 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Disparate Impact for Configurable Fairness Solutions in ML
May 29, 2023



We make two contributions in the field of AI fairness over continuous protected attributes. First, we show that the Hirschfeld-Gebelein-Renyi (HGR) indicator (the only one currently available for such a case) is valuable but subject to a few crucial limitations regarding semantics, interpretability, and robustness. Second, we introduce a family of indicators that are: 1) complementary to HGR in terms of semantics; 2) fully interpretable and transparent; 3) robust over finite samples; 4) configurable to suit specific applications. Our approach also allows us to define fine-grained constraints to permit certain types of dependence and forbid others selectively. By expanding the available options for continuous protected attributes, our approach represents a significant contribution to the area of fair artificial intelligence.
UNIFY: a Unified Policy Designing Framework for Solving Constrained Optimization Problems with Machine Learning
Oct 25, 2022



The interplay between Machine Learning (ML) and Constrained Optimization (CO) has recently been the subject of increasing interest, leading to a new and prolific research area covering (e.g.) Decision Focused Learning and Constrained Reinforcement Learning. Such approaches strive to tackle complex decision problems under uncertainty over multiple stages, involving both explicit (cost function, constraints) and implicit knowledge (from data), and possibly subject to execution time restrictions. While a good degree of success has been achieved, the existing methods still have limitations in terms of both applicability and effectiveness. For problems in this class, we propose UNIFY, a unified framework to design a solution policy for complex decision-making problems. Our approach relies on a clever decomposition of the policy in two stages, namely an unconstrained ML model and a CO problem, to take advantage of the strength of each approach while compensating for its weaknesses. With a little design effort, UNIFY can generalize several existing approaches, thus extending their applicability. We demonstrate the method effectiveness on two practical problems, namely an Energy Management System and the Set Multi-cover with stochastic coverage requirements. Finally, we highlight some current challenges of our method and future research directions that can benefit from the cross-fertilization of the two fields.
Machine Learning for Combinatorial Optimisation of Partially-Specified Problems: Regret Minimisation as a Unifying Lens
May 20, 2022

It is increasingly common to solve combinatorial optimisation problems that are partially-specified. We survey the case where the objective function or the relations between variables are not known or are only partially specified. The challenge is to learn them from available data, while taking into account a set of hard constraints that a solution must satisfy, and that solving the optimisation problem (esp. during learning) is computationally very demanding. This paper overviews four seemingly unrelated approaches, that can each be viewed as learning the objective function of a hard combinatorial optimisation problem: 1) surrogate-based optimisation, 2) empirical model learning, 3) decision-focused learning (`predict + optimise'), and 4) structured-output prediction. We formalise each learning paradigm, at first in the ways commonly found in the literature, and then bring the formalisations together in a compatible way using regret. We discuss the differences and interactions between these frameworks, highlight the opportunities for cross-fertilization and survey open directions.
Deep Learning for Virus-Spreading Forecasting: a Brief Survey
Mar 03, 2021
The advent of the coronavirus pandemic has sparked the interest in predictive models capable of forecasting virus-spreading, especially for boosting and supporting decision-making processes. In this paper, we will outline the main Deep Learning approaches aimed at predicting the spreading of a disease in space and time. The aim is to show the emerging trends in this area of research and provide a general perspective on the possible strategies to approach this problem. In doing so, we will mainly focus on two macro-categories: classical Deep Learning approaches and Hybrid models. Finally, we will discuss the main advantages and disadvantages of different models, and underline the most promising development directions to improve these approaches.
Discrete solution pools and noise-contrastive estimation for predict-and-optimize
Nov 10, 2020


