 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision tree heuristics can fail, even in the smoothed setting
Jul 02, 2021Greedy decision tree learning heuristics are mainstays of machine learning practice, but theoretical justification for their empirical success remains elusive. In fact, it has long been known that there are simple target functions for which they fail badly (Kearns and Mansour, STOC 1996). Recent work of Brutzkus, Daniely, and Malach (COLT 2020) considered the smoothed analysis model as a possible avenue towards resolving this disconnect. Within the smoothed setting and for targets $f$ that are $k$-juntas, they showed that these heuristics successfully learn $f$ with depth-$k$ decision tree hypotheses. They conjectured that the same guarantee holds more generally for targets that are depth-$k$ decision trees. We provide a counterexample to this conjecture: we construct targets that are depth-$k$ decision trees and show that even in the smoothed setting, these heuristics build trees of depth $2^{\Omega(k)}$ before achieving high accuracy. We also show that the guarantees of Brutzkus et al. cannot extend to the agnostic setting: there are targets that are very close to $k$-juntas, for which these heuristics build trees of depth $2^{\Omega(k)}$ before achieving high accuracy.
Exponential Weights Algorithms for Selective Learning
Jun 29, 2021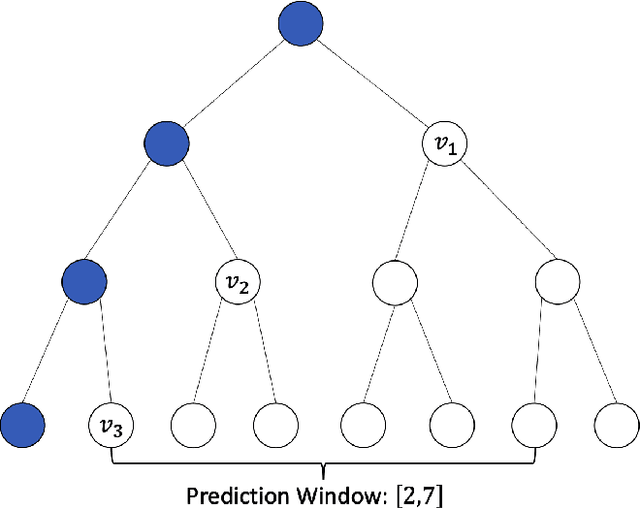
We study the selective learning problem introduced by Qiao and Valiant (2019), in which the learner observes $n$ labeled data points one at a time. At a time of its choosing, the learner selects a window length $w$ and a model $\hat\ell$ from the model class $\mathcal{L}$, and then labels the next $w$ data points using $\hat\ell$. The excess risk incurred by the learner is defined as the difference between the average loss of $\hat\ell$ over those $w$ data points and the smallest possible average loss among all models in $\mathcal{L}$ over those $w$ data points. We give an improved algorithm, termed the hybrid exponential weights algorithm, that achieves an expected excess risk of $O((\log\log|\mathcal{L}| + \log\log n)/\log n)$. This result gives a doubly exponential improvement in the dependence on $|\mathcal{L}|$ over the best known bound of $O(\sqrt{|\mathcal{L}|/\log n})$. We complement the positive result with an almost matching lower bound, which suggests the worst-case optimality of the algorithm. We also study a more restrictive family of learning algorithms that are bounded-recall in the sense that when a prediction window of length $w$ is chosen, the learner's decision only depends on the most recent $w$ data points. We analyze an exponential weights variant of the ERM algorithm in Qiao and Valiant (2019). This new algorithm achieves an expected excess risk of $O(\sqrt{\log |\mathcal{L}|/\log n})$, which is shown to be nearly optimal among all bounded-recall learners. Our analysis builds on a generalized version of the selective mean prediction problem in Drucker (2013); Qiao and Valiant (2019), which may be of independent interest.
