 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore than meets the eye: Self-supervised depth reconstruction from brain activity
Jun 09, 2021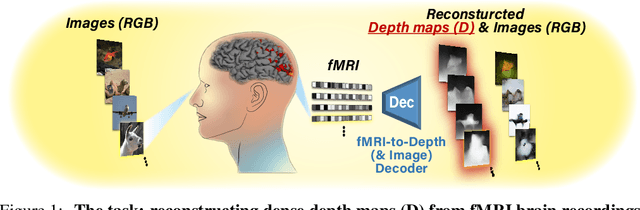
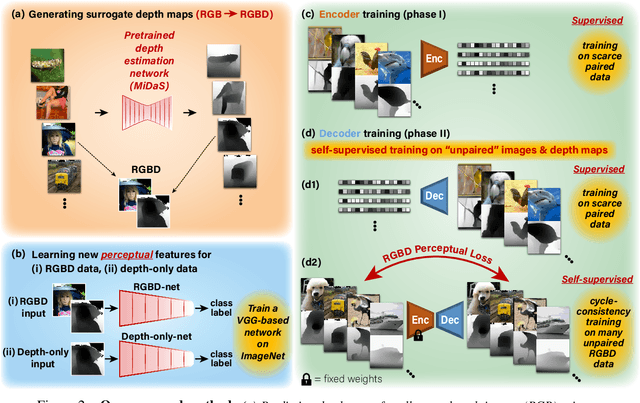

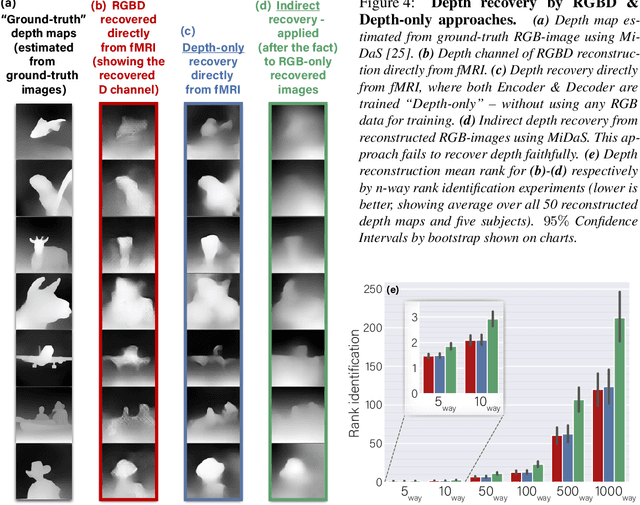
In the past few years, significant advancements were made in reconstruction of observed natural images from fMRI brain recordings using deep-learning tools. Here, for the first time, we show that dense 3D depth maps of observed 2D natural images can also be recovered directly from fMRI brain recordings. We use an off-the-shelf method to estimate the unknown depth maps of natural images. This is applied to both: (i) the small number of images presented to subjects in an fMRI scanner (images for which we have fMRI recordings - referred to as "paired" data), and (ii) a very large number of natural images with no fMRI recordings ("unpaired data"). The estimated depth maps are then used as an auxiliary reconstruction criterion to train for depth reconstruction directly from fMRI. We propose two main approaches: Depth-only recovery and joint image-depth RGBD recovery. Because the number of available "paired" training data (images with fMRI) is small, we enrich the training data via self-supervised cycle-consistent training on many "unpaired" data (natural images & depth maps without fMRI). This is achieved using our newly defined and trained Depth-based Perceptual Similarity metric as a reconstruction criterion. We show that predicting the depth map directly from fMRI outperforms its indirect sequential recovery from the reconstructed images. We further show that activations from early cortical visual areas dominate our depth reconstruction results, and propose means to characterize fMRI voxels by their degree of depth-information tuning. This work adds an important layer of decoded information, extending the current envelope of visual brain decoding capabilities.
