 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Search of Insights, Not Magic Bullets: Towards Demystification of the Model Selection Dilemma in Heterogeneous Treatment Effect Estimation
Feb 06, 2023



Personalized treatment effect estimates are often of interest in high-stakes applications -- thus, before deploying a model estimating such effects in practice, one needs to be sure that the best candidate from the ever-growing machine learning toolbox for this task was chosen. Unfortunately, due to the absence of counterfactual information in practice, it is usually not possible to rely on standard validation metrics for doing so, leading to a well-known model selection dilemma in the treatment effect estimation literature. While some solutions have recently been investigated, systematic understanding of the strengths and weaknesses of different model selection criteria is still lacking. In this paper, instead of attempting to declare a global `winner', we therefore empirically investigate success- and failure modes of different selection criteria. We highlight that there is a complex interplay between selection strategies, candidate estimators and the DGP used for testing, and provide interesting insights into the relative (dis)advantages of different criteria alongside desiderata for the design of further illuminating empirical studies in this context.
TemporAI: Facilitating Machine Learning Innovation in Time Domain Tasks for Medicine
Jan 28, 2023TemporAI is an open source Python software library for machine learning (ML) tasks involving data with a time component, focused on medicine and healthcare use cases. It supports data in time series, static, and eventmodalities and provides an interface for prediction, causal inference, and time-to-event analysis, as well as common preprocessing utilities and model interpretability methods. The library aims to facilitate innovation in the medical ML space by offering a standardized temporal setting toolkit for model development, prototyping and benchmarking, bridging the gaps in the ML research, healthcare professional, medical/pharmacological industry, and data science communities. TemporAI is available on GitHub (https://github.com/vanderschaarlab/temporai) and we welcome community engagement through use, feedback, and code contributions.
Joint Training of Deep Ensembles Fails Due to Learner Collusion
Jan 26, 2023Ensembles of machine learning models have been well established as a powerful method of improving performance over a single model. Traditionally, ensembling algorithms train their base learners independently or sequentially with the goal of optimizing their joint performance. In the case of deep ensembles of neural networks, we are provided with the opportunity to directly optimize the true objective: the joint performance of the ensemble as a whole. Surprisingly, however, directly minimizing the loss of the ensemble appears to rarely be applied in practice. Instead, most previous research trains individual models independently with ensembling performed post hoc. In this work, we show that this is for good reason - joint optimization of ensemble loss results in degenerate behavior. We approach this problem by decomposing the ensemble objective into the strength of the base learners and the diversity between them. We discover that joint optimization results in a phenomenon in which base learners collude to artificially inflate their apparent diversity. This pseudo-diversity fails to generalize beyond the training data, causing a larger generalization gap. We proceed to demonstrate the practical implications of this effect finding that, in some cases, a balance between independent training and joint optimization can improve performance over the former while avoiding the degeneracies of the latter.
Synthcity: facilitating innovative use cases of synthetic data in different data modalities
Jan 18, 2023



Synthcity is an open-source software package for innovative use cases of synthetic data in ML fairness, privacy and augmentation across diverse tabular data modalities, including static data, regular and irregular time series, data with censoring, multi-source data, composite data, and more. Synthcity provides the practitioners with a single access point to cutting edge research and tools in synthetic data. It also offers the community a playground for rapid experimentation and prototyping, a one-stop-shop for SOTA benchmarks, and an opportunity for extending research impact. The library can be accessed on GitHub (https://github.com/vanderschaarlab/synthcity) and pip (https://pypi.org/project/synthcity/). We warmly invite the community to join the development effort by providing feedback, reporting bugs, and contributing code.
Navigating causal deep learning
Dec 01, 2022