Stronger Calibration Lower Bounds via Sidestepping
Dec 07, 2020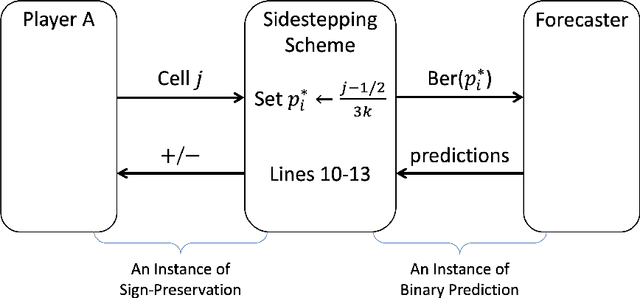
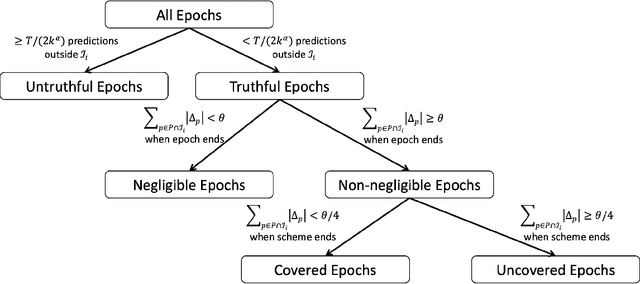
We consider an online binary prediction setting where a forecaster observes a sequence of $T$ bits one by one. Before each bit is revealed, the forecaster predicts the probability that the bit is $1$. The forecaster is called well-calibrated if for each $p \in [0, 1]$, among the $n_p$ bits for which the forecaster predicts probability $p$, the actual number of ones, $m_p$, is indeed equal to $p \cdot n_p$. The calibration error, defined as $\sum_p |m_p - p n_p|$, quantifies the extent to which the forecaster deviates from being well-calibrated. It has long been known that an $O(T^{2/3})$ calibration error is achievable even when the bits are chosen adversarially, and possibly based on the previous predictions. However, little is known on the lower bound side, except an $\Omega(\sqrt{T})$ bound that follows from the trivial example of independent fair coin flips. In this paper, we prove an $\Omega(T^{0.528})$ bound on the calibration error, which is the first super-$\sqrt{T}$ lower bound for this setting to the best of our knowledge. The technical contributions of our work include two lower bound techniques, early stopping and sidestepping, which circumvent the obstacles that have previously hindered strong calibration lower bounds. We also propose an abstraction of the prediction setting, termed the Sign-Preservation game, which may be of independent interest. This game has a much smaller state space than the full prediction setting and allows simpler analyses. The $\Omega(T^{0.528})$ lower bound follows from a general reduction theorem that translates lower bounds on the game value of Sign-Preservation into lower bounds on the calibration error.
A Theory of Selective Prediction
Feb 27, 2019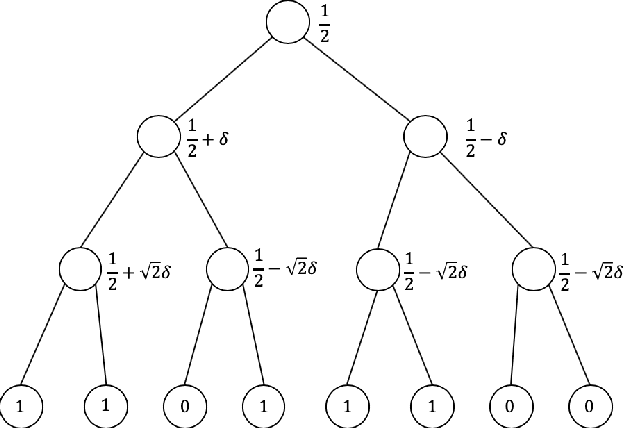
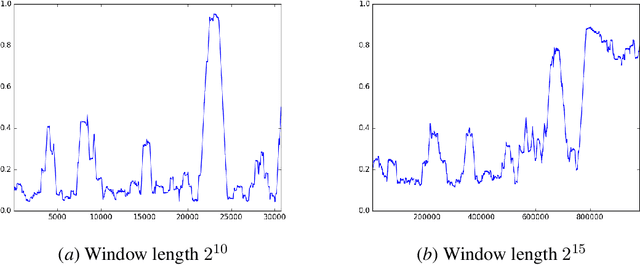
We consider a model of selective prediction, where the prediction algorithm is given a data sequence in an online fashion and asked to predict a pre-specified statistic of the upcoming data points. The algorithm is allowed to choose when to make the prediction as well as the length of the prediction window, possibly depending on the observations so far. We prove that, even without any distributional assumption on the input data stream, a large family of statistics can be estimated to non-trivial accuracy. To give one concrete example, suppose that we are given access to an arbitrary binary sequence $x_1, \ldots, x_n$ of length $n$. Our goal is to accurately predict the average observation, and we are allowed to choose the window over which the prediction is made: for some $t < n$ and $m \le n - t$, after seeing $t$ observations we predict the average of $x_{t+1}, \ldots, x_{t+m}$. This particular problem was first studied in [Dru13] and referred to as the "density prediction game". We show that the expected squared error of our prediction can be bounded by $O(\frac{1}{\log n})$ and prove a matching lower bound, which resolves an open question raised in [Dru13]. This result holds for any sequence (that is not adaptive to when the prediction is made, or the predicted value), and the expectation of the error is with respect to the randomness of the prediction algorithm. Our results apply to more general statistics of a sequence of observations, and we highlight several open directions for future work.
