 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Structure-Wise Uncertainty for 3D Medical Image Segmentation
Nov 01, 2022



When applying a Deep Learning model to medical images, it is crucial to estimate the model uncertainty. Voxel-wise uncertainty is a useful visual marker for human experts and could be used to improve the model's voxel-wise output, such as segmentation. Moreover, uncertainty provides a solid foundation for out-of-distribution (OOD) detection, improving the model performance on the image-wise level. However, one of the frequent tasks in medical imaging is the segmentation of distinct, local structures such as tumors or lesions. Here, the structure-wise uncertainty allows more precise operations than image-wise and more semantic-aware than voxel-wise. The way to produce uncertainty for individual structures remains poorly explored. We propose a framework to measure the structure-wise uncertainty and evaluate the impact of OOD data on the model performance. Thus, we identify the best UE method to improve the segmentation quality. The proposed framework is tested on three datasets with the tumor segmentation task: LIDC-IDRI, LiTS, and a private one with multiple brain metastases cases.
Interpretable Vertebral Fracture Quantification via Anchor-Free Landmarks Localization
Apr 14, 2022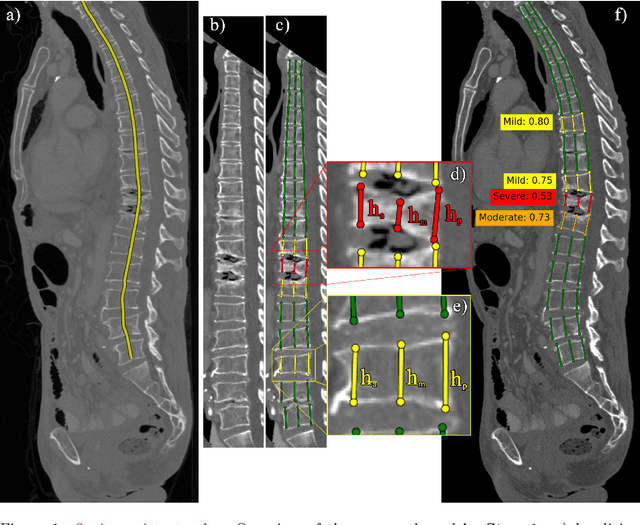
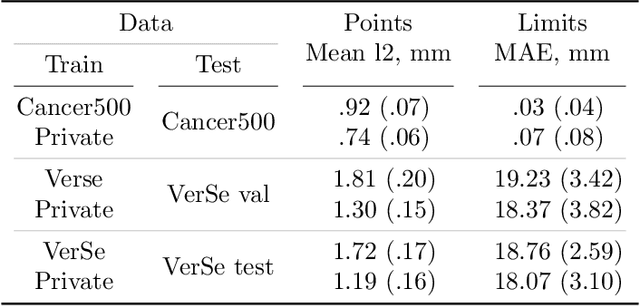
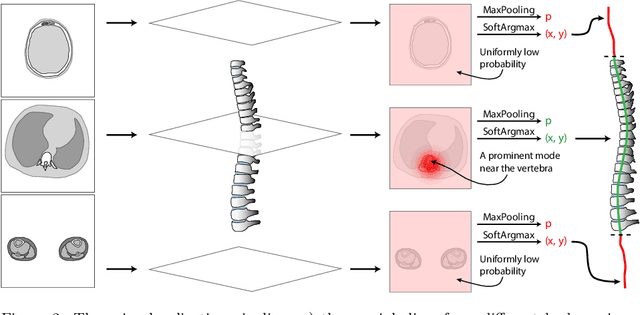
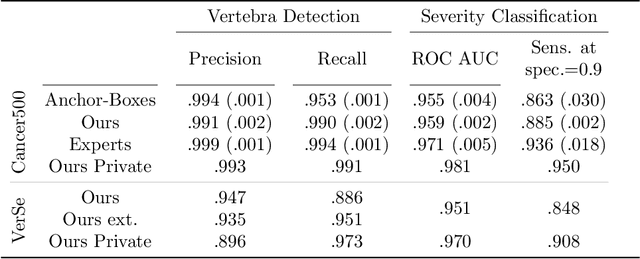
Vertebral body compression fractures are early signs of osteoporosis. Though these fractures are visible on Computed Tomography (CT) images, they are frequently missed by radiologists in clinical settings. Prior research on automatic methods of vertebral fracture classification proves its reliable quality; however, existing methods provide hard-to-interpret outputs and sometimes fail to process cases with severe abnormalities such as highly pathological vertebrae or scoliosis. We propose a new two-step algorithm to localize the vertebral column in 3D CT images and then detect individual vertebrae and quantify fractures in 2D simultaneously. We train neural networks for both steps using a simple 6-keypoints based annotation scheme, which corresponds precisely to the current clinical recommendation. Our algorithm has no exclusion criteria, processes 3D CT in 2 seconds on a single GPU, and provides an interpretable and verifiable output. The method approaches expert-level performance and demonstrates state-of-the-art results in vertebrae 3D localization (the average error is 1 mm), vertebrae 2D detection (precision and recall are 0.99), and fracture identification (ROC AUC at the patient level is up to 0.96). Our anchor-free vertebra detection network shows excellent generalizability on a new domain by achieving ROC AUC 0.95, sensitivity 0.85, specificity 0.9 on a challenging VerSe dataset with many unseen vertebra types.