Causal deep learning (CDL) is a new and important research area in the larger field of machine learning. With CDL, researchers aim to structure and encode causal knowledge in the extremely flexible representation space of deep learning models. Doing so will lead to more informed, robust, and general predictions and inference -- which is important! However, CDL is still in its infancy. For example, it is not clear how we ought to compare different methods as they are so different in their output, the way they encode causal knowledge, or even how they represent this knowledge. This is a living paper that categorises methods in causal deep learning beyond Pearl's ladder of causation. We refine the rungs in Pearl's ladder, while also adding a separate dimension that categorises the parametric assumptions of both input and representation, arriving at the map of causal deep learning. Our map covers machine learning disciplines such as supervised learning, reinforcement learning, generative modelling and beyond. Our paradigm is a tool which helps researchers to: find benchmarks, compare methods, and most importantly: identify research gaps. With this work we aim to structure the avalanche of papers being published on causal deep learning. While papers on the topic are being published daily, our map remains fixed. We open-source our map for others to use as they see fit: perhaps to offer guidance in a related works section, or to better highlight the contribution of their paper.
Practical Approaches for Fair Learning with Multitype and Multivariate Sensitive Attributes
Nov 11, 2022



It is important to guarantee that machine learning algorithms deployed in the real world do not result in unfairness or unintended social consequences. Fair ML has largely focused on the protection of single attributes in the simpler setting where both attributes and target outcomes are binary. However, the practical application in many a real-world problem entails the simultaneous protection of multiple sensitive attributes, which are often not simply binary, but continuous or categorical. To address this more challenging task, we introduce FairCOCCO, a fairness measure built on cross-covariance operators on reproducing kernel Hilbert Spaces. This leads to two practical tools: first, the FairCOCCO Score, a normalised metric that can quantify fairness in settings with single or multiple sensitive attributes of arbitrary type; and second, a subsequent regularisation term that can be incorporated into arbitrary learning objectives to obtain fair predictors. These contributions address crucial gaps in the algorithmic fairness literature, and we empirically demonstrate consistent improvements against state-of-the-art techniques in balancing predictive power and fairness on real-world datasets.
DC-Check: A Data-Centric AI checklist to guide the development of reliable machine learning systems
Nov 09, 2022While there have been a number of remarkable breakthroughs in machine learning (ML), much of the focus has been placed on model development. However, to truly realize the potential of machine learning in real-world settings, additional aspects must be considered across the ML pipeline. Data-centric AI is emerging as a unifying paradigm that could enable such reliable end-to-end pipelines. However, this remains a nascent area with no standardized framework to guide practitioners to the necessary data-centric considerations or to communicate the design of data-centric driven ML systems. To address this gap, we propose DC-Check, an actionable checklist-style framework to elicit data-centric considerations at different stages of the ML pipeline: Data, Training, Testing, and Deployment. This data-centric lens on development aims to promote thoughtfulness and transparency prior to system development. Additionally, we highlight specific data-centric AI challenges and research opportunities. DC-Check is aimed at both practitioners and researchers to guide day-to-day development. As such, to easily engage with and use DC-Check and associated resources, we provide a DC-Check companion website (https://www.vanderschaar-lab.com/dc-check/). The website will also serve as an updated resource as methods and tooling evolve over time.
Composite Feature Selection using Deep Ensembles
Nov 01, 2022