Explaining in Style: Training a GAN to explain a classifier in StyleSpace
Apr 27, 2021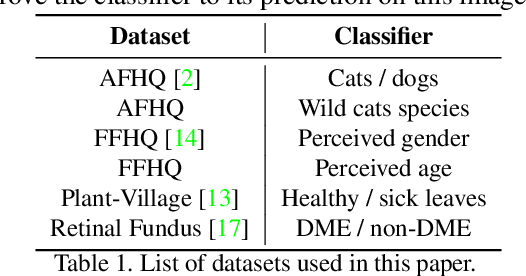
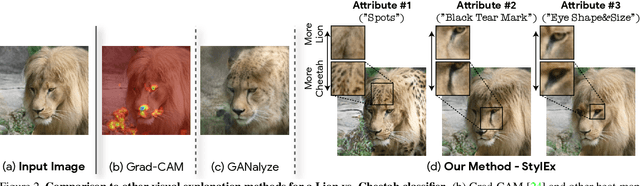
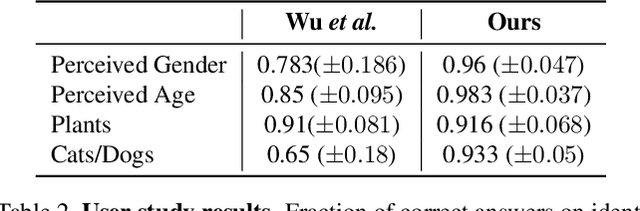
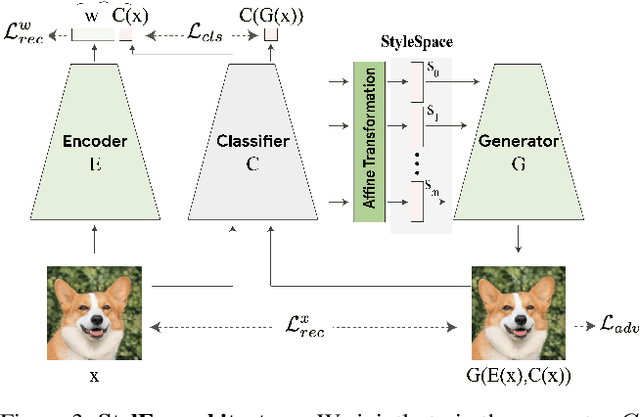
Image classification models can depend on multiple different semantic attributes of the image. An explanation of the decision of the classifier needs to both discover and visualize these properties. Here we present StylEx, a method for doing this, by training a generative model to specifically explain multiple attributes that underlie classifier decisions. A natural source for such attributes is the StyleSpace of StyleGAN, which is known to generate semantically meaningful dimensions in the image. However, because standard GAN training is not dependent on the classifier, it may not represent these attributes which are important for the classifier decision, and the dimensions of StyleSpace may represent irrelevant attributes. To overcome this, we propose a training procedure for a StyleGAN, which incorporates the classifier model, in order to learn a classifier-specific StyleSpace. Explanatory attributes are then selected from this space. These can be used to visualize the effect of changing multiple attributes per image, thus providing image-specific explanations. We apply StylEx to multiple domains, including animals, leaves, faces and retinal images. For these, we show how an image can be modified in different ways to change its classifier output. Our results show that the method finds attributes that align well with semantic ones, generate meaningful image-specific explanations, and are human-interpretable as measured in user-studies.
