 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Action Recognition for Smart Hospitals using Low-Resolution Depth Images
Nov 25, 2018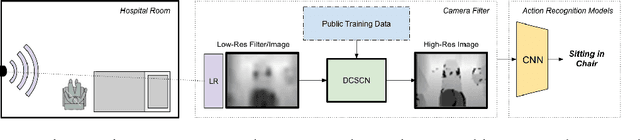
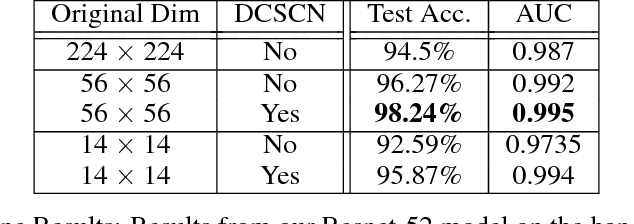

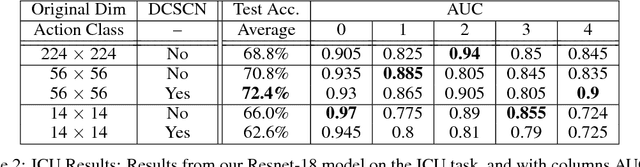
Computer-vision hospital systems can greatly assist healthcare workers and improve medical facility treatment, but often face patient resistance due to the perceived intrusiveness and violation of privacy associated with visual surveillance. We downsample video frames to extremely low resolutions to degrade private information from surveillance videos. We measure the amount of activity-recognition information retained in low resolution depth images, and also apply a privately-trained DCSCN super-resolution model to enhance the utility of our images. We implement our techniques with two actual healthcare-surveillance scenarios, hand-hygiene compliance and ICU activity-logging, and show that our privacy-preserving techniques preserve enough information for realistic healthcare tasks.
Conditional End-to-End Audio Transforms
Jun 07, 2018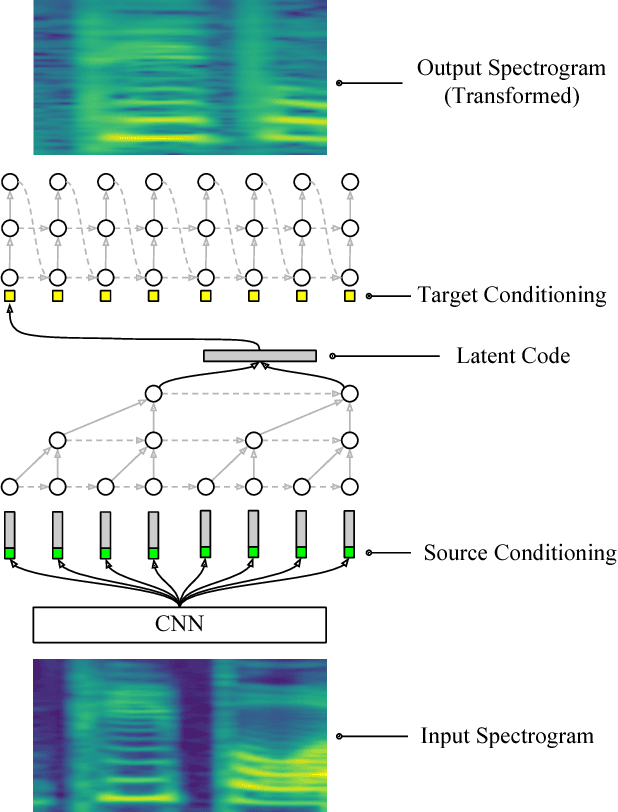
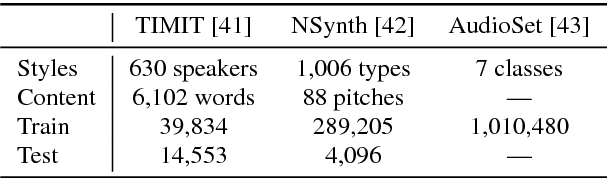
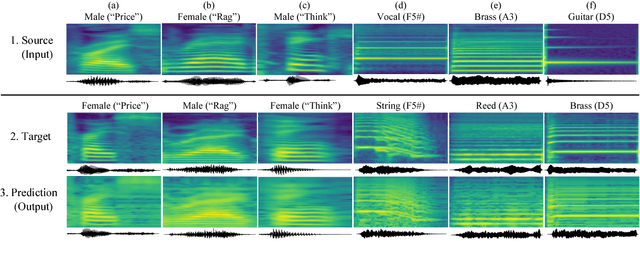
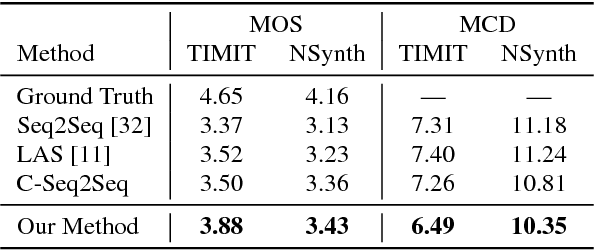
We present an end-to-end method for transforming audio from one style to another. For the case of speech, by conditioning on speaker identities, we can train a single model to transform words spoken by multiple people into multiple target voices. For the case of music, we can specify musical instruments and achieve the same result. Architecturally, our method is a fully-differentiable