In many real world problems, features do not act alone but in combination with each other. For example, in genomics, diseases might not be caused by any single mutation but require the presence of multiple mutations. Prior work on feature selection either seeks to identify individual features or can only determine relevant groups from a predefined set. We investigate the problem of discovering groups of predictive features without predefined grouping. To do so, we define predictive groups in terms of linear and non-linear interactions between features. We introduce a novel deep learning architecture that uses an ensemble of feature selection models to find predictive groups, without requiring candidate groups to be provided. The selected groups are sparse and exhibit minimum overlap. Furthermore, we propose a new metric to measure similarity between discovered groups and the ground truth. We demonstrate the utility of our model on multiple synthetic tasks and semi-synthetic chemistry datasets, where the ground truth structure is known, as well as an image dataset and a real-world cancer dataset.
Data-IQ: Characterizing subgroups with heterogeneous outcomes in tabular data
Oct 24, 2022High model performance, on average, can hide that models may systematically underperform on subgroups of the data. We consider the tabular setting, which surfaces the unique issue of outcome heterogeneity - this is prevalent in areas such as healthcare, where patients with similar features can have different outcomes, thus making reliable predictions challenging. To tackle this, we propose Data-IQ, a framework to systematically stratify examples into subgroups with respect to their outcomes. We do this by analyzing the behavior of individual examples during training, based on their predictive confidence and, importantly, the aleatoric (data) uncertainty. Capturing the aleatoric uncertainty permits a principled characterization and then subsequent stratification of data examples into three distinct subgroups (Easy, Ambiguous, Hard). We experimentally demonstrate the benefits of Data-IQ on four real-world medical datasets. We show that Data-IQ's characterization of examples is most robust to variation across similarly performant (yet different) models, compared to baselines. Since Data-IQ can be used with any ML model (including neural networks, gradient boosting etc.), this property ensures consistency of data characterization, while allowing flexible model selection. Taking this a step further, we demonstrate that the subgroups enable us to construct new approaches to both feature acquisition and dataset selection. Furthermore, we highlight how the subgroups can inform reliable model usage, noting the significant impact of the Ambiguous subgroup on model generalization.
Synthetic Model Combination: An Instance-wise Approach to Unsupervised Ensemble Learning
Oct 11, 2022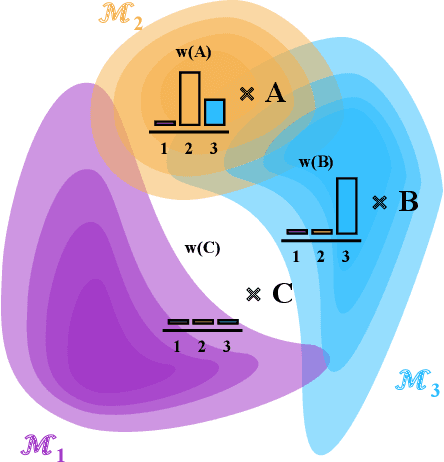

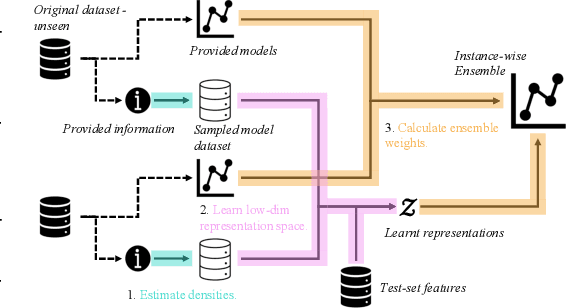
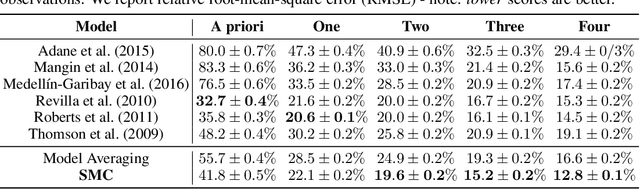
Consider making a prediction over new test data without any opportunity to learn from a training set of labelled data - instead given access to a set of expert models and their predictions alongside some limited information about the dataset used to train them. In scenarios from finance to the medical sciences, and even consumer practice, stakeholders have developed models on private data they either cannot, or do not want to, share. Given the value and legislation surrounding personal information, it is not surprising that only the models, and not the data, will be released - the pertinent question becoming: how best to use these models? Previous work has focused on global model selection or ensembling, with the result of a single final model across the feature space. Machine learning models perform notoriously poorly on data outside their training domain however, and so we argue that when ensembling models the weightings for individual instances must reflect their respective domains - in other words models that are more likely to have seen information on that instance should have more attention paid to them. We introduce a method for such an instance-wise ensembling of models, including a novel representation learning step for handling sparse high-dimensional domains. Finally, we demonstrate the need and generalisability of our method on classical machine learning tasks as well as highlighting a real world use case in the pharmacological setting of vancomycin precision dosing.