Neglectable effect of brain MRI data prepreprocessing for tumor segmentation
Apr 11, 2022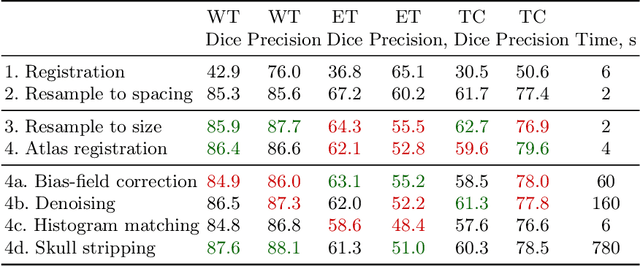
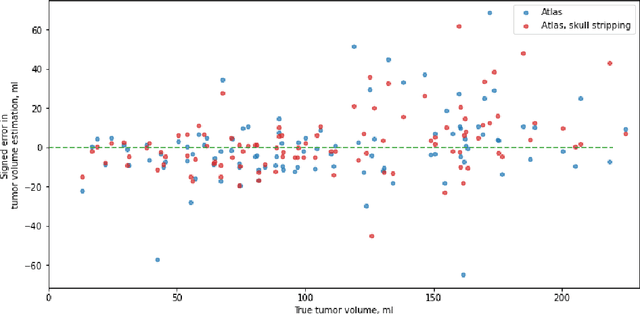

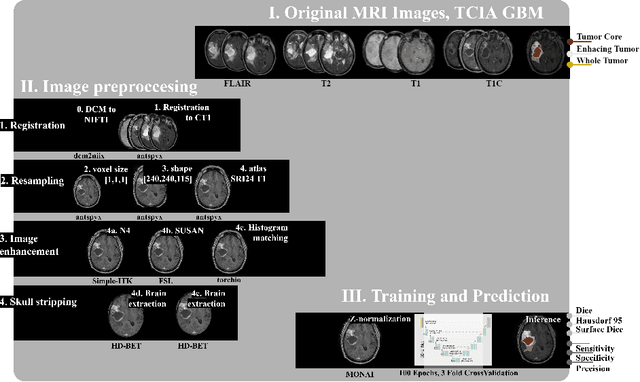
Magnetic resonance imaging (MRI) data is heterogeneous due to the differences in device manufacturers, scanning protocols, and inter-subject variability. A conventional way to mitigate MR image heterogeneity is to apply preprocessing transformations, such as anatomy alignment, voxel resampling, signal intensity equalization, image denoising, and localization of regions of interest (ROI). Although preprocessing pipeline standardizes image appearance, its influence on the quality of image segmentation and other downstream tasks on deep neural networks (DNN) has never been rigorously studied. Here we report a comprehensive study of multimodal MRI brain cancer image segmentation on TCIA-GBM open-source dataset. Our results demonstrate that most popular standardization steps add no value to artificial neural network performance; moreover, preprocessing can hamper model performance. We suggest that image intensity normalization approaches do not contribute to model accuracy because of the reduction of signal variance with image standardization. Finally, we show the contribution of scull-stripping in data preprocessing is almost negligible if measured in terms of clinically relevant metrics. We show that the only essential transformation for accurate analysis is the unification of voxel spacing across the dataset. In contrast, anatomy alignment in form of non-rigid atlas registration is not necessary and most intensity equalization steps do not improve model productiveness.
