 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging redundancy in attention with Reuse Transformers
Oct 13, 2021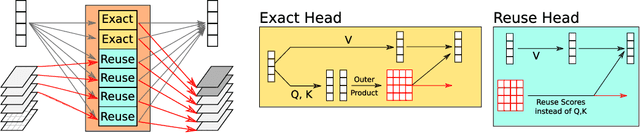
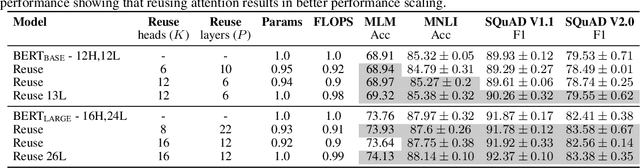
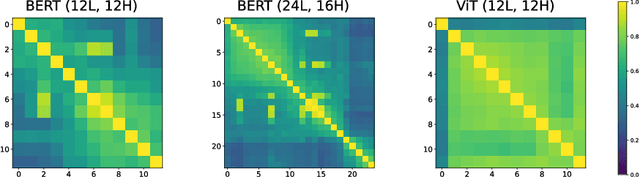
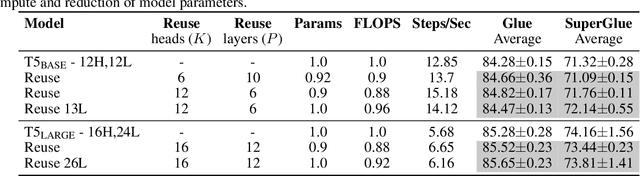
Pairwise dot product-based attention allows Transformers to exchange information between tokens in an input-dependent way, and is key to their success across diverse applications in language and vision. However, a typical Transformer model computes such pairwise attention scores repeatedly for the same sequence, in multiple heads in multiple layers. We systematically analyze the empirical similarity of these scores across heads and layers and find them to be considerably redundant, especially adjacent layers showing high similarity. Motivated by these findings, we propose a novel architecture that reuses attention scores computed in one layer in multiple subsequent layers. Experiments on a number of standard benchmarks show that reusing attention delivers performance equivalent to or better than standard transformers, while reducing both compute and memory usage.
Teacher's pet: understanding and mitigating biases in distillation
Jul 08, 2021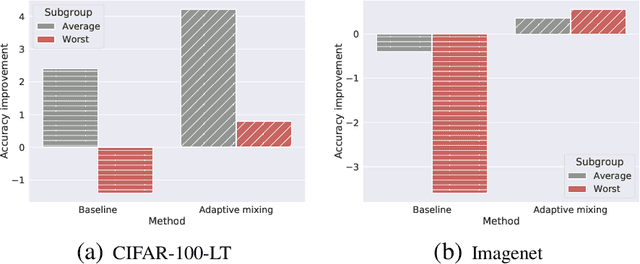

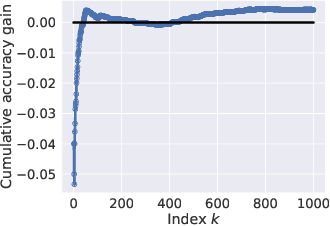
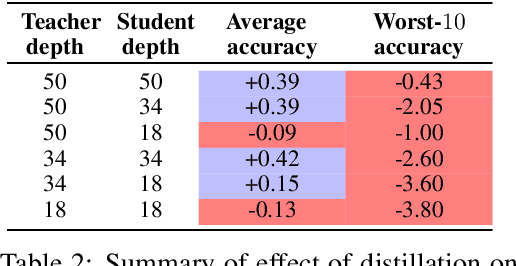
Knowledge distillation is widely used as a means of improving the performance of a relatively simple student model using the predictions from a complex teacher model. Several works have shown that distillation significantly boosts the student's overall performance; however, are these gains uniform across all data subgroups? In this paper, we show that distillation can harm performance on certain subgroups, e.g., classes with few associated samples. We trace this behaviour to errors made by the teacher distribution being transferred to and amplified by the student model. To mitigate this problem, we present techniques which soften the teacher influence for subgroups where it is less reliable. Experiments on several image classification benchmarks show that these modifications of distillation maintain boost in overall accuracy, while additionally ensuring improvement in subgroup performance.
