 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERSting at the Screams: A Benchmark for Distanced, Emotional and Shouted Speech Recognition
Apr 30, 2025Some speech recognition tasks, such as automatic speech recognition (ASR), are approaching or have reached human performance in many reported metrics. Yet, they continue to struggle in complex, real-world, situations, such as with distanced speech. Previous challenges have released datasets to address the issue of distanced ASR, however, the focus remains primarily on distance, specifically relying on multi-microphone array systems. Here we present the B(asic) E(motion) R(andom phrase) S(hou)t(s) (BERSt) dataset. The dataset contains almost 4 hours of English speech from 98 actors with varying regional and non-native accents. The data was collected on smartphones in the actors homes and therefore includes at least 98 different acoustic environments. The data also includes 7 different emotion prompts and both shouted and spoken utterances. The smartphones were places in 19 different positions, including obstructions and being in a different room than the actor. This data is publicly available for use and can be used to evaluate a variety of speech recognition tasks, including: ASR, shout detection, and speech emotion recognition (SER). We provide initial benchmarks for ASR and SER tasks, and find that ASR degrades both with an increase in distance and shout level and shows varied performance depending on the intended emotion. Our results show that the BERSt dataset is challenging for both ASR and SER tasks and continued work is needed to improve the robustness of such systems for more accurate real-world use.
TrafficVLM: A Controllable Visual Language Model for Traffic Video Captioning
Apr 14, 2024

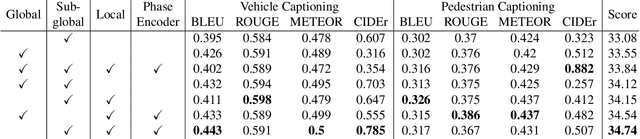
Traffic video description and analysis have received much attention recently due to the growing demand for efficient and reliable urban surveillance systems. Most existing methods only focus on locating traffic event segments, which severely lack descriptive details related to the behaviour and context of all the subjects of interest in the events. In this paper, we present TrafficVLM, a novel multi-modal dense video captioning model for vehicle ego camera view. TrafficVLM models traffic video events at different levels of analysis, both spatially and temporally, and generates long fine-grained descriptions for the vehicle and pedestrian at different phases of the event. We also propose a conditional component for TrafficVLM to control the generation outputs and a multi-task fine-tuning paradigm to enhance TrafficVLM's learning capability. Experiments show that TrafficVLM performs well on both vehicle and overhead camera views. Our solution achieved outstanding results in Track 2 of the AI City Challenge 2024, ranking us third in the challenge standings. Our code is publicly available at https://github.com/quangminhdinh/TrafficVLM.