On Generalization Error Bounds of Noisy Gradient Methods for Non-Convex Learning
Feb 02, 2019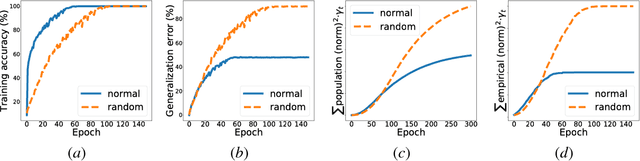
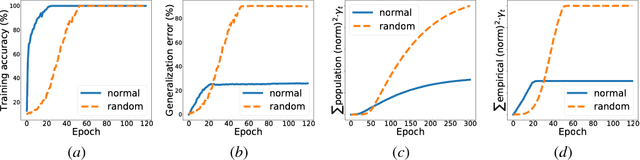
Generalization error (also known as the out-of-sample error) measures how well the hypothesis obtained from the training data can generalize to previously unseen data. Obtaining tight generalization error bounds is central to statistical learning theory. In this paper, we study the generalization error bound in learning general non-convex objectives, which has attracted significant attention in recent years. In particular, we study the (algorithm-dependent) generalization bounds of various iterative gradient based methods. (1) We present a very simple and elementary proof of a recent result for stochastic gradient Langevin dynamics (SGLD), due to Mou et al. (2018). Our proof can be easily extended to obtain similar generalization bounds for several other variants of SGLD (e.g., with postprocessing, momentum, mini-batch, acceleration, and more general noises), and improves upon the recent results in Pensia et al. (2018). (2) By incorporating ideas from the PAC-Bayesian theory into the stability framework, we obtain tighter distribution-dependent (or data-dependent) generalization bounds. Our bounds provide an intuitive explanation for the phenomenon reported in Zhang et al. (2017a). (3) We also study the setting where the total loss is the sum of a bounded loss and an additional `l2 regularization term. We obtain new generalization bounds for the continuous Langevin dynamic in this setting by leveraging the tool of Log-Sobolev inequality. Our new bounds are more desirable when the noisy level of the process is not small, and do not grow when T approaches to infinity.
Do Outliers Ruin Collaboration?
May 12, 2018We consider the problem of learning a binary classifier from $n$ different data sources, among which at most an $\eta$ fraction are adversarial. The overhead is defined as the ratio between the sample complexity of learning in this setting and that of learning the same hypothesis class on a single data distribution. We present an algorithm that achieves an $O(\eta n + \ln n)$ overhead, which is proved to be worst-case optimal. We also discuss the potential challenges to the design of a computationally efficient learning algorithm with a small overhead.
Learning Discrete Distributions from Untrusted Batches
Nov 22, 2017We consider the problem of learning a discrete distribution in the presence of an $\epsilon$ fraction of malicious data sources. Specifically, we consider the setting where there is some underlying distribution, $p$, and each data source provides a batch of $\ge k$ samples, with the guarantee that at least a $(1-\epsilon)$ fraction of the sources draw their samples from a distribution with total variation distance at most $\eta$ from $p$. We make no assumptions on the data provided by the remaining $\epsilon$ fraction of sources--this data can even be chosen as an adversarial function of the $(1-\epsilon)$ fraction of "good" batches. We provide two algorithms: one with runtime exponential in the support size, $n$, but polynomial in $k$, $1/\epsilon$ and $1/\eta$ that takes $O((n+k)/\epsilon^2)$ batches and recovers $p$ to error $O(\eta+\epsilon/\sqrt{k})$. This recovery accuracy is information theoretically optimal, to constant factors, even given an infinite number of data sources. Our second algorithm applies to the $\eta = 0$ setting and also achieves an $O(\epsilon/\sqrt{k})$ recover guarantee, though it runs in $\mathrm{poly}((nk)^k)$ time. This second algorithm, which approximates a certain tensor via a rank-1 tensor minimizing $\ell_1$ distance, is surprising in light of the hardness of many low-rank tensor approximation problems, and may be of independent interest.