Adaptation to CT Reconstruction Kernels by Enforcing Cross-domain Feature Maps Consistency
Mar 28, 2022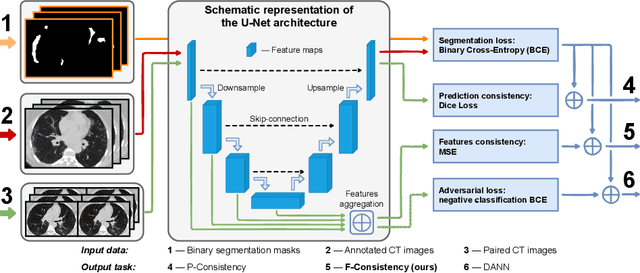
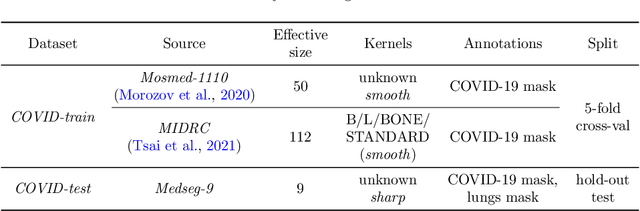


Deep learning methods provide significant assistance in analyzing coronavirus disease (COVID-19) in chest computed tomography (CT) images, including identification, severity assessment, and segmentation. Although the earlier developed methods address the lack of data and specific annotations, the current goal is to build a robust algorithm for clinical use, having a larger pool of available data. With the larger datasets, the domain shift problem arises, affecting the performance of methods on the unseen data. One of the critical sources of domain shift in CT images is the difference in reconstruction kernels used to generate images from the raw data (sinograms). In this paper, we show a decrease in the COVID-19 segmentation quality of the model trained on the smooth and tested on the sharp reconstruction kernels. Furthermore, we compare several domain adaptation approaches to tackle the problem, such as task-specific augmentation and unsupervised adversarial learning. Finally, we propose the unsupervised adaptation method, called F-Consistency, that outperforms the previous approaches. Our method exploits a set of unlabeled CT image pairs which differ only in reconstruction kernels within every pair. It enforces the similarity of the network hidden representations (feature maps) by minimizing mean squared error (MSE) between paired feature maps. We show our method achieving 0.64 Dice Score on the test dataset with unseen sharp kernels, compared to the 0.56 Dice Score of the baseline model. Moreover, F-Consistency scores 0.80 Dice Score between predictions on the paired images, which almost doubles the baseline score of 0.46 and surpasses the other methods. We also show F-Consistency to better generalize on the unseen kernels and without the specific semantic content, e.g., presence of the COVID-19 lesions.
Systematic Clinical Evaluation of A Deep Learning Method for Medical Image Segmentation: Radiosurgery Application
Aug 21, 2021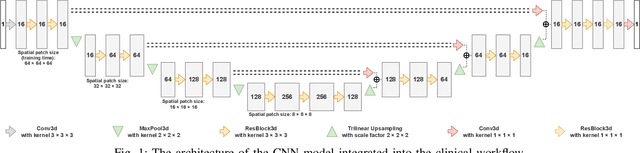
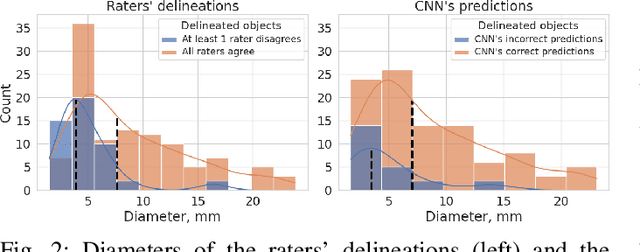
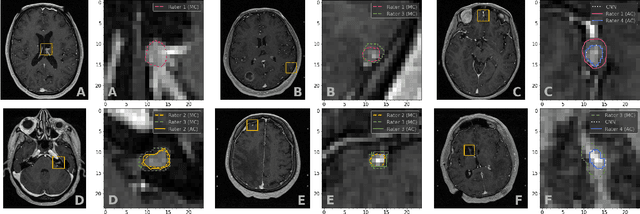
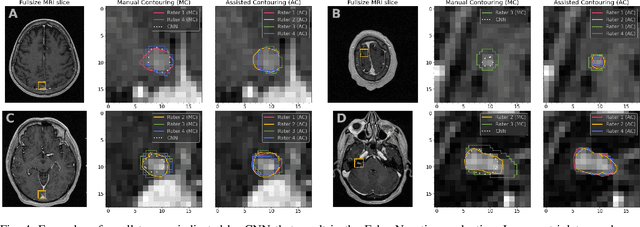
