 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Explicit Unit-Distance Lower-Bound Certificates
Jun 03, 2026The 2026 disproof of Erdős's unit-distance conjecture and Sawin's subsequent explicit quantitative refinement show that the maximum number $u(n)$ of unit distances among $n$ planar points can exceed $n^{1+\varepsilon}$ for a fixed positive $\varepsilon$. Sawin's explicit bound gives more than $n^{1.014}$ unit distances for arbitrarily large $n$ and exposes integer parameters whose choice is not fully optimized. This report starts from Sawin's nonlinear integer optimization problem and develops an open-source Python verification pipeline. The pipeline is first validated by reproducing Sawin's published parameter choice and is then applied to computationally improved certificates. We optimize and verify certificates involving sets of primes $T$ and $S_Q$, integer multiplicities $k(p)$, and a rationally encoded real parameter $R$. The implementation is deliberately lean, so that all results can be replicated on standard hardware and the procedures can be extended. We compare a deterministic greedy heuristic, a tailored integer evolution strategy with two-sided geometric, or discrete-Laplace, integer mutation and repair operators for number-theoretic feasibility, and a two-parent discrete-recombination variant. Four certificate levels are reported: Sawin's published example with $δ=0.0141144286784982\ldots$, a greedy certificate with $δ=0.0151718056372133\ldots$, a tailored integer evolution strategy certificate with $R=6672416/100000$ and $δ=0.0152616610684193\ldots$, and a recombination variant with the same $R$ and $δ=0.0152628688170072\ldots$. Consequently, the best current certificate supports the cautious statement $u(n)>n^{1.0152}$ for arbitrarily large $n$. Beyond this unit-distance application, the work illustrates how randomized optimization heuristics can improve explicit certificates in pure mathematics and combinatorial geometry.
Preference-Shaped Expected Hypervolume and R2 Improvement: Exact Computation and Monotonicity
May 28, 2026This paper studies preference-shaped expected improvement criteria for Bayesian multiobjective optimization. We consider two indicator families which are often used for similar algorithmic purposes, but which are geometrically different. The hypervolume indicator is based on a dystopian reference point and measures dominated volume in objective space. The R2 indicator is based on a utopian point and evaluates approximation sets through weighted Tchebycheff scalarization envelopes. The purpose of the paper is to make precise which preference transformations preserve exact computation, Pareto compatibility, and monotonicity properties, and which transformations change the underlying geometry. On the hypervolume side, we revisit canonical EHVI through the Deng representation, formulate product-density weighted EHVI in desirability coordinates, discuss cone-based EHVI as ordinary EHVI after a linear cone transformation, and separate these cases from truncated EHVI, where variance monotonicity may fail. On the R2 side, we prove that exact integral R2 improvement is not, in general, an ordinary objective-space weighted hypervolume. The obstruction is lower-dimensional: Lebesgue-density hypervolume cannot see certain boundary contributions that Tchebycheff scalarizations still detect. We then show that exact integral R2 improvement is exactly a scalarization-space volume, namely the measure of the Tchebycheff shadow between the incumbent scalarization envelope and the reference envelope. This representation yields finite-sum ER2I algorithms for discrete R2, quadrature methods for exact integral R2, and an achievement-space Gaussian surrogate formulation in which ER2I is an integral of scalar Gaussian expected improvements.
Exact Uniform L1 Spacing for Solow-Polasky Diversity on Lines and Ordered Pareto Fronts
May 21, 2026We study fixed-cardinality maximization of the inverse-matrix Solow--Polasky diversity, equivalently finite metric magnitude for the exponential kernel, on one-dimensional and ordered metric sets. The analysis starts from the known finite-line gap formula for the exponential kernel, which writes the excess inverse-matrix diversity as a sum of functions of consecutive gaps. Building on this formula, the main interval theorem proves that, for every $k\geq 2$, the unique maximizing $k$-point subset of $[0,1]$ is the equally spaced set. Thus the objective selects a uniform gap representation on the real line. A converse kernel proposition shows that, among normalized non-increasing distance kernels, requiring the corresponding adjacent-gap additive structure forces the exponential family. Further results transfer the interval theorem to ordered $\ell_1$ (L1, or Manhattan) curves by isometry: the maximizing sets are uniform in accumulated $\ell_1$ length. As a consequence, monotone biobjective Pareto fronts admit Solow--Polasky optimal finite approximations that are uniformly spaced in accumulated objective-space change, a natural representation when all parts of a continuous front should be covered. Examples, including a dense connected front and a finite disconnected ZDT3 front, illustrate how the continuous uniform-gap result appears on discrete candidate sets. Solow-Polasky diversity; diversity measures; finite metric magnitude; L1 distance; uniform spacing; Pareto-front approximation; multiobjective optimization; fixed-cardinality subset selection
Nonsmooth Set-Gradient Ascent to the Pareto Front via Layered Hypervolume and Magnitude Indicators
May 13, 2026A nonsmooth set-gradient ascent method is developed for moving finite approximation sets toward the Pareto front in multiobjective optimization. The method optimizes layered set indicators: a base indicator is evaluated on successive nondomination layers, and the layer values are combined with rapidly decreasing weights. This gives ascent directions to nondominated and dominated points while preventing deeper layers from compensating for deterioration of the first front. Two base indicators are treated: the hypervolume indicator and the magnitude indicator of the dominated set, whose expansion over coordinate projections contains extent, projected-area, and volume terms. The scalar objectives are nonsmooth because nondomination layers change combinatorially and the active orthogonal-union geometry changes piecewise. On fixed strata, where layer assignments and active geometry remain unchanged, the indicators are piecewise smooth and chamberwise continuous. For the magnitude indicator, an exact gradient formula is derived as a linear combination of hypervolume gradients of projected shadow sets. Thus, for fixed objective dimension, magnitude gradients have the same asymptotic time complexity as hypervolume gradients. Lexicographic layer aggregation is related to a unary infinitesimal encoding. For finite-$ε$ surrogates, the main nonsmoothness mechanisms are isolated and chamberwise Lipschitz continuity on bounded sets is proved; a two-point counterexample shows that hard-layer scalarization is not globally continuous across layer switches. The theory motivates a projected finite-difference implementation with repulsion and recovery from stagnation. Numerical examples and reproducible code cover two- and three-objective settings, including objective-space tests, curved fronts, a supersphere benchmark, and traces comparing layered magnitude and hypervolume ascent.