Drop the GAN: In Defense of Patches Nearest Neighbors as Single Image Generative Models
Mar 29, 2021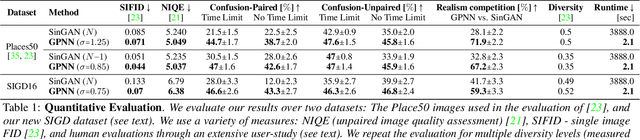
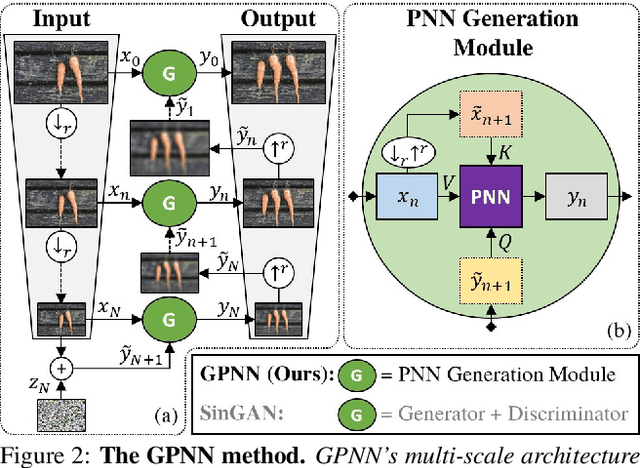
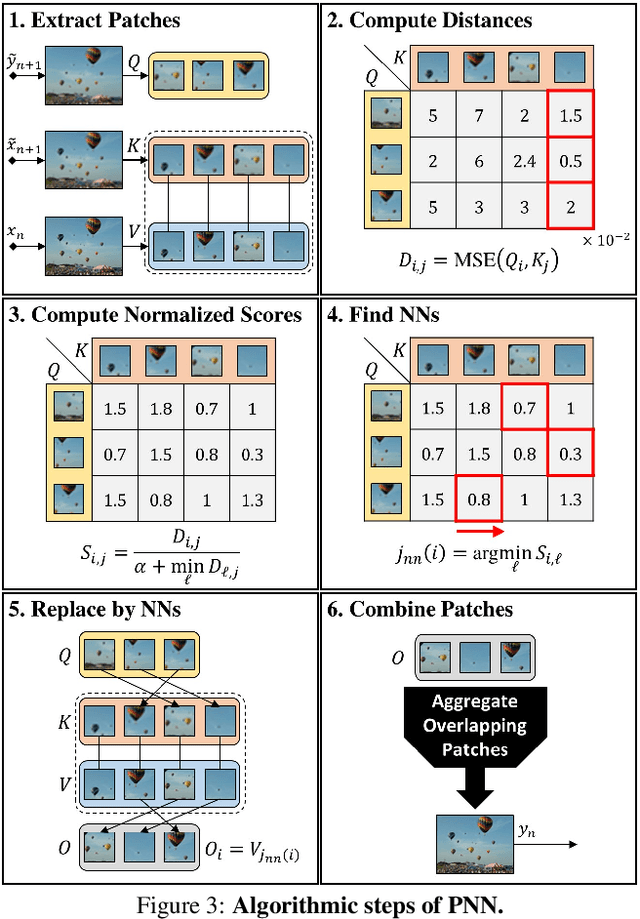

Single image generative models perform synthesis and manipulation tasks by capturing the distribution of patches within a single image. The classical (pre Deep Learning) prevailing approaches for these tasks are based on an optimization process that maximizes patch similarity between the input and generated output. Recently, however, Single Image GANs were introduced both as a superior solution for such manipulation tasks, but also for remarkable novel generative tasks. Despite their impressiveness, single image GANs require long training time (usually hours) for each image and each task. They often suffer from artifacts and are prone to optimization issues such as mode collapse. In this paper, we show that all of these tasks can be performed without any training, within several seconds, in a unified, surprisingly simple framework. We revisit and cast the "good-old" patch-based methods into a novel optimization-free framework. We start with an initial coarse guess, and then simply refine the details coarse-to-fine using patch-nearest-neighbor search. This allows generating random novel images better and much faster than GANs. We further demonstrate a wide range of applications, such as image editing and reshuffling, retargeting to different sizes, structural analogies, image collage and a newly introduced task of conditional inpainting. Not only is our method faster ($\times 10^3$-$\times 10^4$ than a GAN), it produces superior results (confirmed by quantitative and qualitative evaluation), less artifacts and more realistic global structure than any of the previous approaches (whether GAN-based or classical patch-based).
