 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossAug: A Contrastive Data Augmentation Method for Debiasing Fact Verification Models
Sep 30, 2021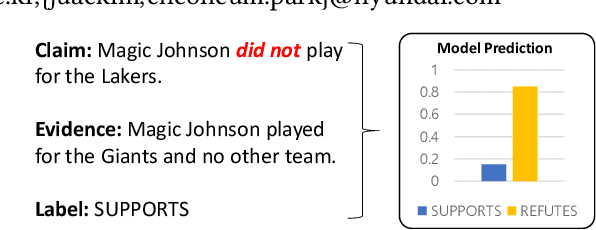
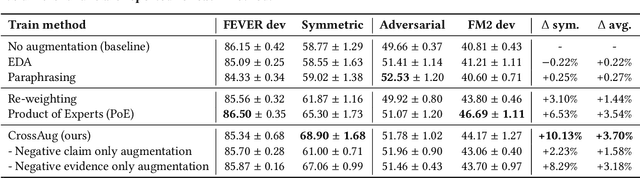
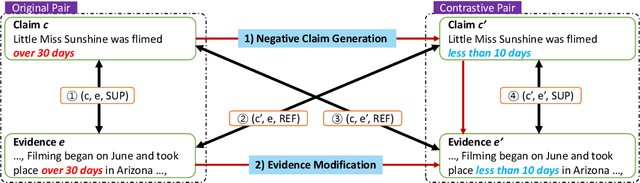
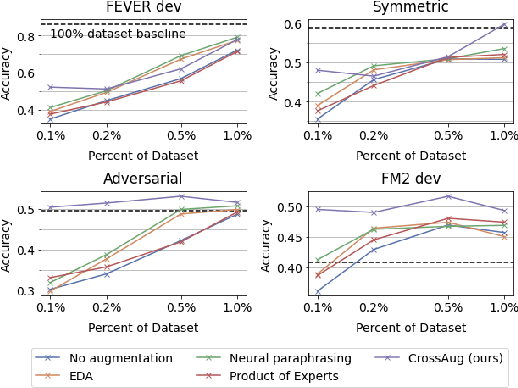
Fact verification datasets are typically constructed using crowdsourcing techniques due to the lack of text sources with veracity labels. However, the crowdsourcing process often produces undesired biases in data that cause models to learn spurious patterns. In this paper, we propose CrossAug, a contrastive data augmentation method for debiasing fact verification models. Specifically, we employ a two-stage augmentation pipeline to generate new claims and evidences from existing samples. The generated samples are then paired cross-wise with the original pair, forming contrastive samples that facilitate the model to rely less on spurious patterns and learn more robust representations. Experimental results show that our method outperforms the previous state-of-the-art debiasing technique by 3.6% on the debiased extension of the FEVER dataset, with a total performance boost of 10.13% from the baseline. Furthermore, we evaluate our approach in data-scarce settings, where models can be more susceptible to biases due to the lack of training data. Experimental results demonstrate that our approach is also effective at debiasing in these low-resource conditions, exceeding the baseline performance on the Symmetric dataset with just 1% of the original data.
MutualNet: Adaptive ConvNet via Mutual Learning from Different Model Configurations
May 14, 2021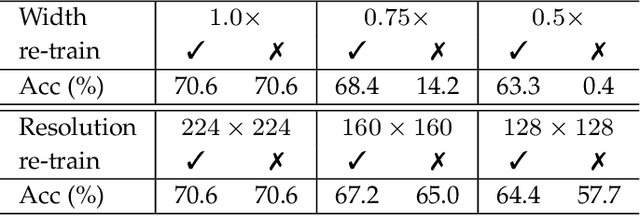


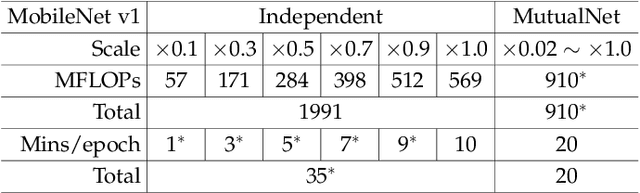
Most existing deep neural networks are static, which means they can only do inference at a fixed complexity. But the resource budget can vary substantially across different devices. Even on a single device, the affordable budget can change with different scenarios, and repeatedly training networks for each required budget would be incredibly expensive. Therefore, in this work, we propose a general method called MutualNet to train a single network that can run at a diverse set of resource constraints. Our method trains a cohort of model configurations with various network widths and input resolutions. This mutual learning scheme not only allows the model to run at different width-resolution configurations but also transfers the unique knowledge among these configurations, helping the model to learn stronger representations overall. MutualNet is a general training methodology that can be applied to various network structures (e.g., 2D networks: MobileNets, ResNet, 3D networks: SlowFast, X3D) and various tasks (e.g., image classification, object detection, segmentation, and action recognition), and is demonstrated to achieve consistent improvements on a variety of datasets. Since we only train the model once, it also greatly reduces the training cost compared to independently training several models. Surprisingly, MutualNet can also be used to significantly boost the performance of a single network, if dynamic resource constraint is not a concern. In summary, MutualNet is a unified method for both static and adaptive, 2D and 3D networks. Codes and pre-trained models are available at \url{https://github.com/taoyang1122/MutualNet}.