Eigen Analysis of Self-Attention and its Reconstruction from Partial Computation
Jun 16, 2021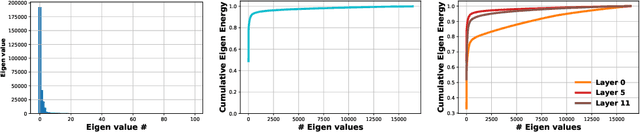
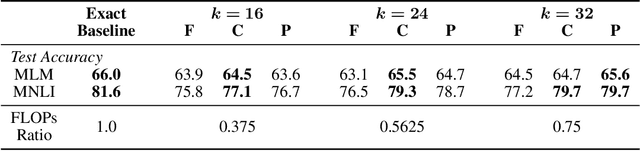
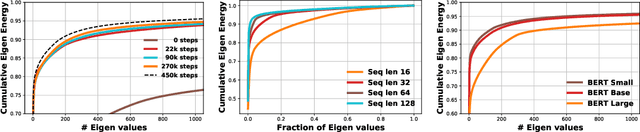
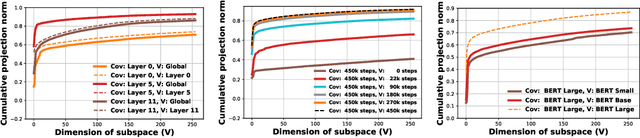
State-of-the-art transformer models use pairwise dot-product based self-attention, which comes at a computational cost quadratic in the input sequence length. In this paper, we investigate the global structure of attention scores computed using this dot product mechanism on a typical distribution of inputs, and study the principal components of their variation. Through eigen analysis of full attention score matrices, as well as of their individual rows, we find that most of the variation among attention scores lie in a low-dimensional eigenspace. Moreover, we find significant overlap between these eigenspaces for different layers and even different transformer models. Based on this, we propose to compute scores only for a partial subset of token pairs, and use them to estimate scores for the remaining pairs. Beyond investigating the accuracy of reconstructing attention scores themselves, we investigate training transformer models that employ these approximations, and analyze the effect on overall accuracy. Our analysis and the proposed method provide insights into how to balance the benefits of exact pair-wise attention and its significant computational expense.
Semantic Label Smoothing for Sequence to Sequence Problems
Oct 15, 2020
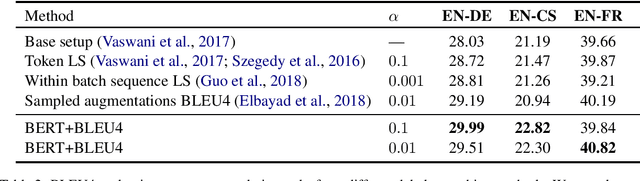

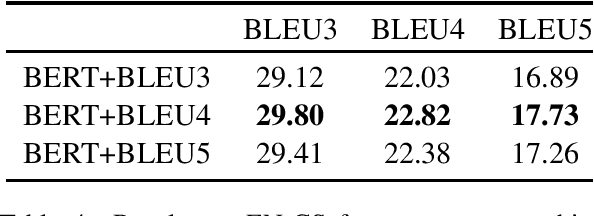
Label smoothing has been shown to be an effective regularization strategy in classification, that prevents overfitting and helps in label de-noising. However, extending such methods directly to seq2seq settings, such as Machine Translation, is challenging: the large target output space of such problems makes it intractable to apply label smoothing over all possible outputs. Most existing approaches for seq2seq settings either do token level smoothing, or smooth over sequences generated by randomly substituting tokens in the target sequence. Unlike these works, in this paper, we propose a technique that smooths over \emph{well formed} relevant sequences that not only have sufficient n-gram overlap with the target sequence, but are also \emph{semantically similar}. Our method shows a consistent and significant improvement over the state-of-the-art techniques on different datasets.