We systematically evaluate a Deep Learning (DL) method in a 3D medical image segmentation task. Our segmentation method is integrated into the radiosurgery treatment process and directly impacts the clinical workflow. With our method, we address the relative drawbacks of manual segmentation: high inter-rater contouring variability and high time consumption of the contouring process. The main extension over the existing evaluations is the careful and detailed analysis that could be further generalized on other medical image segmentation tasks. Firstly, we analyze the changes in the inter-rater detection agreement. We show that the segmentation model reduces the ratio of detection disagreements from 0.162 to 0.085 (p < 0.05). Secondly, we show that the model improves the inter-rater contouring agreement from 0.845 to 0.871 surface Dice Score (p < 0.05). Thirdly, we show that the model accelerates the delineation process in between 1.6 and 2.0 times (p < 0.05). Finally, we design the setup of the clinical experiment to either exclude or estimate the evaluation biases, thus preserve the significance of the results. Besides the clinical evaluation, we also summarize the intuitions and practical ideas for building an efficient DL-based model for 3D medical image segmentation.
Zero-Shot Domain Adaptation in CT Segmentation by Filtered Back Projection Augmentation
Aug 03, 2021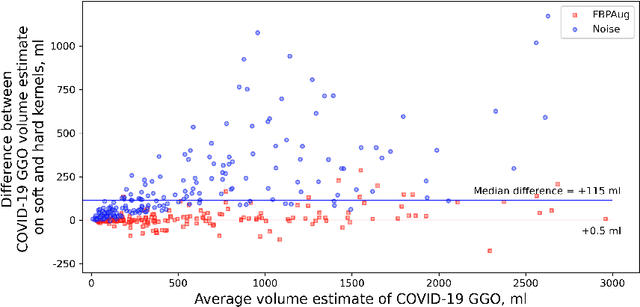


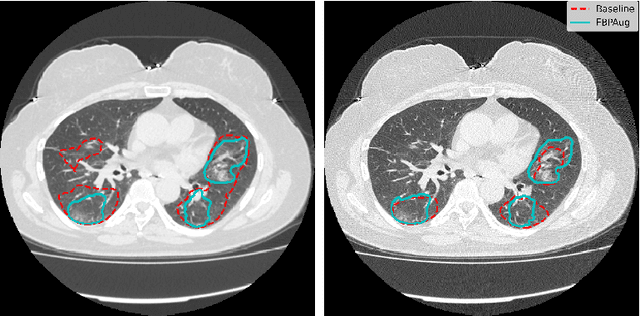
Domain shift is one of the most salient challenges in medical computer vision. Due to immense variability in scanners' parameters and imaging protocols, even images obtained from the same person and the same scanner could differ significantly. We address variability in computed tomography (CT) images caused by different convolution kernels used in the reconstruction process, the critical domain shift factor in CT. The choice of a convolution kernel affects pixels' granularity, image smoothness, and noise level. We analyze a dataset of paired CT images, where smooth and sharp images were reconstructed from the same sinograms with different kernels, thus providing identical anatomy but different style. Though identical predictions are desired, we show that the consistency, measured as the average Dice between predictions on pairs, is just 0.54. We propose Filtered Back-Projection Augmentation (FBPAug), a simple and surprisingly efficient approach to augment CT images in sinogram space emulating reconstruction with different kernels. We apply the proposed method in a zero-shot domain adaptation setup and show that the consistency boosts from 0.54 to 0.92 outperforming other augmentation approaches. Neither specific preparation of source domain data nor target domain data is required, so our publicly released FBPAug can be used as a plug-and-play module for zero-shot domain adaptation in any CT-based task.
