 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Interplay of Scale, Data, and Bias in Language Models: A Case Study with BERT
Jul 25, 2024



In the current landscape of language model research, larger models, larger datasets and more compute seems to be the only way to advance towards intelligence. While there have been extensive studies of scaling laws and models' scaling behaviors, the effect of scale on a model's social biases and stereotyping tendencies has received less attention. In this study, we explore the influence of model scale and pre-training data on its learnt social biases. We focus on BERT -- an extremely popular language model -- and investigate biases as they show up during language modeling (upstream), as well as during classification applications after fine-tuning (downstream). Our experiments on four architecture sizes of BERT demonstrate that pre-training data substantially influences how upstream biases evolve with model scale. With increasing scale, models pre-trained on large internet scrapes like Common Crawl exhibit higher toxicity, whereas models pre-trained on moderated data sources like Wikipedia show greater gender stereotypes. However, downstream biases generally decrease with increasing model scale, irrespective of the pre-training data. Our results highlight the qualitative role of pre-training data in the biased behavior of language models, an often overlooked aspect in the study of scale. Through a detailed case study of BERT, we shed light on the complex interplay of data and model scale, and investigate how it translates to concrete biases.
Conjugate Energy-Based Models
Jun 25, 2021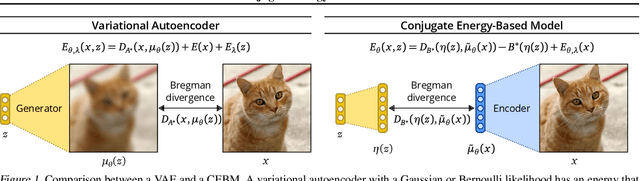
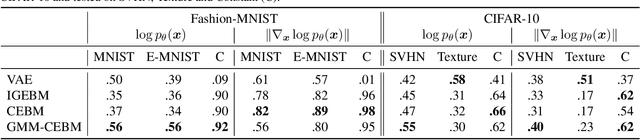

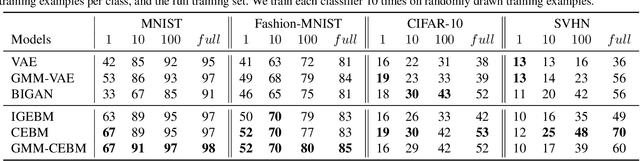
In this paper, we propose conjugate energy-based models (CEBMs), a new class of energy-based models that define a joint density over data and latent variables. The joint density of a CEBM decomposes into an intractable distribution over data and a tractable posterior over latent variables. CEBMs have similar use cases as variational autoencoders, in the sense that they learn an unsupervised mapping from data to latent variables. However, these models omit a generator network, which allows them to learn more flexible notions of similarity between data points. Our experiments demonstrate that conjugate EBMs achieve competitive results in terms of image modelling, predictive power of latent space, and out-of-domain detection on a variety of datasets.
Sketching for Latent Dirichlet-Categorical Models
Oct 02, 2018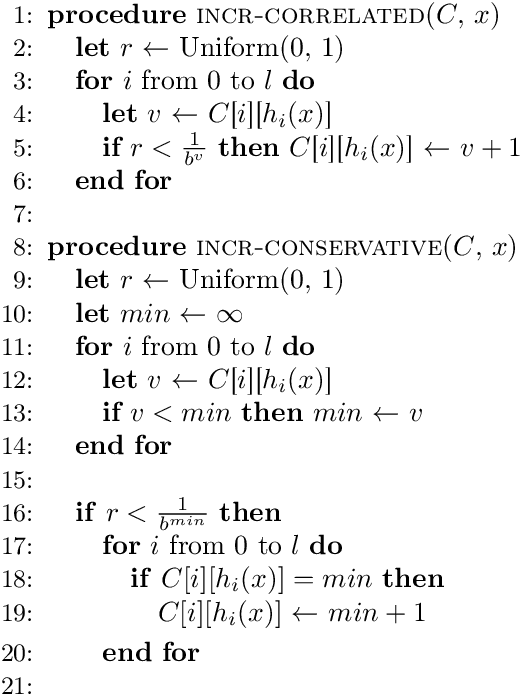
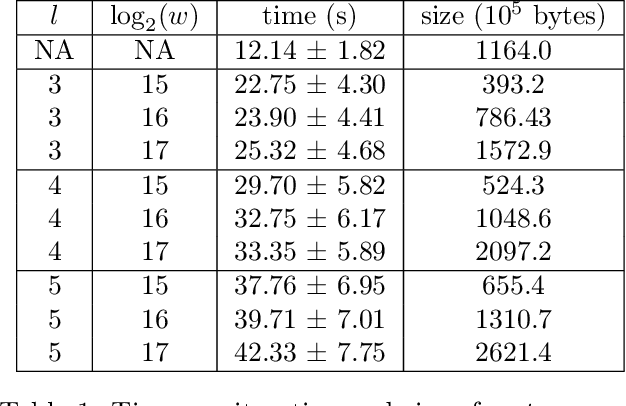
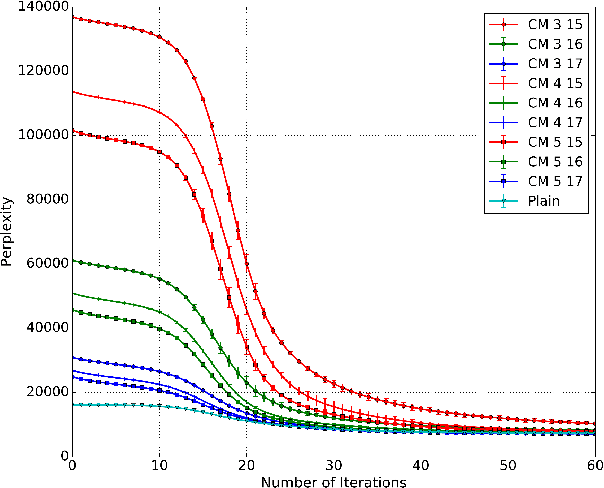
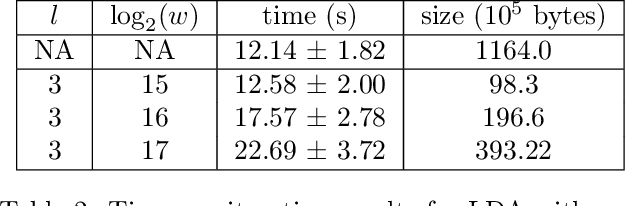
Recent work has explored transforming data sets into smaller, approximate summaries in order to scale Bayesian inference. We examine a related problem in which the parameters of a Bayesian model are very large and expensive to store in memory, and propose more compact representations of parameter values that can be used during inference. We focus on a class of graphical models that we refer to as latent Dirichlet-Categorical models, and show how a combination of two sketching algorithms known as count-min sketch and approximate counters provide an efficient representation for them. We show that this sketch combination -- which, despite having been used before in NLP applications, has not been previously analyzed -- enjoys desirable properties. We prove that for this class of models, when the sketches are used during Markov Chain Monte Carlo inference, the equilibrium of sketched MCMC converges to that of the exact chain as sketch parameters are tuned to reduce the error rate.
Gradient-based Inference for Networks with Output Constraints
Aug 26, 2018