Scaling Graph Neural Networks with Approximate PageRank
Jul 03, 2020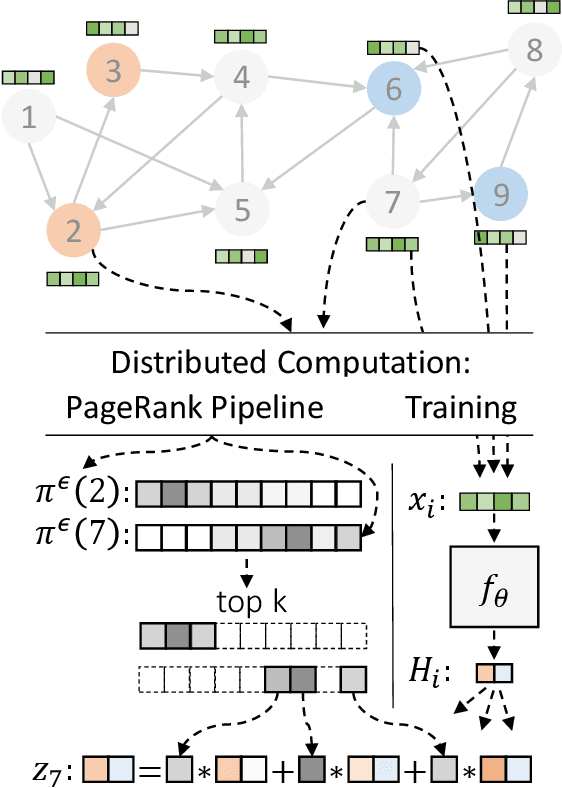



Graph neural networks (GNNs) have emerged as a powerful approach for solving many network mining tasks. However, learning on large graphs remains a challenge - many recently proposed scalable GNN approaches rely on an expensive message-passing procedure to propagate information through the graph. We present the PPRGo model which utilizes an efficient approximation of information diffusion in GNNs resulting in significant speed gains while maintaining state-of-the-art prediction performance. In addition to being faster, PPRGo is inherently scalable, and can be trivially parallelized for large datasets like those found in industry settings. We demonstrate that PPRGo outperforms baselines in both distributed and single-machine training environments on a number of commonly used academic graphs. To better analyze the scalability of large-scale graph learning methods, we introduce a novel benchmark graph with 12.4 million nodes, 173 million edges, and 2.8 million node features. We show that training PPRGo from scratch and predicting labels for all nodes in this graph takes under 2 minutes on a single machine, far outpacing other baselines on the same graph. We discuss the practical application of PPRGo to solve large-scale node classification problems at Google.
Text Segmentation by Cross Segment Attention
Apr 30, 2020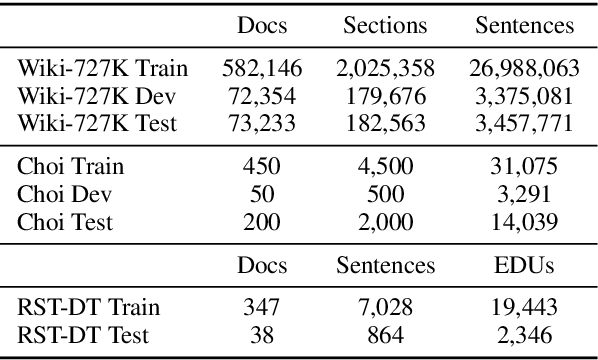
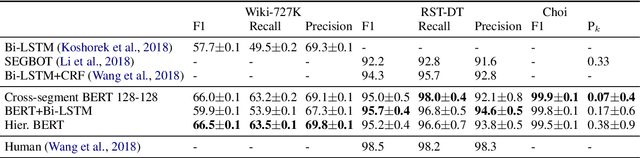
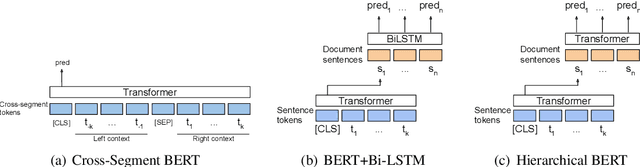
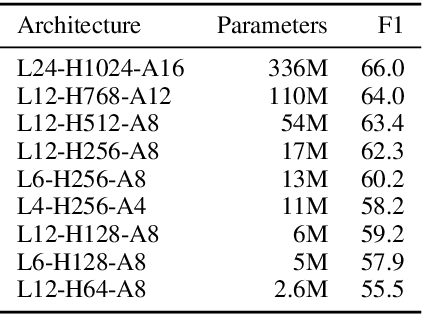
Document and discourse segmentation are two fundamental NLP tasks pertaining to breaking up text into constituents, which are commonly used to help downstream tasks such as information retrieval or text summarization. In this work, we propose three transformer-based architectures and provide comprehensive comparisons with previously proposed approaches on three standard datasets. We establish a new state-of-the-art, reducing in particular the error rates by a large margin in all cases. We further analyze model sizes and find that we can build models with many fewer parameters while keeping good performance, thus facilitating real-world applications.