Anatomy of Domain Shift Impact on U-Net Layers in MRI Segmentation
Jul 10, 2021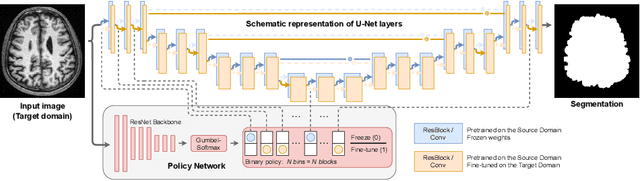
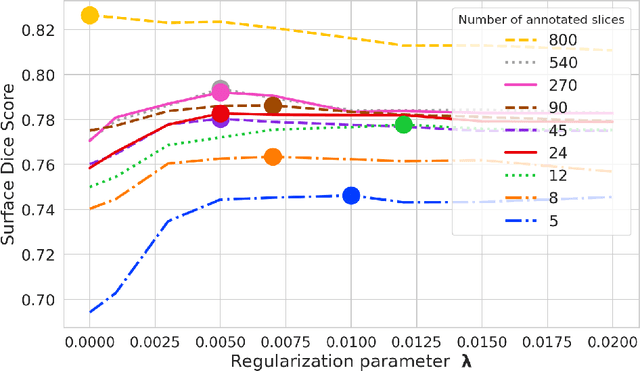
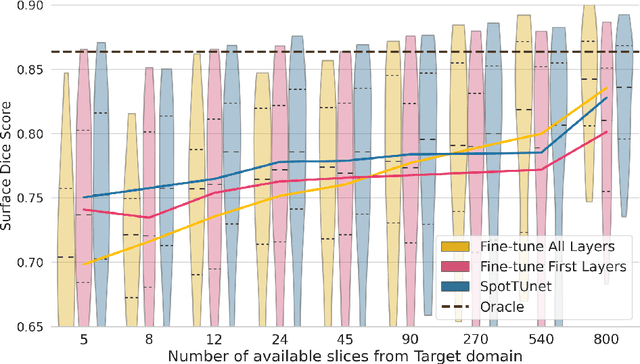
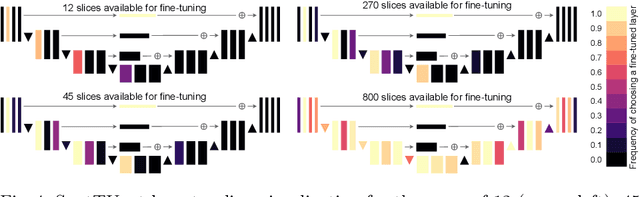
Domain Adaptation (DA) methods are widely used in medical image segmentation tasks to tackle the problem of differently distributed train (source) and test (target) data. We consider the supervised DA task with a limited number of annotated samples from the target domain. It corresponds to one of the most relevant clinical setups: building a sufficiently accurate model on the minimum possible amount of annotated data. Existing methods mostly fine-tune specific layers of the pretrained Convolutional Neural Network (CNN). However, there is no consensus on which layers are better to fine-tune, e.g. the first layers for images with low-level domain shift or the deeper layers for images with high-level domain shift. To this end, we propose SpotTUnet - a CNN architecture that automatically chooses the layers which should be optimally fine-tuned. More specifically, on the target domain, our method additionally learns the policy that indicates whether a specific layer should be fine-tuned or reused from the pretrained network. We show that our method performs at the same level as the best of the nonflexible fine-tuning methods even under the extreme scarcity of annotated data. Secondly, we show that SpotTUnet policy provides a layer-wise visualization of the domain shift impact on the network, which could be further used to develop robust domain generalization methods. In order to extensively evaluate SpotTUnet performance, we use a publicly available dataset of brain MR images (CC359), characterized by explicit domain shift. We release a reproducible experimental pipeline.