Numerous real-life decision-making processes involve solving a combinatorial optimization problem with uncertain input that can be estimated from historic data. There is a growing interest in decision-focused learning methods, where the loss function used for learning to predict the uncertain input uses the outcome of solving the combinatorial problem over a set of predictions. Different surrogate loss functions have been identified, often using a continuous approximation of the combinatorial problem. However, a key bottleneck is that to compute the loss, one has to solve the combinatorial optimisation problem for each training instance in each epoch, which is computationally expensive even in the case of continuous approximations. We propose a different solver-agnostic method for decision-focused learning, namely by considering a pool of feasible solutions as a discrete approximation of the full combinatorial problem. Solving is now trivial through a single pass over the solution pool. We design several variants of a noise-contrastive loss over the solution pool, which we substantiate theoretically and empirically. Furthermore, we show that by dynamically re-solving only a fraction of the training instances each epoch, our method performs on par with the state of the art, whilst drastically reducing the time spent solving, hence increasing the feasibility of predict-and-optimize for larger problems.
An Analysis of Regularized Approaches for Constrained Machine Learning
May 20, 2020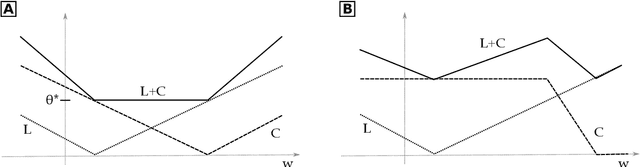
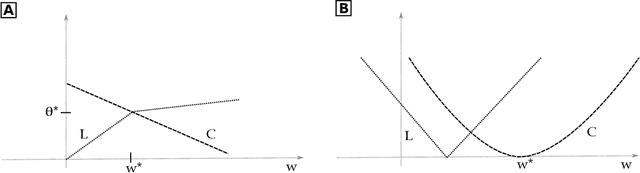
Regularization-based approaches for injecting constraints in Machine Learning (ML) were introduced to improve a predictive model via expert knowledge. We tackle the issue of finding the right balance between the loss (the accuracy of the learner) and the regularization term (the degree of constraint satisfaction). The key results of this paper is the formal demonstration that this type of approach cannot guarantee to find all optimal solutions. In particular, in the non-convex case there might be optima for the constrained problem that do not correspond to any multiplier value.
Teaching the Old Dog New Tricks: Supervised Learning with Constraints
Feb 25, 2020
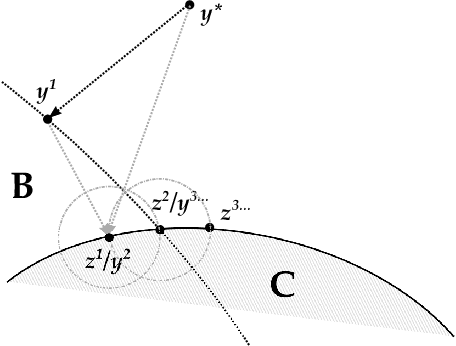
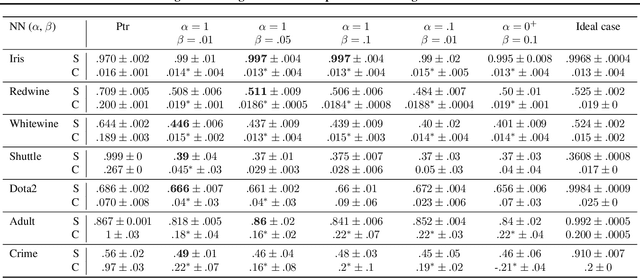
Methods for taking into account external knowledge in Machine Learning models have the potential to address outstanding issues in data-driven AI methods, such as improving safety and fairness, and can simplify training in the presence of scarce data. We propose a simple, but effective, method for injecting constraints at training time in supervised learning, based on decomposition and bi-level optimization: a master step is in charge of enforcing the constraints, while a learner step takes care of training the model. The process leads to approximate constraint satisfaction. The method is applicable to any ML approach for which the concept of label (or target) is well defined (most regression and classification scenarios), and allows to reuse existing training algorithms with no modifications. We require no assumption on the constraints, although their properties affect the shape and complexity of the master problem. Convergence guarantees are hard to provide, but we found that the approach performs well on ML tasks with fairness constraints and on classical datasets with synthetic constraints.
Injecting Domain Knowledge in Neural Networks: a Controlled Experiment on a Constrained Problem
Feb 25, 2020
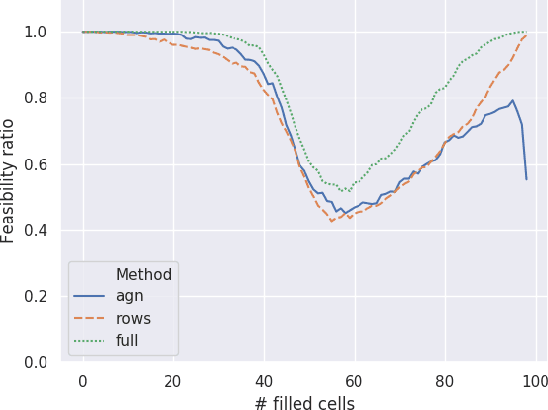
Given enough data, Deep Neural Networks (DNNs) are capable of learning complex input-output relations with high accuracy. In several domains, however, data is scarce or expensive to retrieve, while a substantial amount of expert knowledge is available. It seems reasonable that if we can inject this additional information in the DNN, we could ease the learning process. One such case is that of Constraint Problems, for which declarative approaches exists and pure ML solutions have obtained mixed success. Using a classical constrained problem as a case study, we perform controlled experiments to probe the impact of progressively adding domain and empirical knowledge in the DNN. Our results are very encouraging, showing that (at least in our setup) embedding domain knowledge at training time can have a considerable effect and that a small amount of empirical knowledge is sufficient to obtain practically useful results.
Injective Domain Knowledge in Neural Networks for Transprecision Computing
Feb 24, 2020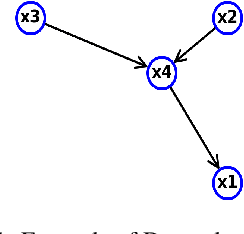
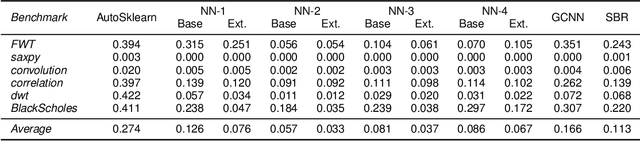