Does label smoothing mitigate label noise?
Mar 05, 2020
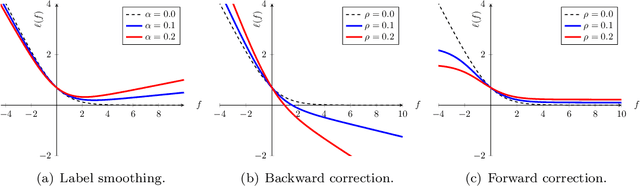
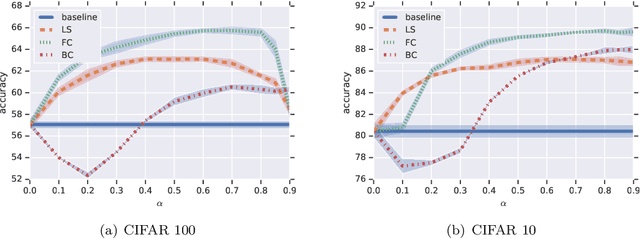

Label smoothing is commonly used in training deep learning models, wherein one-hot training labels are mixed with uniform label vectors. Empirically, smoothing has been shown to improve both predictive performance and model calibration. In this paper, we study whether label smoothing is also effective as a means of coping with label noise. While label smoothing apparently amplifies this problem --- being equivalent to injecting symmetric noise to the labels --- we show how it relates to a general family of loss-correction techniques from the label noise literature. Building on this connection, we show that label smoothing is competitive with loss-correction under label noise. Further, we show that when distilling models from noisy data, label smoothing of the teacher is beneficial; this is in contrast to recent findings for noise-free problems, and sheds further light on settings where label smoothing is beneficial.
Discourse-Aware Rumour Stance Classification in Social Media Using Sequential Classifiers
Dec 06, 2017
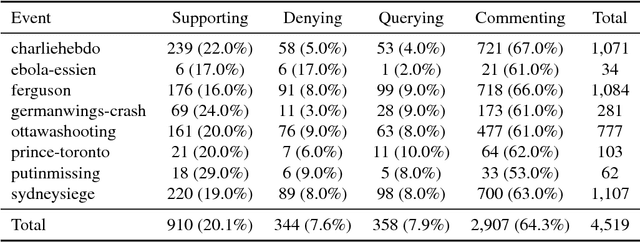
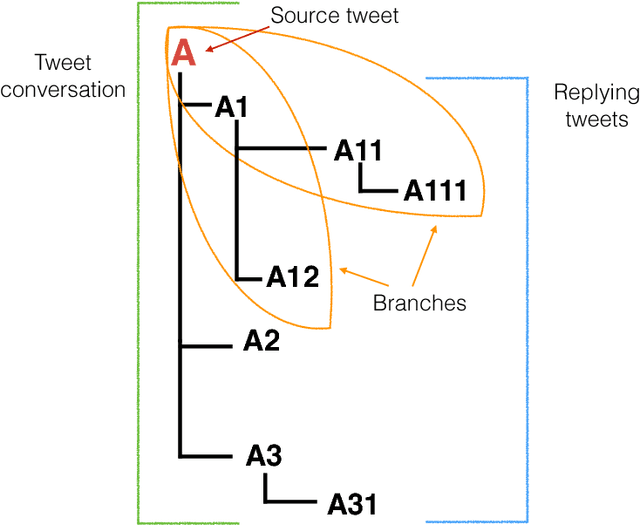
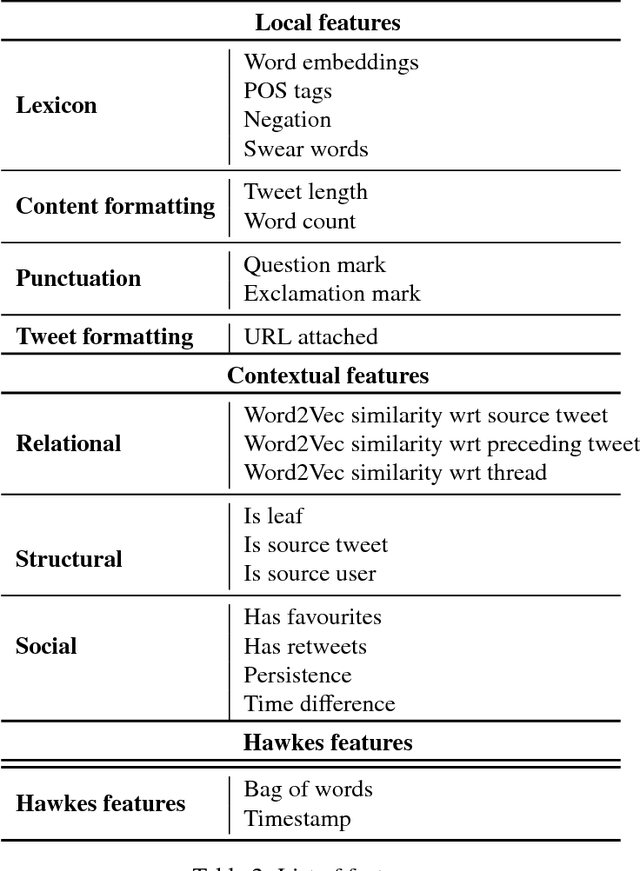
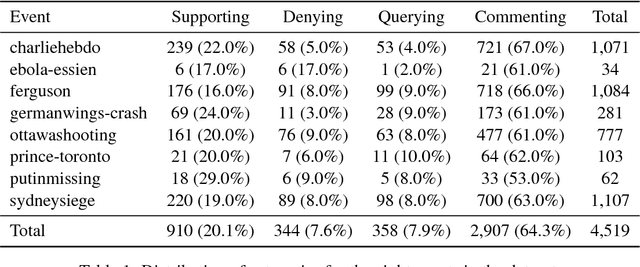
Rumour stance classification, defined as classifying the stance of specific social media posts into one of supporting, denying, querying or commenting on an earlier post, is becoming of increasing interest to researchers. While most previous work has focused on using individual tweets as classifier inputs, here we report on the performance of sequential classifiers that exploit the discourse features inherent in social media interactions or 'conversational threads'. Testing the effectiveness of four sequential classifiers -- Hawkes Processes, Linear-Chain Conditional Random Fields (Linear CRF), Tree-Structured Conditional Random Fields (Tree CRF) and Long Short Term Memory networks (LSTM) -- on eight datasets associated with breaking news stories, and looking at different types of local and contextual features, our work sheds new light on the development of accurate stance classifiers. We show that sequential classifiers that exploit the use of discourse properties in social media conversations while using only local features, outperform non-sequential classifiers. Furthermore, we show that LSTM using a reduced set of features can outperform the other sequential classifiers; this performance is consistent across datasets and across types of stances. To conclude, our work also analyses the different features under study, identifying those that best help characterise and distinguish between stances, such as supporting tweets being more likely to be accompanied by evidence than denying tweets. We also set forth a number of directions for future research.