From Discrete to Continuous Convolution Layers
Jun 19, 2020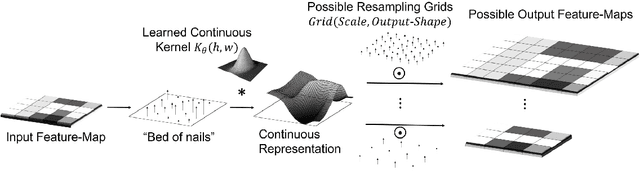
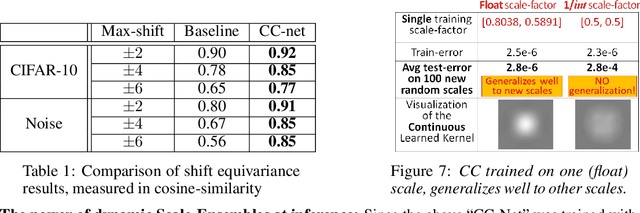
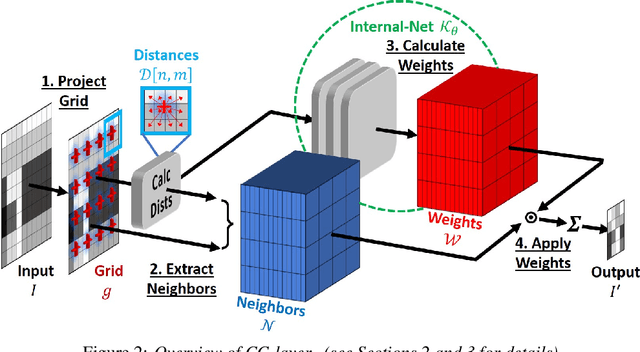

A basic operation in Convolutional Neural Networks (CNNs) is spatial resizing of feature maps. This is done either by strided convolution (donwscaling) or transposed convolution (upscaling). Such operations are limited to a fixed filter moving at predetermined integer steps (strides). Spatial sizes of consecutive layers are related by integer scale factors, predetermined at architectural design, and remain fixed throughout training and inference time. We propose a generalization of the common Conv-layer, from a discrete layer to a Continuous Convolution (CC) Layer. CC Layers naturally extend Conv-layers by representing the filter as a learned continuous function over sub-pixel coordinates. This allows learnable and principled resizing of feature maps, to any size, dynamically and consistently across scales. Once trained, the CC layer can be used to output any scale/size chosen at inference time. The scale can be non-integer and differ between the axes. CC gives rise to new freedoms for architectural design, such as dynamic layer shapes at inference time, or gradual architectures where the size changes by a small factor at each layer. This gives rise to many desired CNN properties, new architectural design capabilities, and useful applications. We further show that current Conv-layers suffer from inherent misalignments, which are ameliorated by CC layers.
SpeedNet: Learning the Speediness in Videos
Apr 13, 2020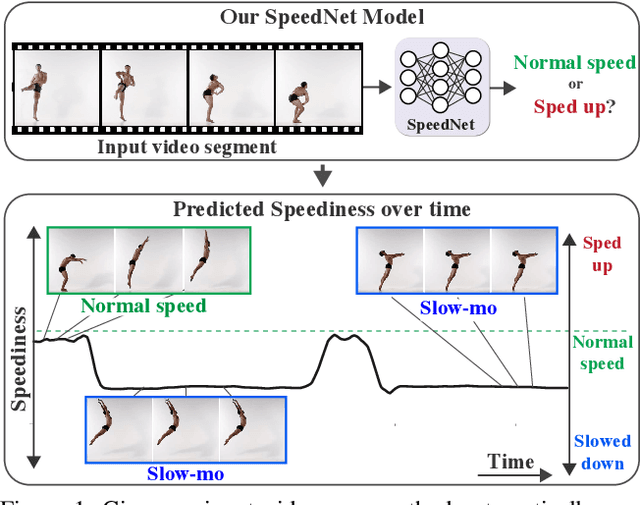
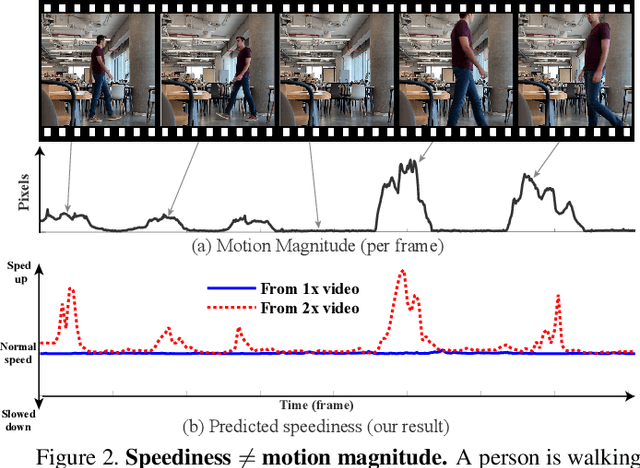
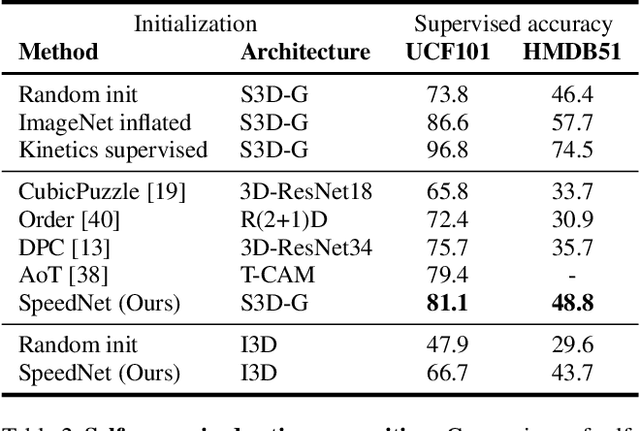
We wish to automatically predict the "speediness" of moving objects in videos---whether they move faster, at, or slower than their "natural" speed. The core component in our approach is SpeedNet---a novel deep network trained to detect if a video is playing at normal rate, or if it is sped up. SpeedNet is trained on a large corpus of natural videos in a self-supervised manner, without requiring any manual annotations. We show how this single, binary classification network can be used to detect arbitrary rates of speediness of objects. We demonstrate prediction results by