 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisDoT : Enhancing Visual Reasoning through Human-Like Interpretation Grounding and Decomposition of Thought
Mar 12, 2026Large vision-language models (LVLMs) struggle to reliably detect visual primitives in charts and align them with semantic representations, which severely limits their performance on complex visual reasoning. This lack of perceptual grounding constitutes a major bottleneck for chart-based reasoning. We propose VisDoT, a framework that enhances visual reasoning through human-like interpretation grounding. We formalize four perceptual tasks based on the theory of graphical perception, including position and length. Building on this foundation, we introduce Decomposition-of-Thought (DoT) prompting, which sequentially separates questions into visual perception sub-questions and logic sub-questions. Fine-tuning InternVL with VisDoT achieves a +11.2% improvement on ChartQA and surpasses GPT-4o on the more challenging ChartQAPro benchmark. On the newly introduced VisDoTQA benchmark, the model improves by +33.2%. Furthermore, consistent zero-shot gains on diverse open-domain VQA benchmarks confirm the generalizability of the perception-logic separation strategy for visual question answering. VisDoT leverages human-like perception to enhance visual grounding, achieving state-of-the-art chart understanding and interpretable visual reasoning.
PEEM: Prompt Engineering Evaluation Metrics for Interpretable Joint Evaluation of Prompts and Responses
Mar 11, 2026Prompt design is a primary control interface for large language models (LLMs), yet standard evaluations largely reduce performance to answer correctness, obscuring why a prompt succeeds or fails and providing little actionable guidance. We propose PEEM (Prompt Engineering Evaluation Metrics), a unified framework for joint and interpretable evaluation of both prompts and responses. PEEM defines a structured rubric with 9 axes: 3 prompt criteria (clarity/structure, linguistic quality, fairness) and 6 response criteria (accuracy, coherence, relevance, objectivity, clarity, conciseness), and uses an LLM-based evaluator to output (i) scalar scores on a 1-5 Likert scale and (ii) criterion-specific natural-language rationales grounded in the rubric. Across 7 benchmarks and 5 task models, PEEM's accuracy axis strongly aligns with conventional accuracy while preserving model rankings (aggregate Spearman rho about 0.97, Pearson r about 0.94, p < 0.001). A multi-evaluator study with four models shows consistent relative judgments (pairwise rho = 0.68-0.85), supporting evaluator-agnostic deployment. Beyond alignment, PEEM captures complementary linguistic failure modes and remains informative under prompt perturbations: prompt-quality trends track downstream accuracy under iterative rewrites, semantic adversarial manipulations induce clear score degradation, and meaning-preserving paraphrases yield high stability (robustness rate about 76.7-80.6%). Finally, using only PEEM scores and rationales as feedback, a zero-shot prompt rewriting loop improves downstream accuracy by up to 11.7 points, outperforming supervised and RL-based prompt-optimization baselines. Overall, PEEM provides a reproducible, criterion-driven protocol that links prompt formulation to response behavior and enables systematic diagnosis and optimization of LLM interactions.
Evaluating Demographic Misrepresentation in Image-to-Image Portrait Editing
Feb 18, 2026Demographic bias in text-to-image (T2I) generation is well studied, yet demographic-conditioned failures in instruction-guided image-to-image (I2I) editing remain underexplored. We examine whether identical edit instructions yield systematically different outcomes across subject demographics in open-weight I2I editors. We formalize two failure modes: Soft Erasure, where edits are silently weakened or ignored in the output image, and Stereotype Replacement, where edits introduce unrequested, stereotype-consistent attributes. We introduce a controlled benchmark that probes demographic-conditioned behavior by generating and editing portraits conditioned on race, gender, and age using a diagnostic prompt set, and evaluate multiple editors with vision-language model (VLM) scoring and human evaluation. Our analysis shows that identity preservation failures are pervasive, demographically uneven, and shaped by implicit social priors, including occupation-driven gender inference. Finally, we demonstrate that a prompt-level identity constraint, without model updates, can substantially reduce demographic change for minority groups while leaving majority-group portraits largely unchanged, revealing asymmetric identity priors in current editors. Together, our findings establish identity preservation as a central and demographically uneven failure mode in I2I editing and motivate demographic-robust editing systems. Project page: https://seochan99.github.io/i2i-demographic-bias
MToFNet: Object Anti-Spoofing with Mobile Time-of-Flight Data
Oct 06, 2021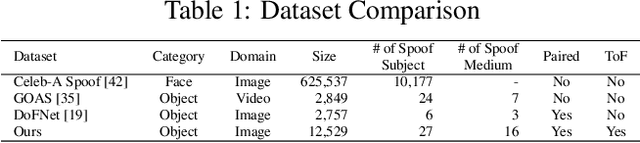
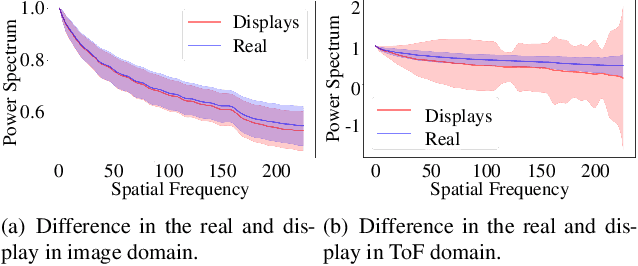

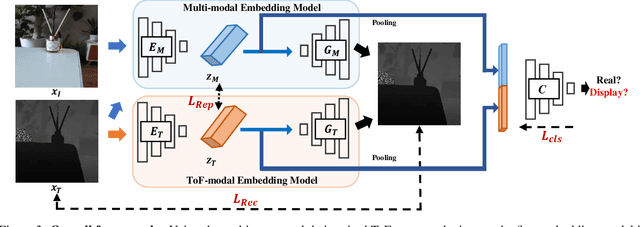
In online markets, sellers can maliciously recapture others' images on display screens to utilize as spoof images, which can be challenging to distinguish in human eyes. To prevent such harm, we propose an anti-spoofing method using the paired rgb images and depth maps provided by the mobile camera with a Time-of-Fight sensor. When images are recaptured on display screens, various patterns differing by the screens as known as the moir\'e patterns can be also captured in spoof images. These patterns lead the anti-spoofing model to be overfitted and unable to detect spoof images recaptured on unseen media. To avoid the issue, we build a novel representation model composed of two embedding models, which can be trained without considering the recaptured images. Also, we newly introduce mToF dataset, the largest and most diverse object anti-spoofing dataset, and the first to utilize ToF data. Experimental results confirm that our model achieves robust generalization even across unseen domains.