propose a provably efficient IV-aided Value Iteration (IVVI) algorithm based on a primal-dual reformulation of CMR. To the best of our knowledge, this is the first provably efficient algorithm for instrument-aided offline RL.
Personalized Federated Learning: A Unified Framework and Universal Optimization Techniques
Feb 19, 2021
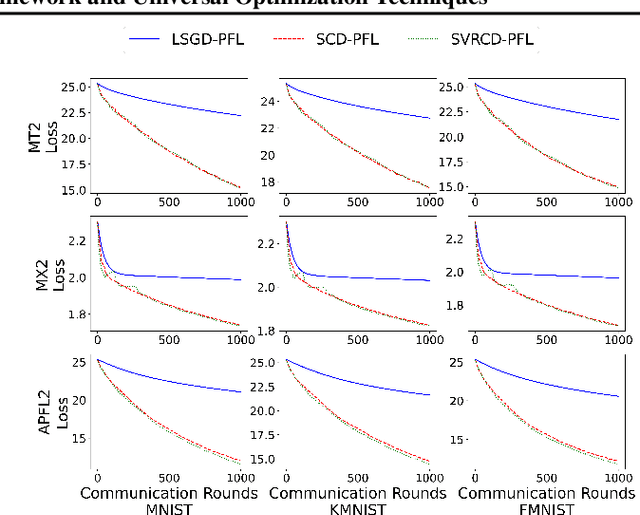

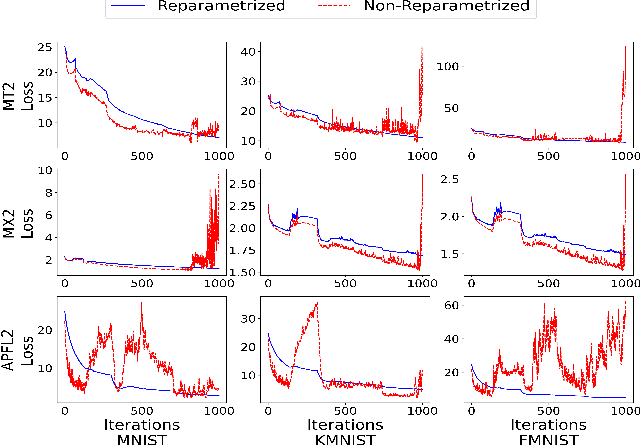
We study the optimization aspects of personalized Federated Learning (FL). We develop a universal optimization theory applicable to all convex personalized FL models in the literature. In particular, we propose a general personalized objective capable of recovering essentially any existing personalized FL objective as a special case. We design several optimization techniques to minimize the general objective, namely a tailored variant of Local SGD and variants of accelerated coordinate descent/accelerated SVRCD. We demonstrate the practicality and/or optimality of our methods both in terms of communication and local computation. Lastly, we argue about the implications of our general optimization theory when applied to solve specific personalized FL objectives.
