 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysDrift: Bridging the Embodiment Gap in Humanoid Co-Speech Motion Generation
Jun 18, 2026Humanoid robots require co-speech motions that are not only expressive and speech-aligned, but also physically executable under embodiment constraints. Existing co-speech generation pipelines are predominantly human-centric: motions are first generated in human-body representations such as SMPL-X and subsequently retargeted to humanoid robots. In this work, we identify a fundamental embodiment gap in this paradigm, where the mismatch between human motion manifolds and humanoid embodiment constraints disrupts embodiment consistency during motion transfer and physical execution. Through extensive analysis, we show that although retargeting can preserve coarse motion semantics, it significantly compresses motion diversity and weakens prosody-motion synchronization, limiting expressive humanoid behaviors. To address this problem, we first propose IK-EER, a prosody-preserving humanoid motion curation framework that jointly optimizes kinematic feasibility and speech-motion temporal alignment during retargeting. Building upon the curated robot-native motion dataset, we further introduce PhysDrift, an embodiment-aware co-speech motion generation framework that directly predicts executable humanoid joint trajectories from speech without relying on intermediate human-body representations. Unlike conventional human-centric pipelines, PhysDrift maintains embodiment consistency throughout both training and inference while incorporating physical regularization to stabilize robot motion dynamics. Extensive experiments and real-world humanoid deployment demonstrate that embodiment-aware robot-native generation substantially improves speech-motion alignment, physical plausibility, motion smoothness, inference efficiency, and real-time interaction capability.
Retrieval Feedback Memory Enhancement Large Model Retrieval Generation Method
Aug 25, 2025Large Language Models (LLMs) have shown remarkable capabilities across diverse tasks, yet they face inherent limitations such as constrained parametric knowledge and high retraining costs. Retrieval-Augmented Generation (RAG) augments the generation process by retrieving externally stored knowledge absent from the models internal parameters. However, RAG methods face challenges such as information loss and redundant retrievals during multi-round queries, accompanying the difficulties in precisely characterizing knowledge gaps for complex tasks. To address these problems, we propose Retrieval Feedback and Memory Retrieval Augmented Generation(RFM-RAG), which transforms the stateless retrieval of previous methods into stateful continuous knowledge management by constructing a dynamic evidence pool. Specifically, our method generates refined queries describing the models knowledge gaps using relational triples from questions and evidence from the dynamic evidence pool; Retrieves critical external knowledge to iteratively update this evidence pool; Employs a R-Feedback Model to evaluate evidence completeness until convergence. Compared to traditional RAG methods, our approach enables persistent storage of retrieved passages and effectively distills key information from passages to construct clearly new queries. Experiments on three public QA benchmarks demonstrate that RFM-RAG outperforms previous methods and improves overall system accuracy.
CEIDM: A Controlled Entity and Interaction Diffusion Model for Enhanced Text-to-Image Generation
Aug 25, 2025In Text-to-Image (T2I) generation, the complexity of entities and their intricate interactions pose a significant challenge for T2I method based on diffusion model: how to effectively control entity and their interactions to produce high-quality images. To address this, we propose CEIDM, a image generation method based on diffusion model with dual controls for entity and interaction. First, we propose an entity interactive relationships mining approach based on Large Language Models (LLMs), extracting reasonable and rich implicit interactive relationships through chain of thought to guide diffusion models to generate high-quality images that are closer to realistic logic and have more reasonable interactive relationships. Furthermore, We propose an interactive action clustering and offset method to cluster and offset the interactive action features contained in each text prompts. By constructing global and local bidirectional offsets, we enhance semantic understanding and detail supplementation of original actions, making the model's understanding of the concept of interactive "actions" more accurate and generating images with more accurate interactive actions. Finally, we design an entity control network which generates masks with entity semantic guidance, then leveraging multi-scale convolutional network to enhance entity feature and dynamic network to fuse feature. It effectively controls entities and significantly improves image quality. Experiments show that the proposed CEIDM method is better than the most representative existing methods in both entity control and their interaction control.
Dynamic Embedding of Hierarchical Visual Features for Efficient Vision-Language Fine-Tuning
Aug 25, 2025Large Vision-Language Models (LVLMs) commonly follow a paradigm that projects visual features and then concatenates them with text tokens to form a unified sequence input for Large Language Models (LLMs). However, this paradigm leads to a significant increase in the length of the input sequence, resulting in substantial computational overhead. Existing methods attempt to fuse visual information into the intermediate layers of LLMs, which alleviate the sequence length issue but often neglect the hierarchical semantic representations within the model and the fine-grained visual information available in the shallower visual encoding layers. To address this limitation, we propose DEHVF, an efficient vision-language fine-tuning method based on dynamic embedding and fusion of hierarchical visual features. Its core lies in leveraging the inherent hierarchical representation characteristics of visual encoders and language models. Through a lightweight hierarchical visual fuser, it dynamically selects and fuses hierarchical features corresponding to semantic granularity based on the internal representations of each layer in LLMs. The fused layer-related visual features are then projected and aligned before being directly embedded into the Feed-Forward Network (FFN) of the corresponding layer in LLMs. This approach not only avoids sequence expansion but also dynamically fuses multi-layer visual information. By fine-tuning only a small number of parameters, DEHVF achieves precise alignment and complementarity of cross-modal information at the same semantic granularity. We conducted experiments across various VL benchmarks, including visual question answering on ScienceQA and image captioning on COCO Captions. The results demonstrate that DEHVF achieves higher accuracy than existing parameter-efficient fine-tuning (PEFT) baselines while maintaining efficient training and inference.