Demystifying Deep Neural Networks Through Interpretation: A Survey
Jan 05, 2021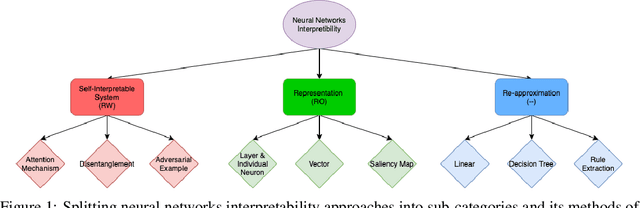
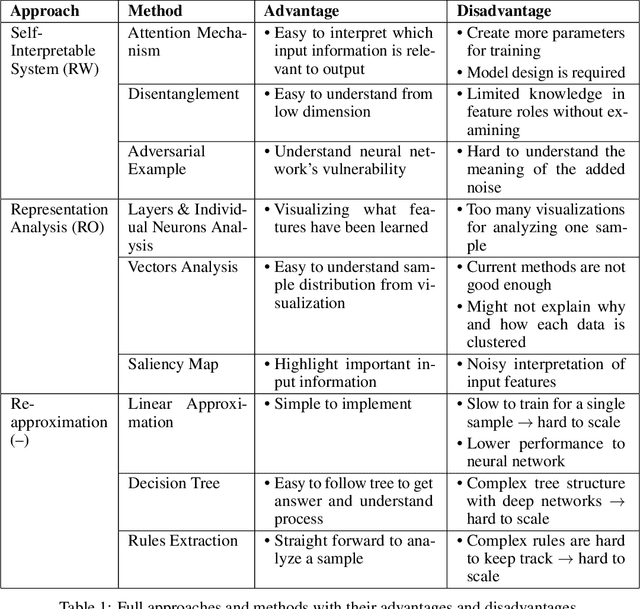
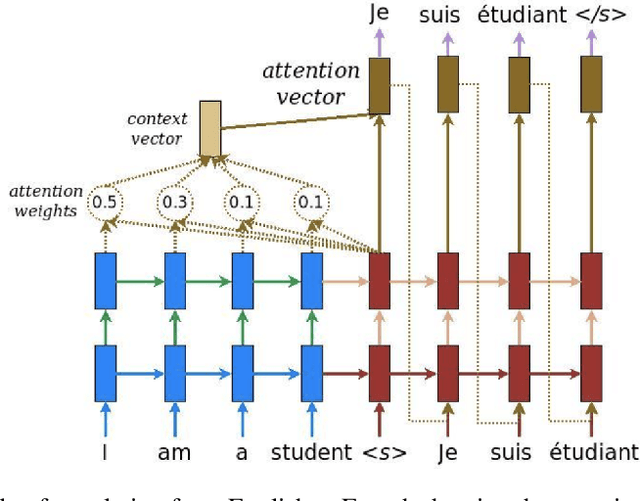
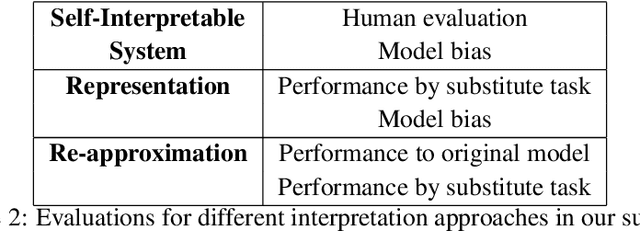
Modern deep learning algorithms tend to optimize an objective metric, such as minimize a cross entropy loss on a training dataset, to be able to learn. The problem is that the single metric is an incomplete description of the real world tasks. The single metric cannot explain why the algorithm learn. When an erroneous happens, the lack of interpretability causes a hardness of understanding and fixing the error. Recently, there are works done to tackle the problem of interpretability to provide insights into neural networks behavior and thought process. The works are important to identify potential bias and to ensure algorithm fairness as well as expected performance.