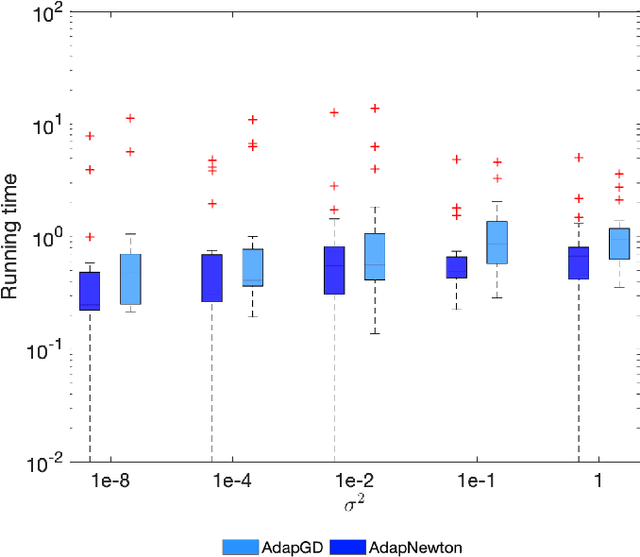
An Adaptive Stochastic Sequential Quadratic Programming with Differentiable Exact Augmented Lagrangians
Feb 10, 2021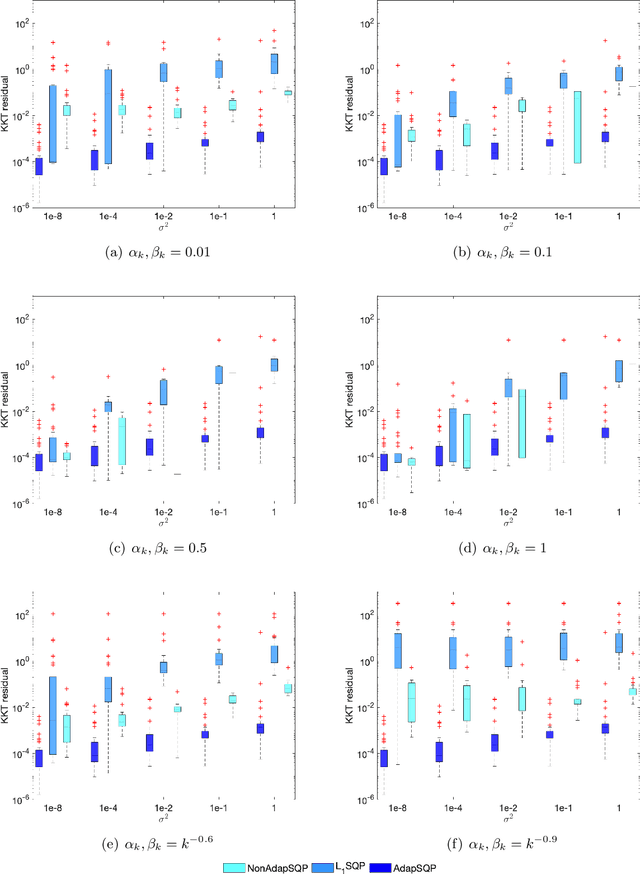
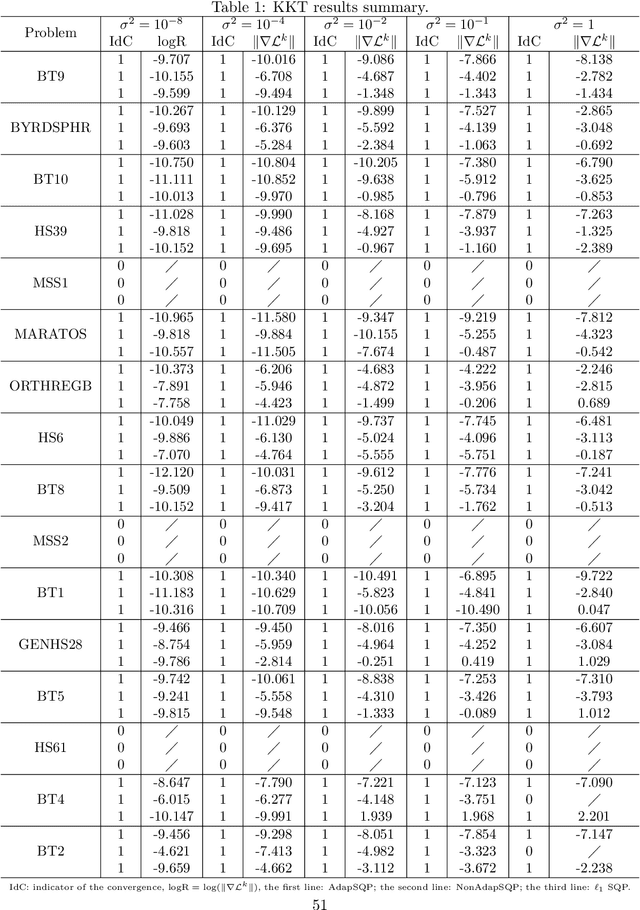

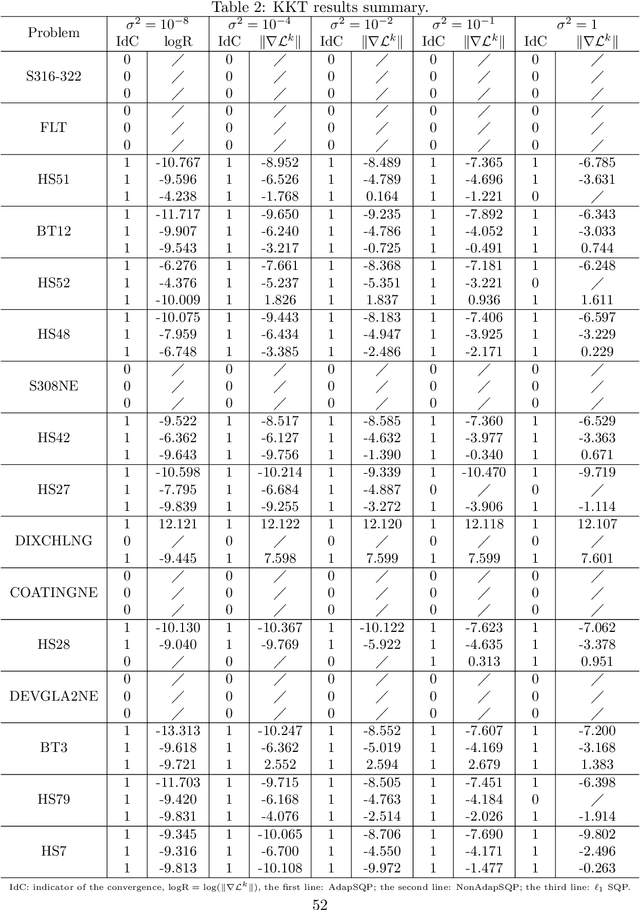
We consider the problem of solving nonlinear optimization programs with stochastic objective and deterministic equality constraints. We assume for the objective that the function evaluation, the gradient, and the Hessian are inaccessible, while one can compute their stochastic estimates by, for example, subsampling. We propose a stochastic algorithm based on sequential quadratic programming (SQP) that uses a differentiable exact augmented Lagrangian as the merit function. To motivate our algorithm, we revisit an old SQP method \citep{Lucidi1990Recursive} developed for deterministic programs. We simplify that method and derive an adaptive SQP, which serves as the skeleton of our stochastic algorithm. Based on the derived algorithm, we then propose a non-adaptive SQP for optimizing stochastic objectives, where the gradient and the Hessian are replaced by stochastic estimates but the stepsize is deterministic and prespecified. Finally, we incorporate a recent stochastic line search procedure \citep{Paquette2020Stochastic} into our non-adaptive stochastic SQP to arrive at an adaptive stochastic SQP. To our knowledge, the proposed algorithm is the first stochastic SQP that allows a