SpeedNet on a wide range of videos containing complex natural motions, and examine the visual cues it utilizes for making those predictions. Importantly, we show that through predicting the speed of videos, the model learns a powerful and meaningful space-time representation that goes beyond simple motion cues. We demonstrate how those learned features can boost the performance of self-supervised action recognition, and can be used for video retrieval. Furthermore, we also apply SpeedNet for generating time-varying, adaptive video speedups, which can allow viewers to watch videos faster, but with less of the jittery, unnatural motions typical to videos that are sped up uniformly.
Across Scales \& Across Dimensions: Temporal Super-Resolution using Deep Internal Learning
Mar 19, 2020When a very fast dynamic event is recorded with a low-framerate camera, the resulting video suffers from severe motion blur (due to exposure time) and motion aliasing (due to low sampling rate in time). True Temporal Super-Resolution (TSR) is more than just Temporal-Interpolation (increasing framerate). It can also recover new high temporal frequencies beyond the temporal Nyquist limit of the input video, thus resolving both motion-blur and motion-aliasing effects that temporal frame interpolation (as sophisticated as it maybe) cannot undo. In this paper we propose a "Deep Internal Learning" approach for true TSR. We train a video-specific CNN on examples extracted directly from the low-framerate input video. Our method exploits the strong recurrence of small space-time patches inside a single video sequence, both within and across different spatio-temporal scales of the video. We further observe (for the first time) that small space-time patches recur also across-dimensions of the video sequence - i.e., by swapping the spatial and temporal dimensions. In particular, the higher spatial resolution of video frames provides strong examples as to how to increase the temporal resolution of that video. Such internal video-specific examples give rise to strong self-supervision, requiring no data but the input video itself. This results in Zero-Shot Temporal-SR of complex videos, which removes both motion blur and motion aliasing, outperforming previous supervised methods trained on external video datasets.