Few-Shot Keyword Spotting With Prototypical Networks
Jul 25, 2020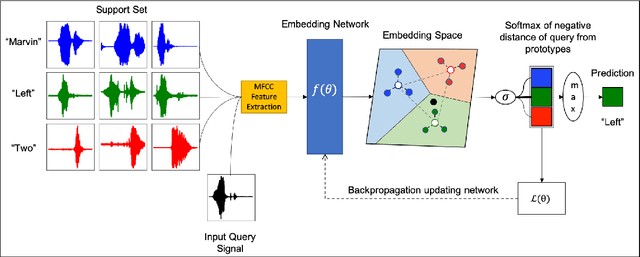
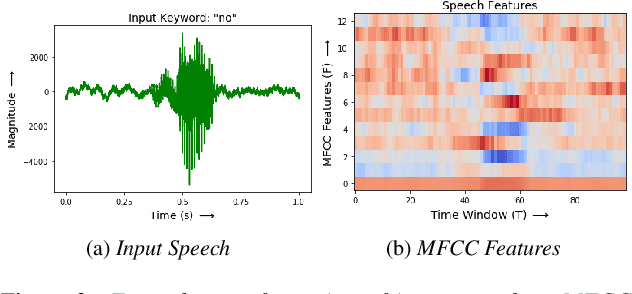
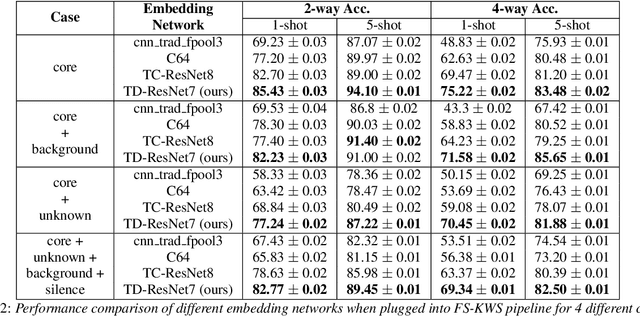
Recognizing a particular command or a keyword, keyword spotting has been widely used in many voice interfaces such as Amazon's Alexa and Google Home. In order to recognize a set of keywords, most of the recent deep learning based approaches use a neural network trained with a large number of samples to identify certain pre-defined keywords. This restricts the system from recognizing new, user-defined keywords. Therefore, we first formulate this problem as a few-shot keyword spotting and approach it using metric learning. To enable this research, we also synthesize and publish a Few-shot Google Speech Commands dataset. We then propose a solution to the few-shot keyword spotting problem using temporal and dilated convolutions on prototypical networks. Our comparative experimental results demonstrate keyword spotting of new keywords using just a small number of samples.
Deep learning method to remove chemical, kinetic and electric artifacts on ISEs
Jun 05, 2020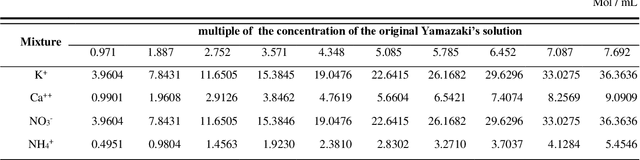
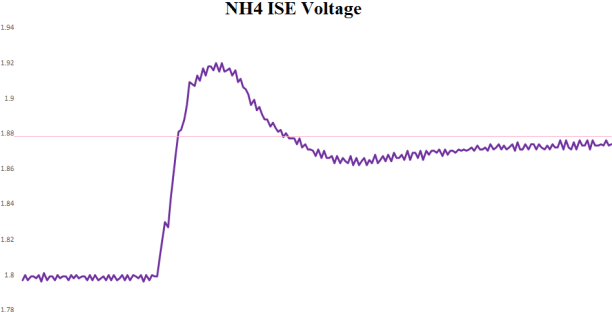
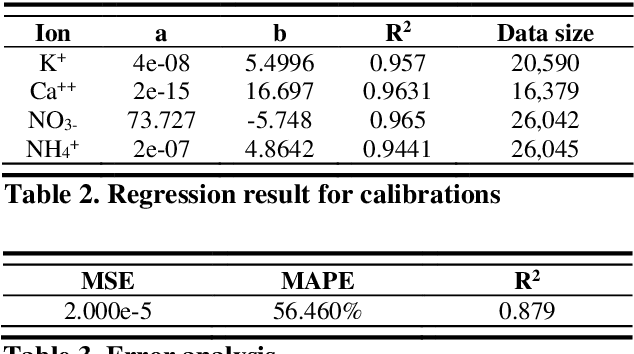
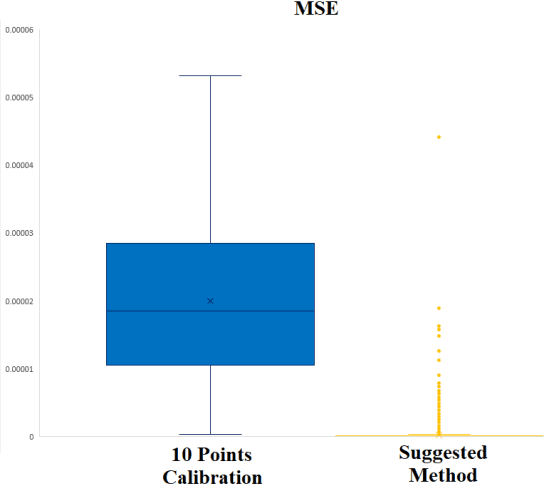
We suggest a deep learning based sensor signal processing method to remove chemical, kinetic and electrical artifacts from ion selective electrodes' measured values. An ISE is used to investigate the concentration of a specific ion from aqueous solution, by measuring the Nernst potential along the glass membrane. However, application of ISE on a mixture of multiple ion has some problem. First problem is a chemical artifact which is called ion interference effect. Electrically charged particles interact with each other and flows through the glass membrane of different ISEs. Second problem is the kinetic artifact caused by the movement of the liquid. Water molecules collide with the glass membrane causing abnormal peak values of voltage. The last artifact is the interference of ISEs. When