First U-Net Layers Contain More Domain Specific Information Than The Last Ones
Aug 17, 2020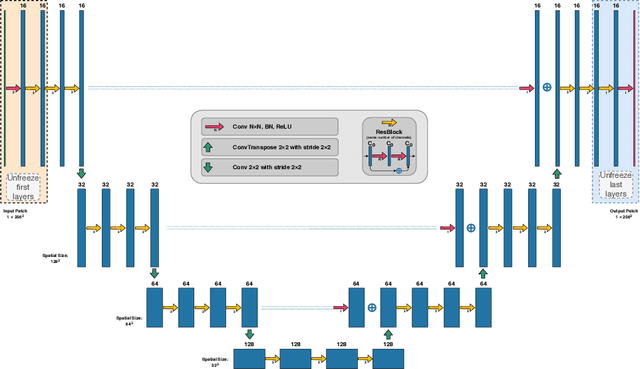
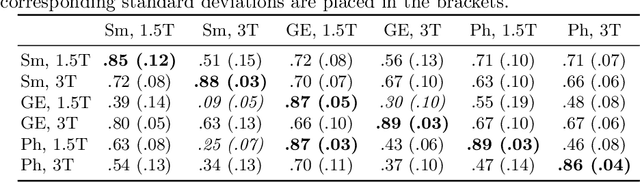
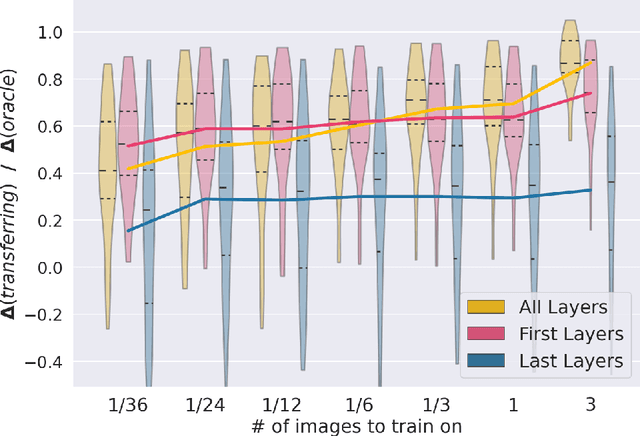
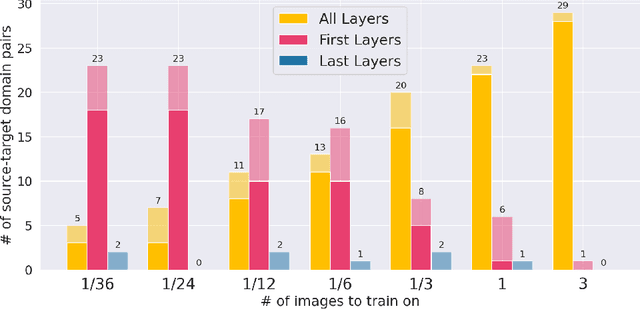
MRI scans appearance significantly depends on scanning protocols and, consequently, the data-collection institution. These variations between clinical sites result in dramatic drops of CNN segmentation quality on unseen domains. Many of the recently proposed MRI domain adaptation methods operate with the last CNN layers to suppress domain shift. At the same time, the core manifestation of MRI variability is a considerable diversity of image intensities. We hypothesize that these differences can be eliminated by modifying the first layers rather than the last ones. To validate this simple idea, we conducted a set of experiments with brain MRI scans from six domains. Our results demonstrate that 1) domain-shift may deteriorate the quality even for a simple brain extraction segmentation task (surface Dice Score drops from 0.85-0.89 even to 0.09); 2) fine-tuning of the first layers significantly outperforms fine-tuning of the last layers in almost all supervised domain adaptation setups. Moreover, fine-tuning of the first layers is a better strategy than fine-tuning of the whole network, if the amount of annotated data from the new domain is strictly limited.
Universal Loss Reweighting to Balance Lesion Size Inequality in 3D Medical Image Segmentation
Jul 20, 2020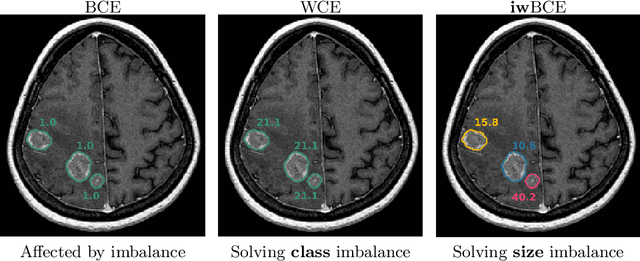

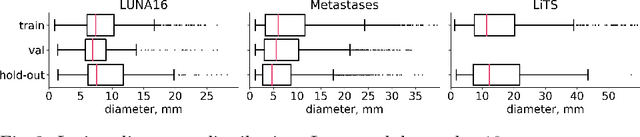
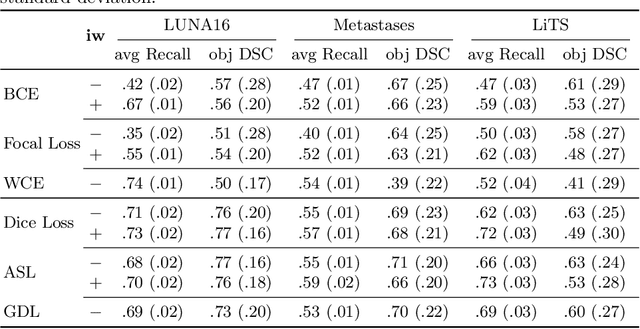
Target imbalance affects the performance of recent deep learning methods in many medical image segmentation tasks. It is a twofold problem: class imbalance - positive class (lesion) size compared to negative class (non-lesion) size; lesion size imbalance - large lesions overshadows small ones (in the case of multiple lesions per image). While the former was addressed in multiple works, the latter lacks investigation. We propose a loss reweighting approach to increase the ability of the network to detect small lesions. During the learning process, we assign a weight to every image voxel. The assigned weights are inversely proportional to the lesion volume, thus smaller lesions get larger weights. We report the benefit from our method for well-known loss functions, including Dice Loss, Focal Loss, and Asymmetric Similarity Loss. Additionally, we compare our results with other reweighting techniques: Weighted Cross-Entropy and Generalized Dice Loss. Our experiments show that inverse weighting considerably increases the detection quality, while preserves the delineation quality on a state-of-the-art level. We publish a complete experimental pipeline for two publicly available datasets of CT images: LiTS and LUNA16 (https://github.com/neuro-ml/inverse_weighting). We also show results on a private database of MR images for the task of multiple brain metastases delineation.