Semantic Pyramid for Image Generation
Mar 16, 2020

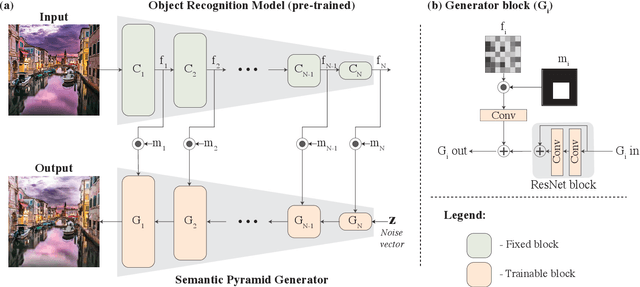
We present a novel GAN-based model that utilizes the space of deep features learned by a pre-trained classification model. Inspired by classical image pyramid representations, we construct our model as a Semantic Generation Pyramid -- a hierarchical framework which leverages the continuum of semantic information encapsulated in such deep features; this ranges from low level information contained in fine features to high level, semantic information contained in deeper features. More specifically, given a set of features extracted from a reference image, our model generates diverse image samples, each with matching features at each semantic level of the classification model. We demonstrate that our model results in a versatile and flexible framework that can be used in various classic and novel image generation tasks. These include: generating images with a controllable extent of semantic similarity to a reference image, and different manipulation tasks such as semantically-controlled inpainting and compositing; all achieved with the same model, with no further training.
Blind Super-Resolution Kernel Estimation using an Internal-GAN
Oct 24, 2019
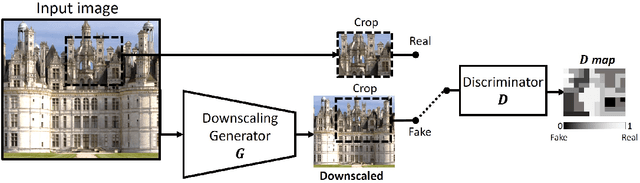
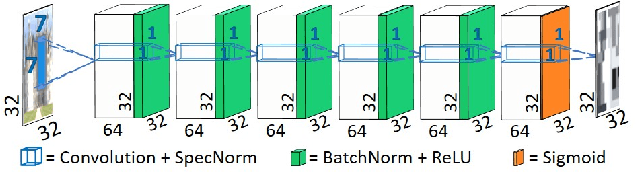
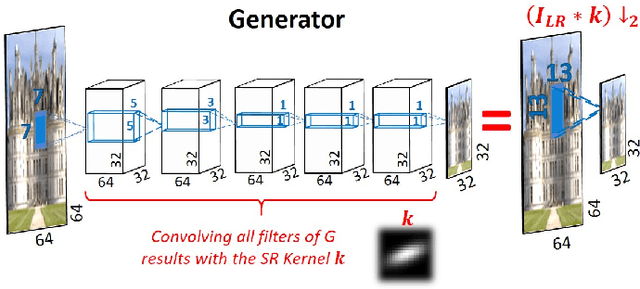
Super resolution (SR) methods typically assume that the low-resolution (LR) image was downscaled from the unknown high-resolution (HR) image by a fixed 'ideal' downscaling kernel (e.g. Bicubic downscaling). However, this is rarely the case in real LR images, in contrast to synthetically generated SR datasets. When the assumed downscaling kernel deviates from the true one, the performance of SR methods significantly deteriorates. This gave rise to Blind-SR - namely, SR when the downscaling kernel ("SR-kernel") is unknown. It was further shown that the true SR-kernel is the one that maximizes the recurrence of patches across scales of the LR image. In this paper we show how this powerful cross-scale recurrence property can be realized using Deep Internal Learning. We introduce "KernelGAN", an image-specific Internal-GAN, which trains solely on the LR test image at test time, and learns its internal distribution of patches. Its Generator is trained to produce a downscaled version of the LR test image, such that its Discriminator cannot distinguish between the patch distribution of the downscaled image, and the patch distribution of the original LR image. The Generator, once trained, constitutes the downscaling operation with the correct image-specific SR-kernel. KernelGAN is fully unsupervised, requires no training data other than the input image itself, and leads to state-of-the-art results in Blind-SR when plugged into existing SR algorithms.