Nearly Optimal Sampling Algorithms for Combinatorial Pure Exploration
Jun 04, 2017We study the combinatorial pure exploration problem Best-Set in stochastic multi-armed bandits. In a Best-Set instance, we are given $n$ arms with unknown reward distributions, as well as a family $\mathcal{F}$ of feasible subsets over the arms. Our goal is to identify the feasible subset in $\mathcal{F}$ with the maximum total mean using as few samples as possible. The problem generalizes the classical best arm identification problem and the top-$k$ arm identification problem, both of which have attracted significant attention in recent years. We provide a novel instance-wise lower bound for the sample complexity of the problem, as well as a nontrivial sampling algorithm, matching the lower bound up to a factor of $\ln|\mathcal{F}|$. For an important class of combinatorial families, we also provide polynomial time implementation of the sampling algorithm, using the equivalence of separation and optimization for convex program, and approximate Pareto curves in multi-objective optimization. We also show that the $\ln|\mathcal{F}|$ factor is inevitable in general through a nontrivial lower bound construction. Our results significantly improve several previous results for several important combinatorial constraints, and provide a tighter understanding of the general Best-Set problem. We further introduce an even more general problem, formulated in geometric terms. We are given $n$ Gaussian arms with unknown means and unit variance. Consider the $n$-dimensional Euclidean space $\mathbb{R}^n$, and a collection $\mathcal{O}$ of disjoint subsets. Our goal is to determine the subset in $\mathcal{O}$ that contains the $n$-dimensional vector of the means. The problem generalizes most pure exploration bandit problems studied in the literature. We provide the first nearly optimal sample complexity upper and lower bounds for the problem.
Towards Instance Optimal Bounds for Best Arm Identification
May 24, 2017In the classical best arm identification (Best-$1$-Arm) problem, we are given $n$ stochastic bandit arms, each associated with a reward distribution with an unknown mean. We would like to identify the arm with the largest mean with probability at least $1-\delta$, using as few samples as possible. Understanding the sample complexity of Best-$1$-Arm has attracted significant attention since the last decade. However, the exact sample complexity of the problem is still unknown. Recently, Chen and Li made the gap-entropy conjecture concerning the instance sample complexity of Best-$1$-Arm. Given an instance $I$, let $\mu_{[i]}$ be the $i$th largest mean and $\Delta_{[i]}=\mu_{[1]}-\mu_{[i]}$ be the corresponding gap. $H(I)=\sum_{i=2}^n\Delta_{[i]}^{-2}$ is the complexity of the instance. The gap-entropy conjecture states that $\Omega\left(H(I)\cdot\left(\ln\delta^{-1}+\mathsf{Ent}(I)\right)\right)$ is an instance lower bound, where $\mathsf{Ent}(I)$ is an entropy-like term determined by the gaps, and there is a $\delta$-correct algorithm for Best-$1$-Arm with sample complexity $O\left(H(I)\cdot\left(\ln\delta^{-1}+\mathsf{Ent}(I)\right)+\Delta_{[2]}^{-2}\ln\ln\Delta_{[2]}^{-1}\right)$. If the conjecture is true, we would have a complete understanding of the instance-wise sample complexity of Best-$1$-Arm. We make significant progress towards the resolution of the gap-entropy conjecture. For the upper bound, we provide a highly nontrivial algorithm which requires \[O\left(H(I)\cdot\left(\ln\delta^{-1} +\mathsf{Ent}(I)\right)+\Delta_{[2]}^{-2}\ln\ln\Delta_{[2]}^{-1}\mathrm{polylog}(n,\delta^{-1})\right)\] samples in expectation. For the lower bound, we show that for any Gaussian Best-$1$-Arm instance with gaps of the form $2^{-k}$, any $\delta$-correct monotone algorithm requires $\Omega\left(H(I)\cdot\left(\ln\delta^{-1} + \mathsf{Ent}(I)\right)\right)$ samples in expectation.