Separation and Collaboration: Two-Level Routing Grouped Mixture-of-Experts for Multi-Domain Continual Learning
Aug 11, 2025Multi-Domain Continual Learning (MDCL) acquires knowledge from sequential tasks with shifting class sets and distribution. Despite the Parameter-Efficient Fine-Tuning (PEFT) methods can adapt for this dual heterogeneity, they still suffer from catastrophic forgetting and forward forgetting. To address these challenges, we propose a Two-Level Routing Grouped Mixture-of-Experts (TRGE) method. Firstly, TRGE dynamically expands the pre-trained CLIP model, assigning specific expert group for each task to mitigate catastrophic forgetting. With the number of experts continually grows in this process, TRGE maintains the static experts count within the group and introduces the intra-group router to alleviate routing overfitting caused by the increasing routing complexity. Meanwhile, we design an inter-group routing policy based on task identifiers and task prototype distance, which dynamically selects relevant expert groups and combines their outputs to enhance inter-task collaboration. Secondly, to get the correct task identifiers, we leverage Multimodal Large Language Models (MLLMs) which own powerful multimodal comprehension capabilities to generate semantic task descriptions and recognize the correct task identifier. Finally, to mitigate forward forgetting, we dynamically fuse outputs for unseen samples from the frozen CLIP model and TRGE adapter based on training progress, leveraging both pre-trained and learned knowledge. Through extensive experiments across various settings, our method outperforms other advanced methods with fewer trainable parameters.
Deep Optimized Priors for 3D Shape Modeling and Reconstruction
Dec 14, 2020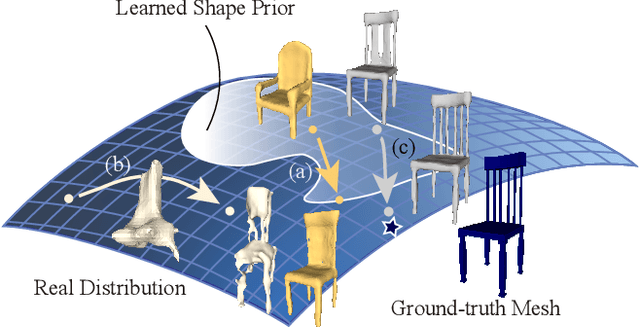
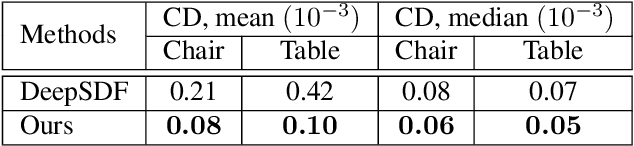
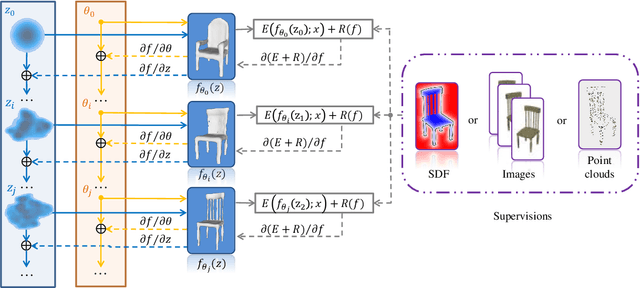
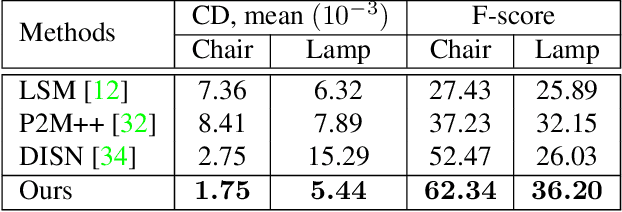
Many learning-based approaches have difficulty scaling to unseen data, as the generality of its learned prior is limited to the scale and variations of the training samples. This holds particularly true with 3D learning tasks, given the sparsity of 3D datasets available. We introduce a new learning framework for 3D modeling and reconstruction that greatly improves the generalization ability of a deep generator. Our approach strives to connect the good ends of both learning-based and optimization-based methods. In particular, unlike the common practice that fixes the pre-trained priors at test time, we propose to further optimize the learned prior and latent code according to the input physical measurements after the training. We show that the proposed strategy effectively breaks the barriers constrained by the pre-trained priors and could lead to high-quality adaptation to unseen data. We realize our framework using the implicit surface representation and validate the efficacy of our approach in a variety of challenging tasks that take highly sparse or collapsed observations as input. Experimental results show that our approach compares favorably with the state-of-the-art methods in terms of both generality and accuracy.