From voxels to pixels and back: Self-supervision in natural-image reconstruction from fMRI
Jul 03, 2019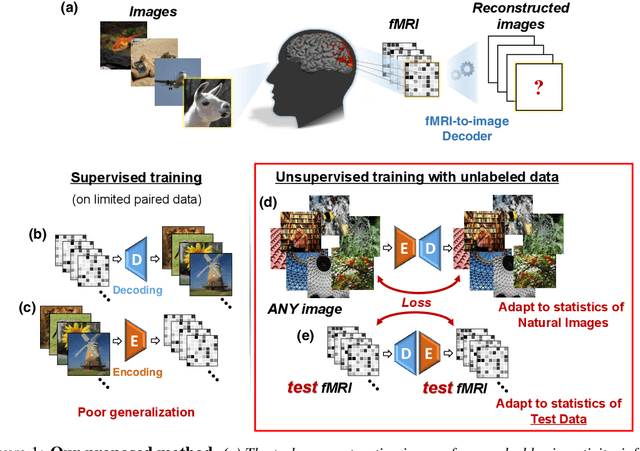
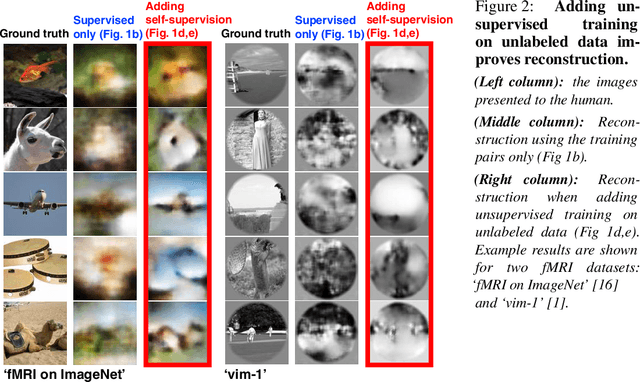
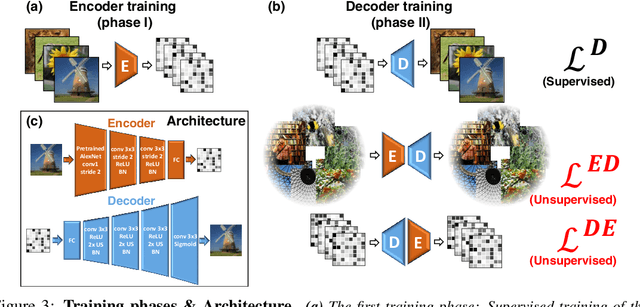
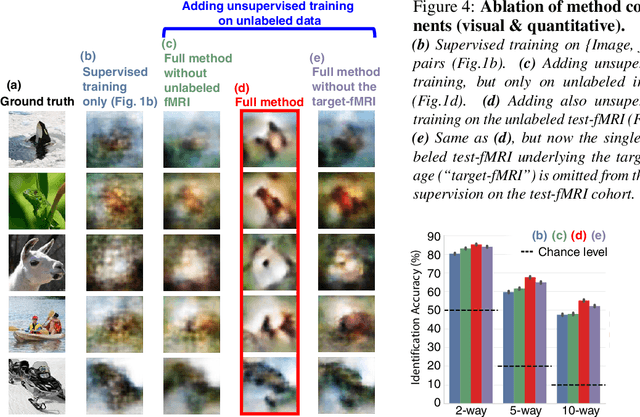
Reconstructing observed images from fMRI brain recordings is challenging. Unfortunately, acquiring sufficient "labeled" pairs of {Image, fMRI} (i.e., images with their corresponding fMRI responses) to span the huge space of natural images is prohibitive for many reasons. We present a novel approach which, in addition to the scarce labeled data (training pairs), allows to train fMRI-to-image reconstruction networks also on "unlabeled" data (i.e., images without fMRI recording, and fMRI recording without images). The proposed model utilizes both an Encoder network (image-to-fMRI) and a Decoder network (fMRI-to-image). Concatenating these two networks back-to-back (Encoder-Decoder & Decoder-Encoder) allows augmenting the training with both types of unlabeled data. Importantly, it allows training on the unlabeled test-fMRI data. This self-supervision adapts the reconstruction network to the new input test-data, despite its deviation from the statistics of the scarce training data.