sequence-to-sequence model based on convolutional and hierarchical recurrent neural networks. It is designed to capture long-term acoustic dependencies, requires minimal post-processing, and produces realistic audio transforms. Ablation studies confirm that our model can separate speaker and instrument properties from acoustic content at different receptive fields. Empirically, our method achieves competitive performance on community-standard datasets.
Towards Vision-Based Smart Hospitals: A System for Tracking and Monitoring Hand Hygiene Compliance
Apr 24, 2018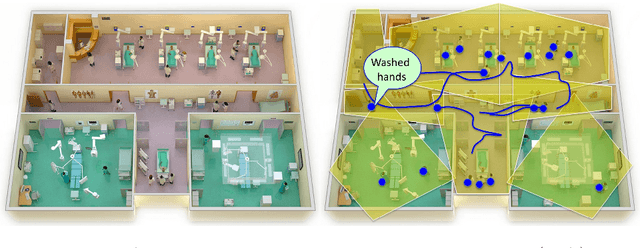
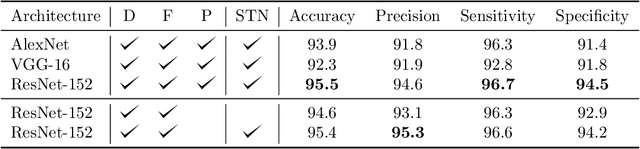

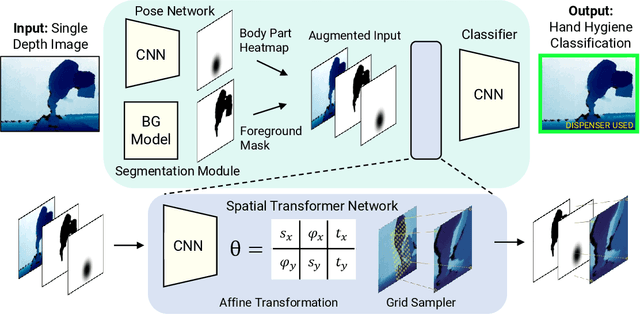
One in twenty-five patients admitted to a hospital will suffer from a hospital acquired infection. If we can intelligently track healthcare staff, patients, and visitors, we can better understand the sources of such infections. We envision a smart hospital capable of increasing operational efficiency and improving patient care with less spending. In this paper, we propose a non-intrusive vision-based system for tracking people's activity in hospitals. We evaluate our method for the problem of measuring hand hygiene compliance. Empirically, our method outperforms existing solutions such as proximity-based techniques and covert in-person observational studies. We present intuitive, qualitative results that analyze human movement patterns and conduct spatial analytics which convey our method's interpretability. This work is a step towards a computer-vision based smart hospital and demonstrates promising results for reducing hospital acquired infections.