Stance Classification in Rumours as a Sequential Task Exploiting the Tree Structure of Social Media Conversations
Oct 11, 2016
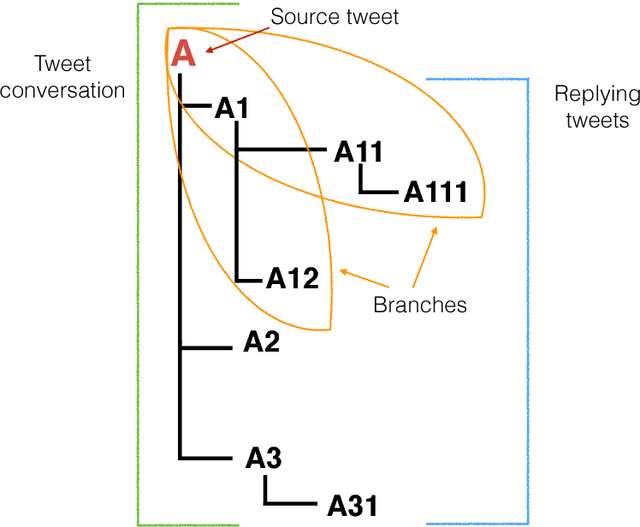
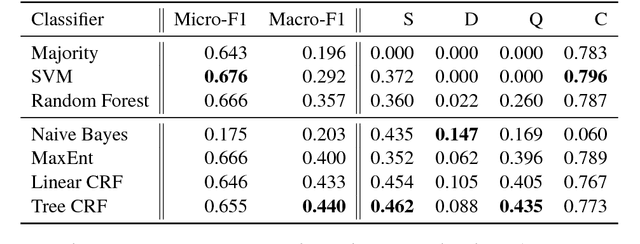
Rumour stance classification, the task that determines if each tweet in a collection discussing a rumour is supporting, denying, questioning or simply commenting on the rumour, has been attracting substantial interest. Here we introduce a novel approach that makes use of the sequence of transitions observed in tree-structured conversation threads in Twitter. The conversation threads are formed by harvesting users' replies to one another, which results in a nested tree-like structure. Previous work addressing the stance classification task has treated each tweet as a separate unit. Here we analyse tweets by virtue of their position in a sequence and test two sequential classifiers, Linear-Chain CRF and Tree CRF, each of which makes different assumptions about the conversational structure. We experiment with eight Twitter datasets, collected during breaking news, and show that exploiting the sequential structure of Twitter conversations achieves significant improvements over the non-sequential methods. Our work is the first to model Twitter conversations as a tree structure in this manner, introducing a novel way of tackling NLP tasks on Twitter conversations.
Using Gaussian Processes for Rumour Stance Classification in Social Media
Sep 07, 2016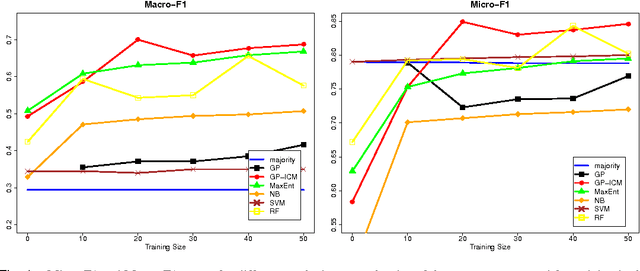
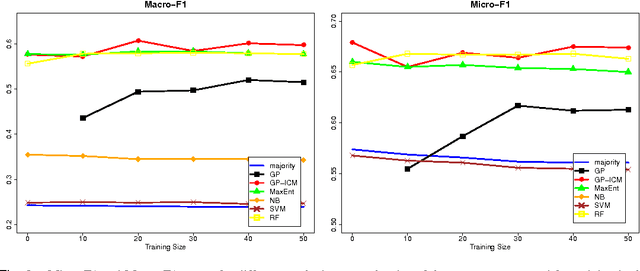

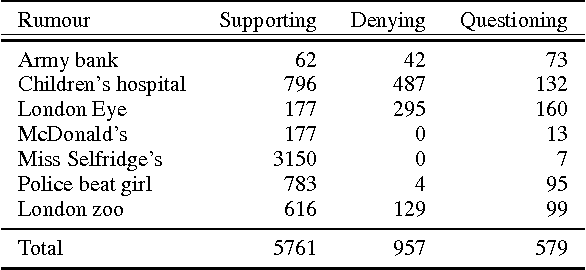
Social media tend to be rife with rumours while new reports are released piecemeal during breaking news. Interestingly, one can mine multiple reactions expressed by social media users in those situations, exploring their stance towards rumours, ultimately enabling the flagging of highly disputed rumours as being potentially false. In this work, we set out to develop an automated, supervised classifier that uses multi-task learning to classify the stance expressed in each individual tweet in a rumourous conversation as either supporting, denying or questioning the rumour. Using a classifier based on Gaussian Processes, and exploring its effectiveness on two datasets with very different characteristics and varying distributions of stances, we show that our approach consistently outperforms competitive baseline classifiers. Our classifier is especially effective in estimating the distribution of different types of stance associated with a given rumour, which we set forth as a desired characteristic for a rumour-tracking system that will warn both ordinary users of Twitter and professional news practitioners when a rumour is being rebutted.