 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRUAD: unsupervised anomaly detection in HPC systems
Aug 28, 2022
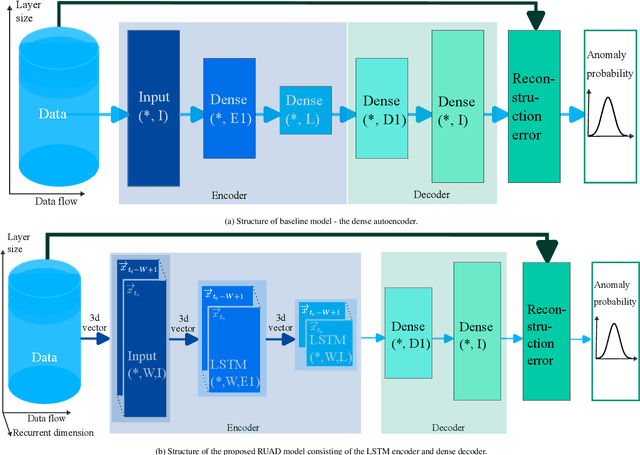


The increasing complexity of modern high-performance computing (HPC) systems necessitates the introduction of automated and data-driven methodologies to support system administrators' effort toward increasing the system's availability. Anomaly detection is an integral part of improving the availability as it eases the system administrator's burden and reduces the time between an anomaly and its resolution. However, current state-of-the-art (SoA) approaches to anomaly detection are supervised and semi-supervised, so they require a human-labelled dataset with anomalies - this is often impractical to collect in production HPC systems. Unsupervised anomaly detection approaches based on clustering, aimed at alleviating the need for accurate anomaly data, have so far shown poor performance. In this work, we overcome these limitations by proposing RUAD, a novel Recurrent Unsupervised Anomaly Detection model. RUAD achieves better results than the current semi-supervised and unsupervised SoA approaches. This is achieved by considering temporal dependencies in the data and including long-short term memory cells in the model architecture. The proposed approach is assessed on a complete ten-month history of a Tier-0 system (Marconi100 from CINECA with 980 nodes). RUAD achieves an area under the curve (AUC) of 0.763 in semi-supervised training and an AUC of 0.767 in unsupervised training, which improves upon the SoA approach that achieves an AUC of 0.747 in semi-supervised training and an AUC of 0.734 in unsupervised training. It also vastly outperforms the current SoA unsupervised anomaly detection approach based on clustering, achieving the AUC of 0.548.
Machine Learning for Combinatorial Optimisation of Partially-Specified Problems: Regret Minimisation as a Unifying Lens
May 20, 2022

It is increasingly common to solve combinatorial optimisation problems that are partially-specified. We survey the case where the objective function or the relations between variables are not known or are only partially specified. The challenge is to learn them from available data, while taking into account a set of hard constraints that a solution must satisfy, and that solving the optimisation problem (esp. during learning) is computationally very demanding. This paper overviews four seemingly unrelated approaches, that can each be viewed as learning the objective function of a hard combinatorial optimisation problem: 1) surrogate-based optimisation, 2) empirical model learning, 3) decision-focused learning (`predict + optimise'), and 4) structured-output prediction. We formalise each learning paradigm, at first in the ways commonly found in the literature, and then bring the formalisations together in a compatible way using regret. We discuss the differences and interactions between these frameworks, highlight the opportunities for cross-fertilization and survey open directions.
Deep Learning for Virus-Spreading Forecasting: a Brief Survey
Mar 03, 2021
The advent of the coronavirus pandemic has sparked the interest in predictive models capable of forecasting virus-spreading, especially for boosting and supporting decision-making processes. In this paper, we will outline the main Deep Learning approaches aimed at predicting the spreading of a disease in space and time. The aim is to show the emerging trends in this area of research and provide a general perspective on the possible strategies to approach this problem. In doing so, we will mainly focus on two macro-categories: classical Deep Learning approaches and Hybrid models. Finally, we will discuss the main advantages and disadvantages of different models, and underline the most promising development directions to improve these approaches.