multiple ISEs are dipped into same solution, one electrode's signal emission interference voltage measurement of other electrodes. Therefore, an ISE is recommended to be applied on single-ion solution, without any other sensors applied at the same time. Deep learning approach can remove both 3 artifacts at the same time. The proposed method used 5 layers of artificial neural networks to regress correct signal to remove complex artifacts with one-shot calculation. Its MAPE was less than 1.8% and R2 of regression was 0.997. A randomly chosen value of AI-processed data has MAPE less than 5% (p-value 0.016).
Drug-disease Graph: Predicting Adverse Drug Reaction Signals via Graph Neural Network with Clinical Data
Apr 01, 2020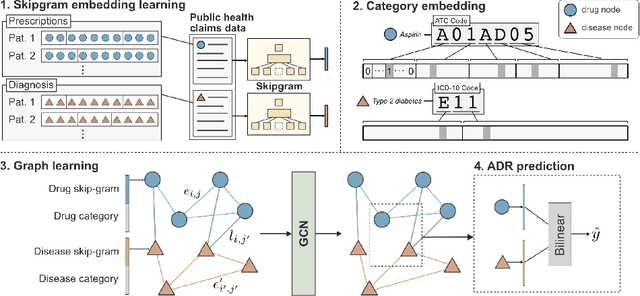

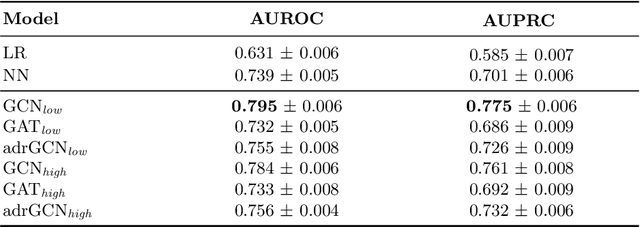

Adverse Drug Reaction (ADR) is a significant public health concern world-wide. Numerous graph-based methods have been applied to biomedical graphs for predicting ADRs in pre-marketing phases. ADR detection in post-market surveillance is no less important than pre-marketing assessment, and ADR detection with large-scale clinical data have attracted much attention in recent years. However, there are not many studies considering graph structures from clinical data for detecting an ADR signal, which is a pair of a prescription and a diagnosis that might be a potential ADR. In this study, we develop a novel graph-based framework for ADR signal detection using healthcare claims data. We construct a Drug-disease graph with nodes representing the medical codes. The edges are given as the relationships between two codes, computed using the data. We apply Graph Neural Network to predict ADR signals, using labels from the Side Effect Resource database. The model shows improved AUROC and AUPRC performance of 0.795 and 0.775, compared to other algorithms, showing that it successfully learns node representations expressive of those relationships. Furthermore, our model predicts ADR pairs that do not exist in the established ADR database, showing its capability to supplement the ADR database.