CT-based COVID-19 Triage: Deep Multitask Learning Improves Joint Identification and Severity Quantification
Jun 02, 2020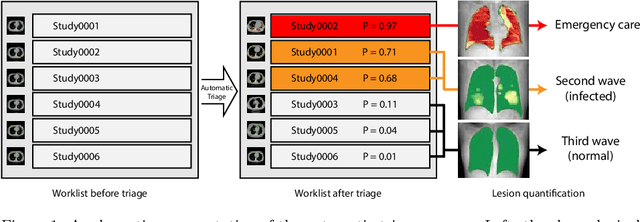
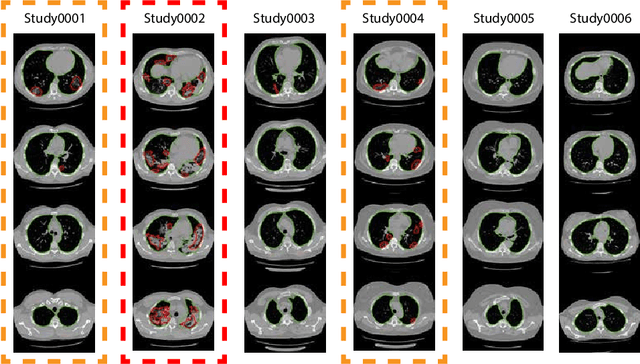
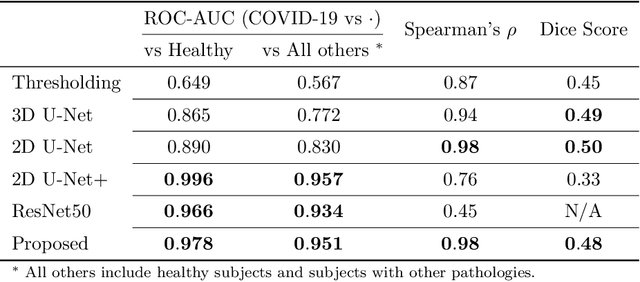
The current COVID-19 pandemic overloads healthcare systems, including radiology departments. Though several deep learning approaches were developed to assist in CT analysis, nobody considered study triage directly as a computer science problem. We describe two basic setups: Identification of COVID-19 to prioritize studies of potentially infected patients to isolate them as early as possible; Severity quantification to highlight studies of severe patients and direct them to a hospital or provide emergency medical care. We formalize these tasks as binary classification and estimation of affected lung percentage. Though similar problems were well-studied separately, we show that existing methods provide reasonable quality only for one of these setups. To consolidate both triage approaches, we employ a multitask learning and propose a convolutional neural network to combine all available labels within a single model. We train our model on approximately 2000 publicly available CT studies and test it with a carefully designed set consisting of 33 COVID patients, 32 healthy patients, and 36 patients with other lung pathologies to emulate a typical patient flow in an out-patient hospital. The developed model achieved 0.951 ROC AUC for Identification of COVID-19 and 0.98 Spearman Correlation for Severity quantification. We release all the code and create a public leaderboard, where other community members can test their models on our dataset.