A Machine Learning Approach to Online Fault Classification in HPC Systems
Jul 27, 2020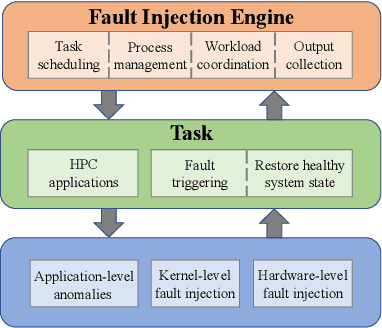
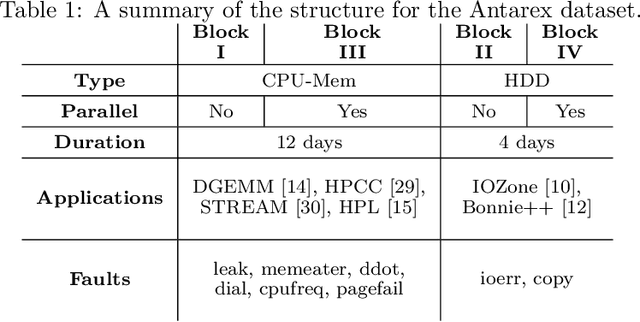
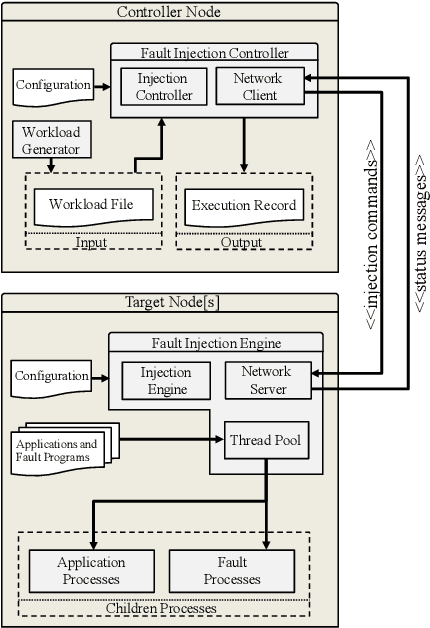

As High-Performance Computing (HPC) systems strive towards the exascale goal, failure rates both at the hardware and software levels will increase significantly. Thus, detecting and classifying faults in HPC systems as they occur and initiating corrective actions before they can transform into failures becomes essential for continued operation. Central to this objective is fault injection, which is the deliberate triggering of faults in a system so as to observe their behavior in a controlled environment. In this paper, we propose a fault classification method for HPC systems based on machine learning. The novelty of our approach rests with the fact that it can be operated on streamed data in an online manner, thus opening the possibility to devise and enact control actions on the target system in real-time. We introduce a high-level, easy-to-use fault injection tool called FINJ, with a focus on the management of complex experiments. In order to train and evaluate our machine learning classifiers, we inject faults to an in-house experimental HPC system using FINJ, and generate a fault dataset which we describe extensively. Both FINJ and the dataset are publicly available to facilitate resiliency research in the HPC systems field. Experimental results demonstrate that our approach allows almost perfect classification accuracy to be reached for different fault types with low computational overhead and minimal delay.
* arXiv admin note: text overlap with arXiv:1807.10056, arXiv:1810.11208
End-to-end learning for semiquantitative rating of COVID-19 severity on Chest X-rays
Jun 08, 2020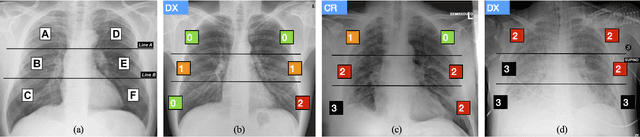
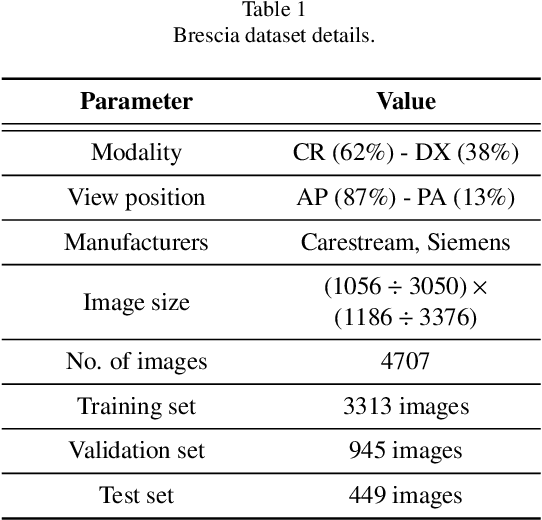
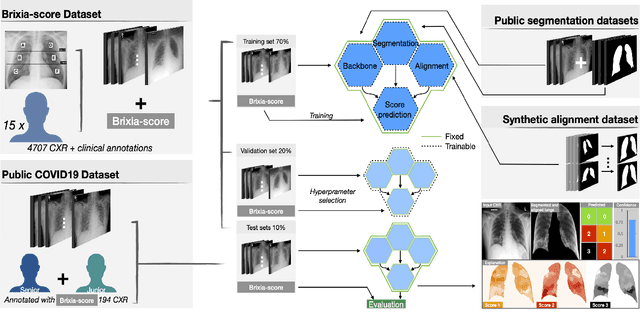
In this work we designed an end-to-end deep learning architecture for predicting, on Chest X-rays images (CRX), a multi-regional score conveying the degree of lung compromise in COVID-19 patients. Such semiquantitative scoring system, namely Brixia-score, was applied in serial monitoring of such patients, showing significant prognostic value, in one of the hospitals that experienced one of the highest pandemic peaks in Italy. To solve such a challenging visual task, we adopt a weakly supervised learning strategy structured to handle different tasks (segmentation, spatial alignment, and score estimation) trained with a "from part to whole" procedure involving different datasets. In particular, we exploited a clinical dataset of almost 