Practical Algorithms for Best-K Identification in Multi-Armed Bandits
May 19, 2017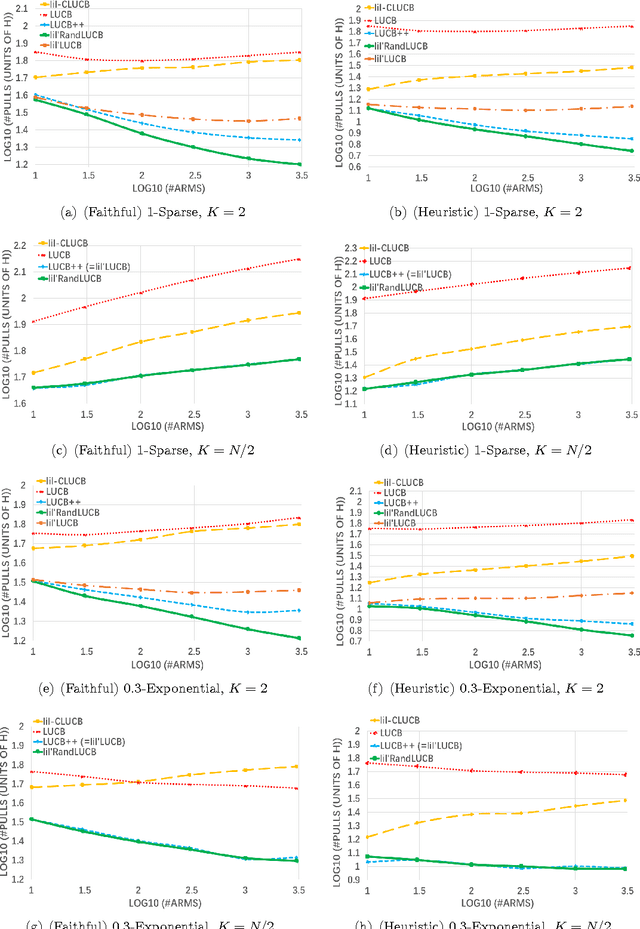
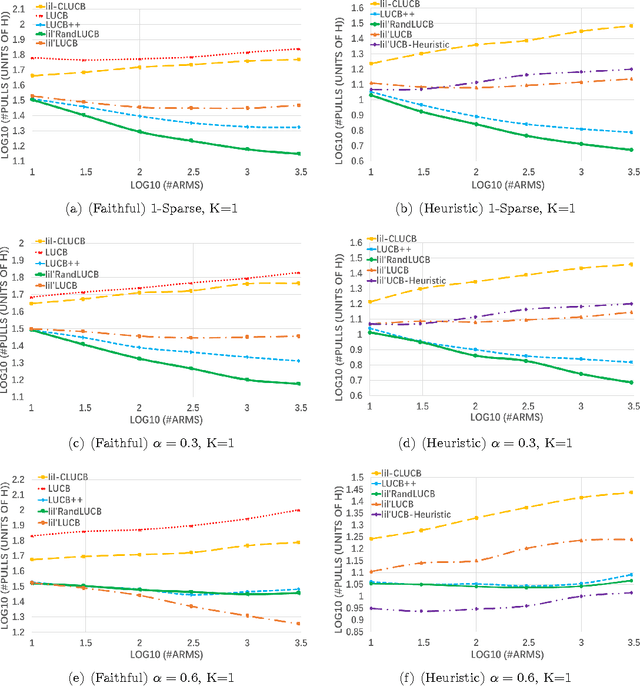
In the Best-$K$ identification problem (Best-$K$-Arm), we are given $N$ stochastic bandit arms with unknown reward distributions. Our goal is to identify the $K$ arms with the largest means with high confidence, by drawing samples from the arms adaptively. This problem is motivated by various practical applications and has attracted considerable attention in the past decade. In this paper, we propose new practical algorithms for the Best-$K$-Arm problem, which have nearly optimal sample complexity bounds (matching the lower bound up to logarithmic factors) and outperform the state-of-the-art algorithms for the Best-$K$-Arm problem (even for $K=1$) in practice.