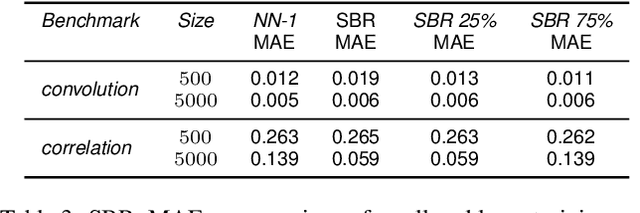
Machine Learning (ML) models are very effective in many learning tasks, due to the capability to extract meaningful information from large data sets. Nevertheless, there are learning problems that cannot be easily solved relying on pure data, e.g. scarce data or very complex functions to be approximated. Fortunately, in many contexts domain knowledge is explicitly available and can be used to train better ML models. This paper studies the improvements that can be obtained by integrating prior knowledge when dealing with a non-trivial learning task, namely precision tuning of transprecision computing applications. The domain information is injected in the ML models in different ways: I) additional features, II) ad-hoc graph-based network topology, III) regularization schemes. The results clearly show that ML models exploiting problem-specific information outperform the purely data-driven ones, with an average accuracy improvement around 38%.
A Lagrangian Dual Framework for Deep Neural Networks with Constraints
Jan 26, 2020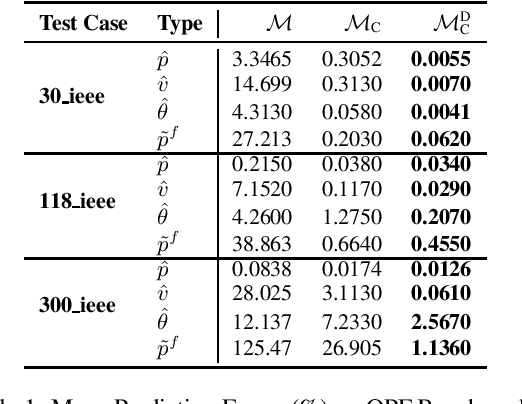
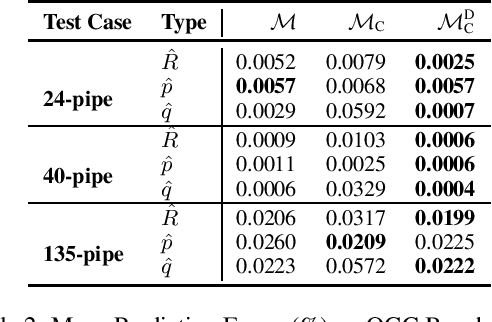
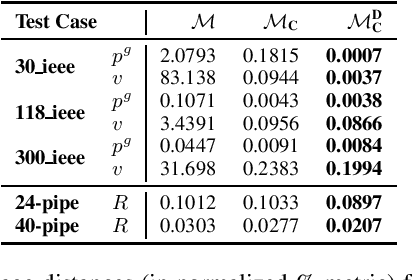
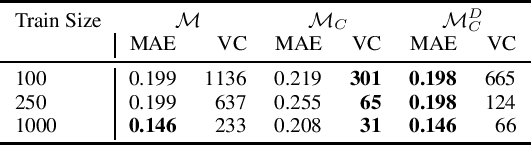
A variety of computationally challenging constrained optimization problems in several engineering disciplines are solved repeatedly under different scenarios. In many cases, they would benefit from fast and accurate approximations, either to support real-time operations or large-scale simulation studies. This paper aims at exploring how to leverage the substantial data being accumulated by repeatedly solving instances of these applications over time. It introduces a deep learning model that exploits Lagrangian duality to encourage the satisfaction of hard constraints. The proposed method is evaluated on a collection of realistic energy networks, by enforcing non-discriminatory decisions on a variety of datasets, and a transprecision computing application. The results illustrate the effectiveness of the proposed method that dramatically decreases constraint violations by the predictors and, in some applications, increases the prediction accuracy.