5,000 CXR annotated images collected in the same hospital. Our BS-Net demonstrated self-attentive behavior and a high degree of accuracy in all processing stages. Through inter-rater agreement tests and a gold standard comparison, we were able to show that our solution outperforms single human annotators in rating accuracy and consistency, thus supporting the possibility of using this tool in contexts of computer-assisted monitoring. Highly resolved (super-pixel level) explainability maps were also generated, with an original technique, to visually help the understanding of the network activity on the lung areas. We eventually tested the performance robustness of our model on a variegated public COVID-19 dataset, for which we also provide Brixia-score annotations, observing good direct generalization and fine-tuning capabilities that favorably highlight the portability of BS-Net in other clinical settings.
An Analysis of Regularized Approaches for Constrained Machine Learning
May 20, 2020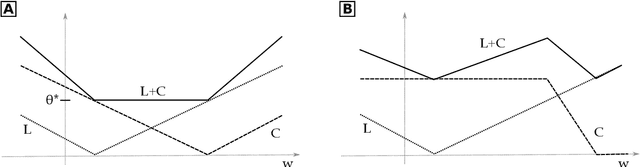
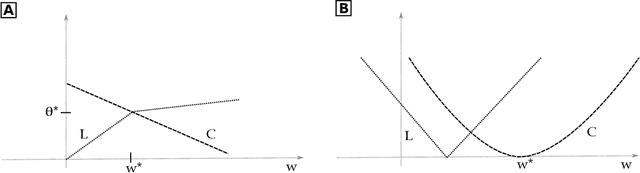
Regularization-based approaches for injecting constraints in Machine Learning (ML) were introduced to improve a predictive model via expert knowledge. We tackle the issue of finding the right balance between the loss (the accuracy of the learner) and the regularization term (the degree of constraint satisfaction). The key results of this paper is the formal demonstration that this type of approach cannot guarantee to find all optimal solutions. In particular, in the non-convex case there might be optima for the constrained problem that do not correspond to any multiplier value.
Improving Deep Learning Models via Constraint-Based Domain Knowledge: a Brief Survey
May 19, 2020Deep Learning (DL) models proved themselves to perform extremely well on a wide variety of learning tasks, as they can learn useful patterns from large data sets. However, purely data-driven models might struggle when very difficult functions need to be learned or when there is not enough available training data. Fortunately, in many domains prior information can be retrieved and used to boost the performance of DL models. This paper presents a first survey of the approaches devised to integrate domain knowledge, expressed in the form of constraints, in DL learning models to improve their performance, in particular targeting deep neural networks. We identify five (non-mutually exclusive) categories that encompass the main approaches to inject domain knowledge: 1) acting on the features space, 2) modifications to the hypothesis space, 3) data augmentation, 4) regularization schemes, 5) constrained learning.