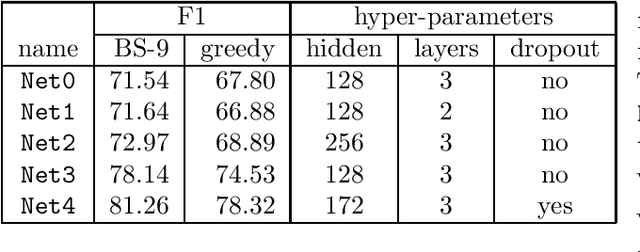

Practitioners apply neural networks to increasingly complex problems in natural language processing (NLP), such as syntactic parsing that have rich output structures. Many such structured-prediction problems require deterministic constraints on the output values; for example, in sequence-to-sequence syntactic parsing, we require that the sequential outputs encode valid trees. While hidden units might capture such properties, the network is not always able to learn such constraints from the training data alone, and practitioners must then resort to post-processing. In this paper, we present an inference method for neural networks that enforces deterministic constraints on outputs without performing rule-based post-processing or expensive discrete search. Instead, in the spirit of gradient-based training, we enforce constraints with gradient-based inference: for each input at test-time, we nudge continuous weights until the network's unconstrained inference procedure generates an output that satisfies the constraints. We apply our methods to three tasks with hard constraints: sequence transduction, constituency parsing, and semantic role labeling (SRL). In each case, the algorithm not only satisfies constraints but improves accuracy, even when the underlying network is state-of-the-art.
Distantly Labeling Data for Large Scale Cross-Document Coreference
May 24, 2010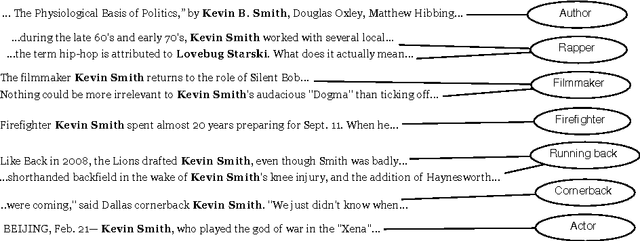