* Machine Learning for Healthcare Conference (MLHC)
Knowledge Distillation for Small-footprint Highway Networks
Dec 20, 2016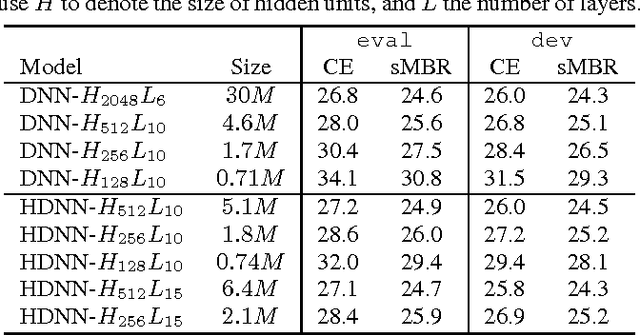
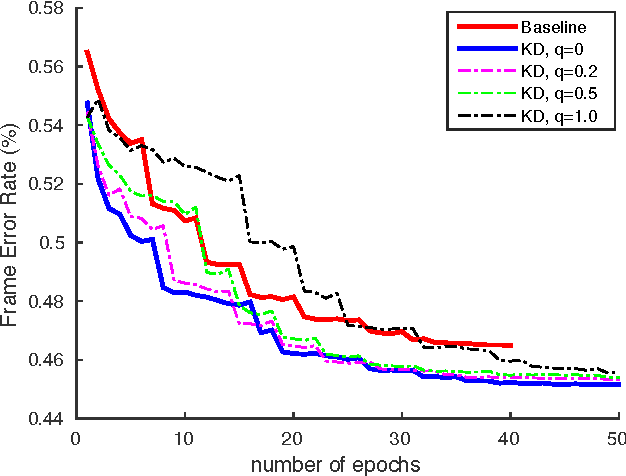
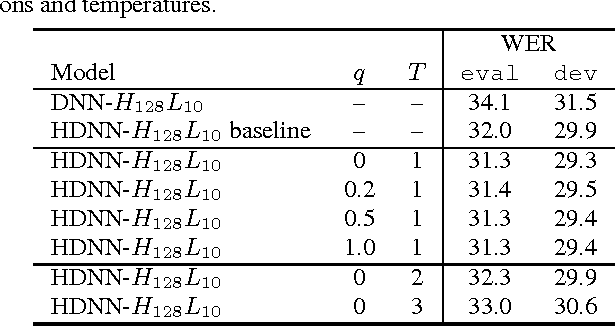
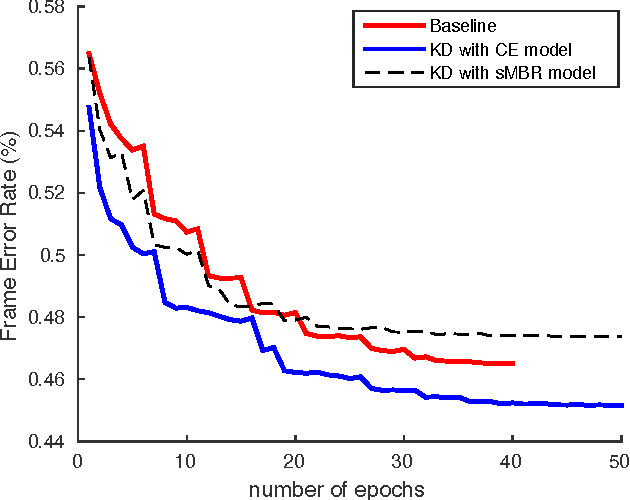
Deep learning has significantly advanced state-of-the-art of speech recognition in the past few years. However, compared to conventional Gaussian mixture acoustic models, neural network models are usually much larger, and are therefore not very deployable in embedded devices. Previously, we investigated a compact highway deep neural network (HDNN) for acoustic modelling, which is a type of depth-gated feedforward neural network. We have shown that HDNN-based acoustic models can achieve comparable recognition accuracy with much smaller number of model parameters compared to plain deep neural network (DNN) acoustic models. In this paper, we push the boundary further by leveraging on the knowledge distillation technique that is also known as {\it teacher-student} training, i.e., we train the compact HDNN model with the supervision of a high accuracy cumbersome model. Furthermore, we also investigate sequence training and adaptation in the context of teacher-student training. Our experiments were performed on the AMI meeting speech recognition corpus. With this technique, we significantly improved the recognition accuracy of the HDNN acoustic model with less than 0.8 million parameters, and narrowed the gap between this model and the plain DNN with 30 million parameters.