line search procedure and the first stochastic line search procedure that allows the constraints. The global convergence for all proposed SQP methods is established, while numerical experiments on nonlinear problems in the CUTEst test set demonstrate the superiority of the proposed algorithm.
Provably Training Neural Network Classifiers under Fairness Constraints
Dec 30, 2020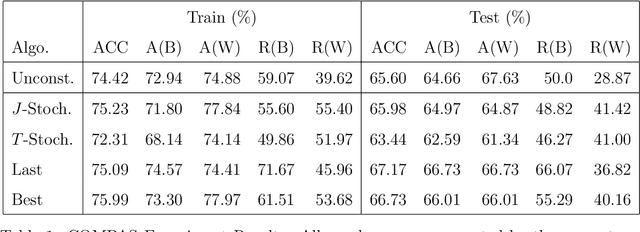
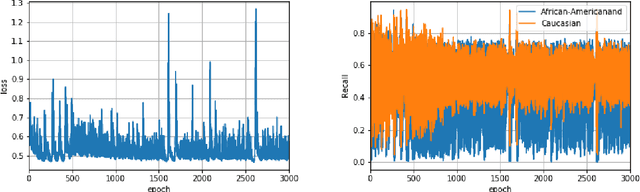
Training a classifier under fairness constraints has gotten increasing attention in the machine learning community thanks to moral, legal, and business reasons. However, several recent works addressing algorithmic fairness have only focused on simple models such as logistic regression or support vector machines due to non-convex and non-differentiable fairness criteria across protected groups, such as race or gender. Neural networks, the most widely used models for classification nowadays, are precluded and lack theoretical guarantees. This paper aims to fill this missing but crucial part of the literature of algorithmic fairness for neural networks. In particular, we show that overparametrized neural networks could meet the fairness constraints. The key ingredient of building a fair neural network classifier is establishing no-regret analysis for neural networks in the overparameterization regime, which may be of independent interest in the online learning of neural networks and related applications.