Machine learning approach to remove ion interference effect in agricultural nutrient solutions
Sep 03, 2019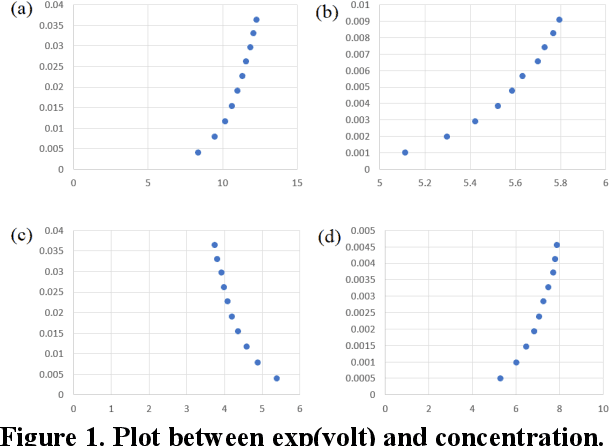
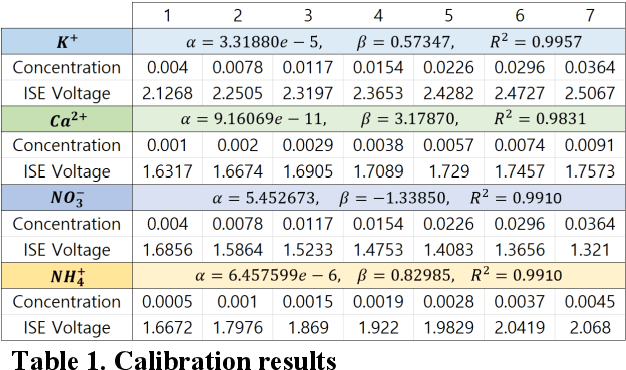
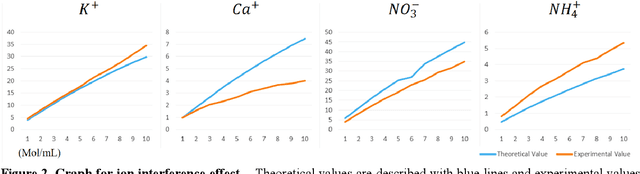
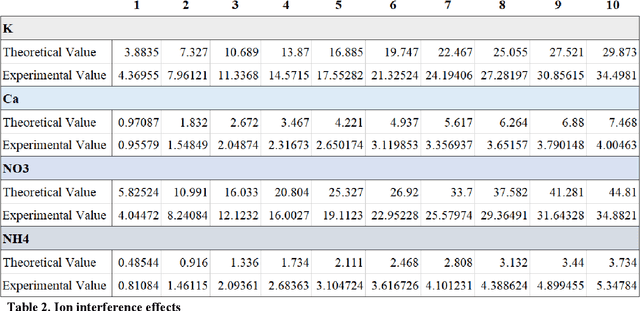
High concentration agricultural facilities such as vertical farms or plant factories consider hydroponic techniques as optimal solutions. Although closed-system dramatically reduces water consumption and pollution issues, it has ion-ratio related problem. As the root absorbs individual ions with different rate, ion rate in a nutrient solution should be adjusted periodically. But traditional method only considers pH and electrical conductivity to adjust the nutrient solution, leading to ion imbalance and accumulation of excessive salts. To avoid those problems, some researchers have proposed ion-balancing methods which measure and control each ion concentration. However, those approaches do not overcome the innate limitations of ISEs, especially ion interference effect. An anion sensor is affected by other anions, and the error grows larger in higher concentration solution. A machine learning approach to modify ISE data distorted by ion interference effect is proposed in this paper. As measurement of TDS value is relatively robust than any other signals, we applied TDS as key parameter to build a readjustment function to remove the artifact. Once a readjustment model is established, application on ISE data can be done in real time. Readjusted data with proposed model showed about 91.6 ~ 98.3% accuracies. This method will enable the fields to apply recent methods in feasible status.
Proceedings of the 1st International Workshop on Robot Learning and Planning
Oct 08, 2016

Proceedings of the 1st International Workshop on Robot Learning and Planning (RLP 2016)