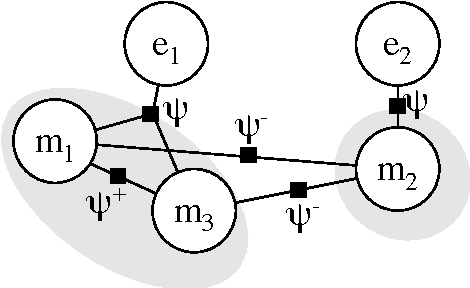
Cross-document coreference, the problem of resolving entity mentions across multi-document collections, is crucial to automated knowledge base construction and data mining tasks. However, the scarcity of large labeled data sets has hindered supervised machine learning research for this task. In this paper we develop and demonstrate an approach based on ``distantly-labeling'' a data set from which we can train a discriminative cross-document coreference model. In particular we build a dataset of more than a million people mentions extracted from 3.5 years of New York Times articles, leverage Wikipedia for distant labeling with a generative model (and measure the reliability of such labeling); then we train and evaluate a conditional random field coreference model that has factors on cross-document entities as well as mention-pairs. This coreference model obtains high accuracy in resolving mentions and entities that are not present in the training data, indicating applicability to non-Wikipedia data. Given the large amount of data, our work is also an exercise demonstrating the scalability of our approach.
Scalable Probabilistic Databases with Factor Graphs and MCMC
May 11, 2010
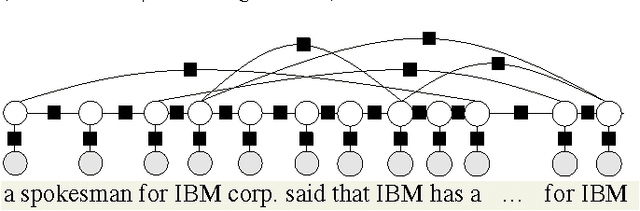
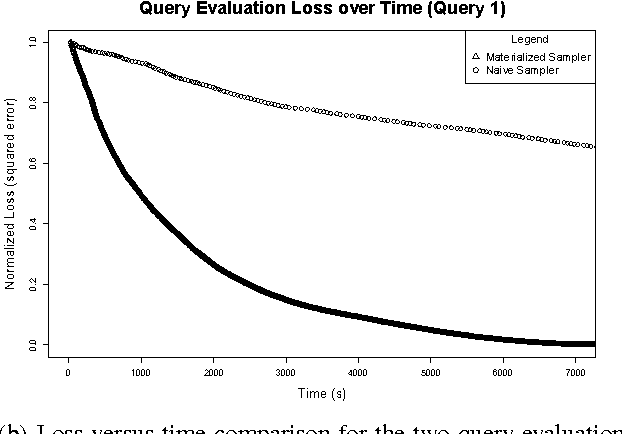
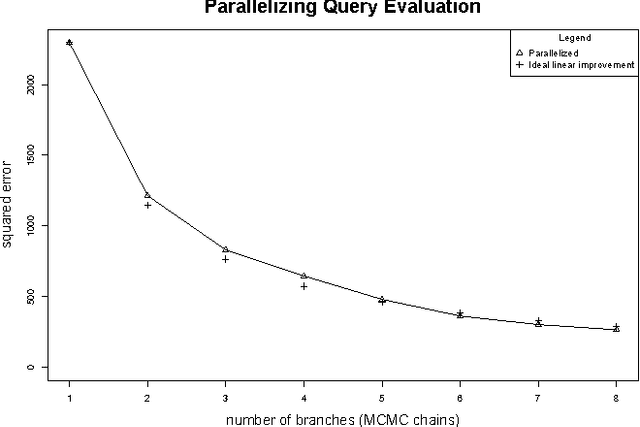
Probabilistic databases play a crucial role in the management and understanding of uncertain data. However, incorporating probabilities into the semantics of incomplete databases has posed many challenges, forcing systems to sacrifice modeling power, scalability, or restrict the class of relational algebra formula under which they are closed. We propose an alternative approach where the underlying relational database always represents a single world, and an external factor graph encodes a distribution over possible worlds; Markov chain Monte Carlo (MCMC) inference is then used to recover this uncertainty to a desired level of fidelity. Our approach allows the efficient evaluation of arbitrary queries over probabilistic databases with arbitrary dependencies expressed by graphical models with structure that changes during inference. MCMC sampling provides efficiency by hypothesizing {\em modifications} to possible worlds rather than generating entire worlds from scratch. Queries are then run over the portions of the world that change, avoiding the onerous cost of running full queries over each sampled world. A significant innovation of this work is the connection between MCMC sampling and materialized view maintenance techniques: we find empirically that using view maintenance techniques is several orders of magnitude faster than naively querying each sampled world. We also demonstrate our system's ability to answer relational queries with aggregation, and demonstrate additional scalability through the use of parallelization.