 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalluJudge: A Reference-Free Hallucination Detection for Context Misalignment in Code Review Automation
Jan 27, 2026Large Language models (LLMs) have shown strong capabilities in code review automation, such as review comment generation, yet they suffer from hallucinations -- where the generated review comments are ungrounded in the actual code -- poses a significant challenge to the adoption of LLMs in code review workflows. To address this, we explore effective and scalable methods for a hallucination detection in LLM-generated code review comments without the reference. In this work, we design HalluJudge that aims to assess the grounding of generated review comments based on the context alignment. HalluJudge includes four key strategies ranging from direct assessment to structured multi-branch reasoning (e.g., Tree-of-Thoughts). We conduct a comprehensive evaluation of these assessment strategies across Atlassian's enterprise-scale software projects to examine the effectiveness and cost-efficiency of HalluJudge. Furthermore, we analyze the alignment between HalluJudge's judgment and developer preference of the actual LLM-generated code review comments in the real-world production. Our results show that the hallucination assessment in HalluJudge is cost-effective with an F1 score of 0.85 and an average cost of $0.009. On average, 67% of the HalluJudge assessments are aligned with the developer preference of the actual LLM-generated review comments in the online production. Our results suggest that HalluJudge can serve as a practical safeguard to reduce developers' exposure to hallucinated comments, fostering trust in AI-assisted code reviews.
AgenticSCR: An Autonomous Agentic Secure Code Review for Immature Vulnerabilities Detection
Jan 27, 2026Secure code review is critical at the pre-commit stage, where vulnerabilities must be caught early under tight latency and limited-context constraints. Existing SAST-based checks are noisy and often miss immature, context-dependent vulnerabilities, while standalone Large Language Models (LLMs) are constrained by context windows and lack explicit tool use. Agentic AI, which combine LLMs with autonomous decision-making, tool invocation, and code navigation, offer a promising alternative, but their effectiveness for pre-commit secure code review is not yet well understood. In this work, we introduce AgenticSCR, an agentic AI for secure code review for detecting immature vulnerabilities during the pre-commit stage, augmented by security-focused semantic memories. Using our own curated benchmark of immature vulnerabilities, tailored to the pre-commit secure code review, we empirically evaluate how accurate is our AgenticSCR for localizing, detecting, and explaining immature vulnerabilities. Our results show that AgenticSCR achieves at least 153% relatively higher percentage of correct code review comments than the static LLM-based baseline, and also substantially surpasses SAST tools. Moreover, AgenticSCR generates more correct comments in four out of five vulnerability types, consistently and significantly outperforming all other baselines. These findings highlight the importance of Agentic Secure Code Review, paving the way towards an emerging research area of immature vulnerability detection.
RovoDev Code Reviewer: A Large-Scale Online Evaluation of LLM-based Code Review Automation at Atlassian
Jan 03, 2026Large Language Models (LLMs)-powered code review automation has the potential to transform code review workflows. Despite the advances of LLM-powered code review comment generation approaches, several practical challenges remain for designing enterprise-grade code review automation tools. In particular, this paper aims at answering the practical question: how can we design a review-guided, context-aware, quality-checked code review comment generation without fine-tuning? In this paper, we present RovoDev Code Reviewer, an enterprise-grade LLM-based code review automation tool designed and deployed at scale within Atlassian's development ecosystem with seamless integration into Atlassian's Bitbucket. Through the offline, online, user feedback evaluations over a one-year period, we conclude that RovoDev Code Reviewer is (1) effective in generating code review comments that could lead to code resolution for 38.70% (i.e., comments that triggered code changes in the subsequent commits); and (2) offers the promise of accelerating feedback cycles (i.e., decreasing the PR cycle time by 30.8%), alleviating reviewer workload (i.e., reducing the number of human-written comments by 35.6%), and improving overall software quality (i.e., finding errors with actionable suggestions).