Natural and Adversarial Error Detection using Invariance to Image Transformations
Feb 01, 2019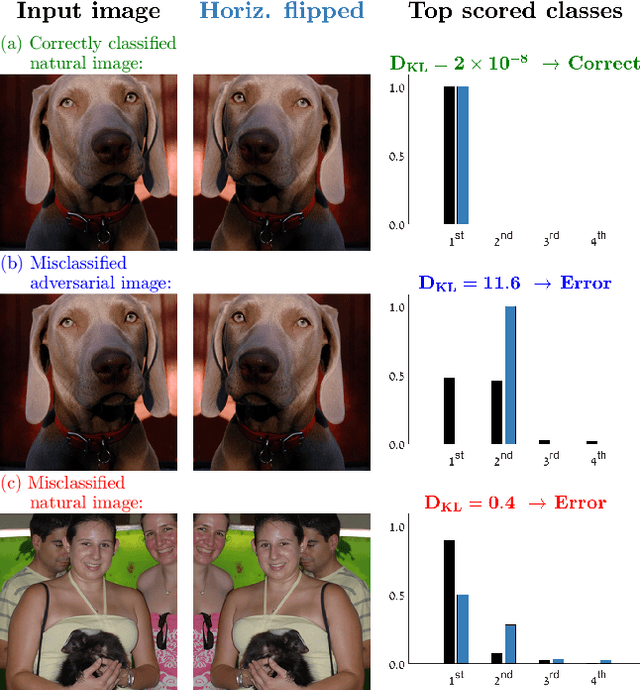
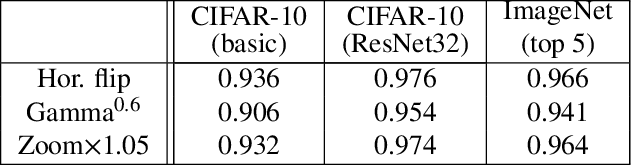

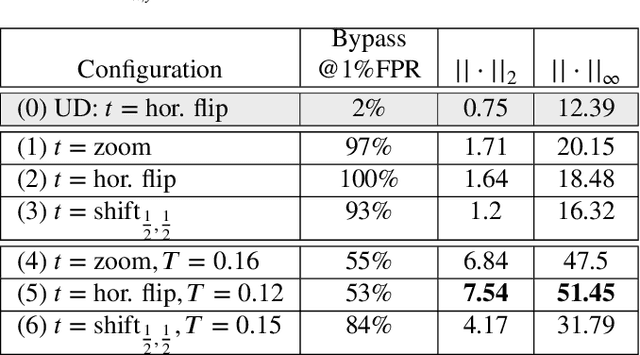
We propose an approach to distinguish between correct and incorrect image classifications. Our approach can detect misclassifications which either occur $\it{unintentionally}$ ("natural errors"), or due to $\it{intentional~adversarial~attacks}$ ("adversarial errors"), both in a single $\it{unified~framework}$. Our approach is based on the observation that correctly classified images tend to exhibit robust and consistent classifications under certain image transformations (e.g., horizontal flip, small image translation, etc.). In contrast, incorrectly classified images (whether due to adversarial errors or natural errors) tend to exhibit large variations in classification results under such transformations. Our approach does not require any modifications or retraining of the classifier, hence can be applied to any pre-trained classifier. We further use state of the art targeted adversarial attacks to demonstrate that even when the adversary has full knowledge of our method, the adversarial distortion needed for bypassing our detector is $\it{no~longer~imperceptible~to~the~human~eye}$. Our approach obtains state-of-the-art results compared to previous adversarial detection methods, surpassing them by a large margin.