A Nonconvex Framework for Structured Dynamic Covariance Recovery
Nov 11, 2020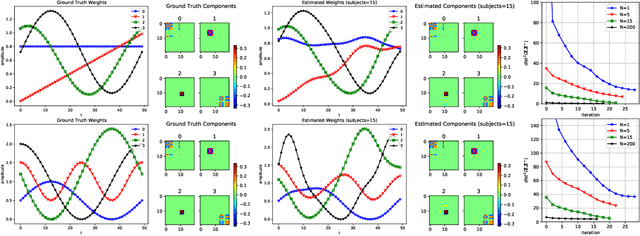
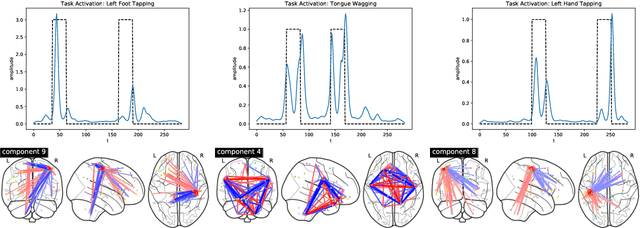
We propose a flexible yet interpretable model for high-dimensional data with time-varying second order statistics, motivated and applied to functional neuroimaging data. Motivated by the neuroscience literature, we factorize the covariances into sparse spatial and smooth temporal components. While this factorization results in both parsimony and domain interpretability, the resulting estimation problem is nonconvex. To this end, we design a two-stage optimization scheme with a carefully tailored spectral initialization, combined with iteratively refined alternating projected gradient descent. We prove a linear convergence rate up to a nontrivial statistical error for the proposed descent scheme and establish sample complexity guarantees for the estimator. We further quantify the statistical error for the multivariate Gaussian case. Empirical results using simulated and real brain imaging data illustrate that our approach outperforms existing baselines.
Statistical Inference for Networks of High-Dimensional Point Processes
Jul 15, 2020
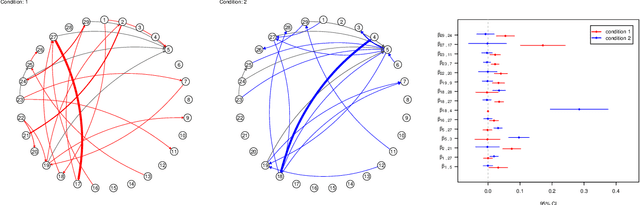
Fueled in part by recent applications in neuroscience, the multivariate Hawkes process has become a popular tool for modeling the network of interactions among high-dimensional point process data. While evaluating the uncertainty of the network estimates is critical in scientific applications, existing methodological and theoretical work has primarily addressed estimation. To bridge this gap, this paper develops a new statistical inference procedure for high-dimensional Hawkes processes. The key ingredient for this inference procedure is a new concentration inequality on the first- and second-order statistics for integrated stochastic processes, which summarize the entire history of the process. Combining recent results on martingale central limit theory with the new concentration inequality, we then characterize the convergence rate of the test statistics. We illustrate finite sample validity of our inferential tools via extensive simulations and demonstrate their utility by applying them to a neuron spike train data set.