AgentSUMO: An Agentic Framework for Interactive Simulation Scenario Generation in SUMO via Large Language Models
Nov 10, 2025The growing complexity of urban mobility systems has made traffic simulation indispensable for evidence-based transportation planning and policy evaluation. However, despite the analytical capabilities of platforms such as the Simulation of Urban MObility (SUMO), their application remains largely confined to domain experts. Developing realistic simulation scenarios requires expertise in network construction, origin-destination modeling, and parameter configuration for policy experimentation, creating substantial barriers for non-expert users such as policymakers, urban planners, and city officials. Moreover, the requests expressed by these users are often incomplete and abstract-typically articulated as high-level objectives, which are not well aligned with the imperative, sequential workflows employed in existing language-model-based simulation frameworks. To address these challenges, this study proposes AgentSUMO, an agentic framework for interactive simulation scenario generation via large language models. AgentSUMO departs from imperative, command-driven execution by introducing an adaptive reasoning layer that interprets user intents, assesses task complexity, infers missing parameters, and formulates executable simulation plans. The framework is structured around two complementary components, the Interactive Planning Protocol, which governs reasoning and user interaction, and the Model Context Protocol, which manages standardized communication and orchestration among simulation tools. Through this design, AgentSUMO converts abstract policy objectives into executable simulation scenarios. Experiments on urban networks in Seoul and Manhattan demonstrate that the agentic workflow achieves substantial improvements in traffic flow metrics while maintaining accessibility for non-expert users, successfully bridging the gap between policy goals and executable simulation workflows.
Subspace Learning for Personalized Federated Optimization
Sep 16, 2021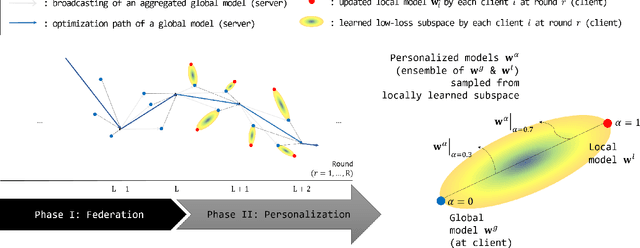
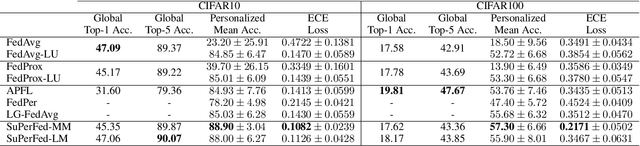
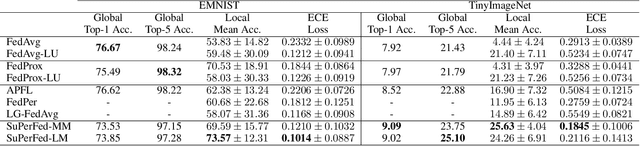
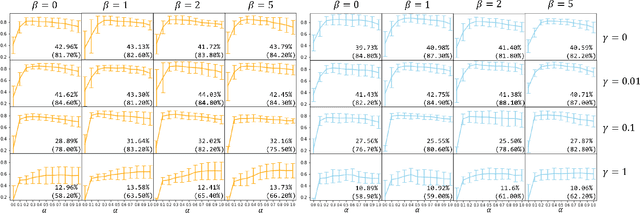
As data is generated and stored almost everywhere, learning a model from a data-decentralized setting is a task of interest for many AI-driven service providers. Although federated learning is settled down as the main solution in such situations, there still exists room for improvement in terms of personalization. Training federated learning systems usually focuses on optimizing a global model that is identically deployed to all client devices. However, a single global model is not sufficient for each client to be personalized on their performance as local data assumes to be not identically distributed across clients. We propose a method to address this situation through the lens of ensemble learning based on the construction of a low-loss subspace continuum that generates a high-accuracy ensemble of two endpoints (i.e. global model and local model). We demonstrate that our method achieves consistent gains both in personalized and unseen client evaluation settings through extensive experiments on several standard benchmark datasets.