Injective Domain Knowledge in Neural Networks for Transprecision Computing
Feb 24, 2020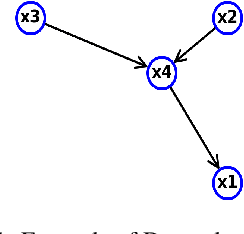
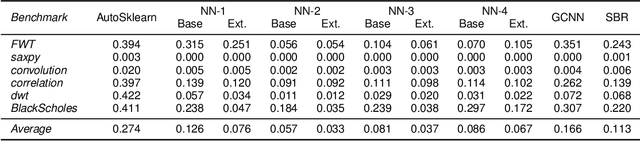

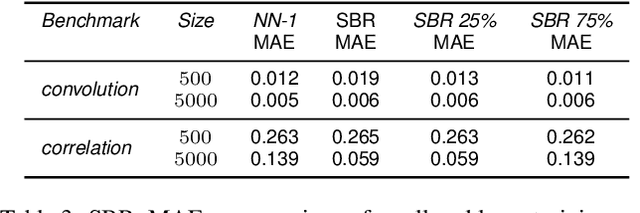
Machine Learning (ML) models are very effective in many learning tasks, due to the capability to extract meaningful information from large data sets. Nevertheless, there are learning problems that cannot be easily solved relying on pure data, e.g. scarce data or very complex functions to be approximated. Fortunately, in many contexts domain knowledge is explicitly available and can be used to train better ML models. This paper studies the improvements that can be obtained by integrating prior knowledge when dealing with a non-trivial learning task, namely precision tuning of transprecision computing applications. The domain information is injected in the ML models in different ways: I) additional features, II) ad-hoc graph-based network topology, III) regularization schemes. The results clearly show that ML models exploiting problem-specific information outperform the purely data-driven ones, with an average accuracy improvement around 38%.
Anomaly Detection using Autoencoders in High Performance Computing Systems
Nov 13, 2018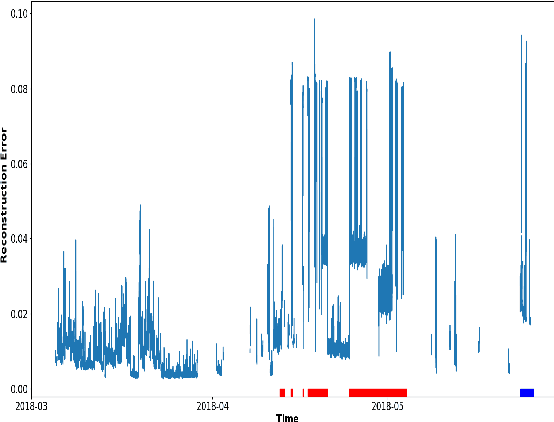
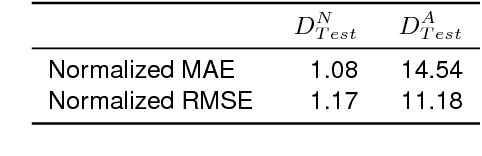
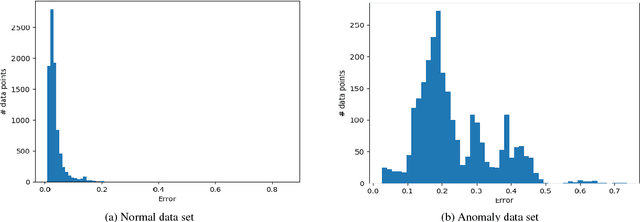
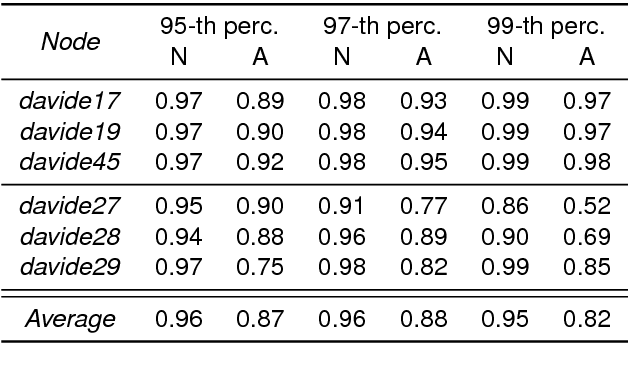
Anomaly detection in supercomputers is a very difficult problem due to the big scale of the systems and the high number of components. The current state of the art for automated anomaly detection employs Machine Learning methods or statistical regression models in a supervised fashion, meaning that the detection tool is trained to distinguish among a fixed set of behaviour classes (healthy and unhealthy states). We propose a novel approach for anomaly detection in High Performance Computing systems based on a Machine (Deep) Learning technique, namely a type of neural network called autoencoder. The key idea is to train a set of autoencoders to learn the normal (healthy) behaviour of the supercomputer nodes and, after training, use them to identify abnormal conditions. This is different from previous approaches which where based on learning the abnormal condition, for which there are much smaller datasets (since it is very hard to identify them to begin with). We test our approach on a real supercomputer equipped with a fine-grained, scalable monitoring infrastructure that can provide large amount of data to characterize the system behaviour. The results are extremely promising: after the training phase to learn the normal system behaviour, our method is capable of detecting anomalies that have never been seen before with a very good accuracy (values ranging between 88% and 96%).