The Magnitude of Dominated Sets: A Pareto Compliant Indicator Grounded in Metric Geometry
Apr 20, 2026We investigate \emph{magnitude} as a new unary and strictly Pareto-compliant quality indicator for finite approximation sets to the Pareto front in multiobjective optimization. Magnitude originates in enriched category theory and metric geometry, where it is a notion of size or point content for compact metric spaces and a generalization of cardinality. For dominated regions in the \(\ell_1\) box setting, magnitude is close to hypervolume but not identical: it contains the top-dimensional hypervolume term together with positive lower-dimensional projection and boundary contributions. This paper gives a first theoretical study of magnitude as an indicator. We consider multiobjective maximization with a common anchor point. For dominated sets generated by finite approximation sets, we derive an all-dimensional projection formula, prove weak and strict set monotonicity on finite unions of anchored boxes, and thereby obtain weak and strict Pareto compliance. Unlike hypervolume, magnitude assigns positive value to boundary points sharing one or more coordinates with the anchor point, even when their top-dimensional hypervolume contribution vanishes. We then formulate projected set-gradient methods and compare hypervolume and magnitude on biobjective and three-dimensional simplex examples. Numerically, magnitude favors boundary-including populations and, for suitable cardinalities, complete Das--Dennis grids, whereas hypervolume prefers more interior-filling configurations. Computationally, magnitude reduces to hypervolume on coordinate projections; for fixed dimension this yields the same asymptotic complexity up to a factor \(2^d-1\), and in dimensions two and three \(Θ(n\log n)\) time. These results identify magnitude as a mathematically natural and computationally viable alternative to hypervolume for finite Pareto front approximations.
Comparative Analysis of Indicators for Multiobjective Diversity Optimization
Oct 24, 2024



Indicator-based (multiobjective) diversity optimization aims at finding a set of near (Pareto-)optimal solutions that maximizes a diversity indicator, where diversity is typically interpreted as the number of essentially different solutions. Whereas, in the first diversity-oriented evolutionary multiobjective optimization algorithm, the NOAH algorithm by Ulrich and Thiele, the Solow Polasky Diversity (also related to Magnitude) served as a metric, other diversity indicators might be considered, such as the parameter-free Max-Min Diversity, and the Riesz s-Energy, which features uniformly distributed solution sets. In this paper, focusing on multiobjective diversity optimization, we discuss different diversity indicators from the perspective of indicator-based evolutionary algorithms (IBEA) with multiple objectives. We examine theoretical, computational, and practical properties of these indicators, such as monotonicity in species, twinning, monotonicity in distance, strict monotonicity in distance, uniformity of maximizing point sets, computational effort for a set of size~n, single-point contributions, subset selection, and submodularity. We present new theorems -- including a proof of the NP-hardness of the Riesz s-Energy Subset Selection Problem -- and consolidate existing results from the literature. In the second part, we apply these indicators in the NOAH algorithm and analyze search dynamics through an example. We examine how optimizing with one indicator affects the performance of others and propose NOAH adaptations specific to the Max-Min indicator.
The Hypervolume Indicator Hessian Matrix: Analytical Expression, Computational Time Complexity, and Sparsity
Nov 15, 2022



The problem of approximating the Pareto front of a multiobjective optimization problem can be reformulated as the problem of finding a set that maximizes the hypervolume indicator. This paper establishes the analytical expression of the Hessian matrix of the mapping from a (fixed size) collection of $n$ points in the $d$-dimensional decision space (or $m$ dimensional objective space) to the scalar hypervolume indicator value. To define the Hessian matrix, the input set is vectorized, and the matrix is derived by analytical differentiation of the mapping from a vectorized set to the hypervolume indicator. The Hessian matrix plays a crucial role in second-order methods, such as the Newton-Raphson optimization method, and it can be used for the verification of local optimal sets. So far, the full analytical expression was only established and analyzed for the relatively simple bi-objective case. This paper will derive the full expression for arbitrary dimensions ($m\geq2$ objective functions). For the practically important three-dimensional case, we also provide an asymptotically efficient algorithm with time complexity in $O(n\log n)$ for the exact computation of the Hessian Matrix' non-zero entries. We establish a sharp bound of $12m-6$ for the number of non-zero entries. Also, for the general $m$-dimensional case, a compact recursive analytical expression is established, and its algorithmic implementation is discussed. Also, for the general case, some sparsity results can be established; these results are implied by the recursive expression. To validate and illustrate the analytically derived algorithms and results, we provide a few numerical examples using Python and Mathematica implementations. Open-source implementations of the algorithms and testing data are made available as a supplement to this paper.
Improving Many-objective Evolutionary Algorithms by Means of Expanded Cone Orders
Apr 15, 2020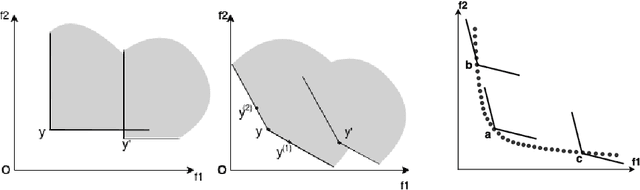
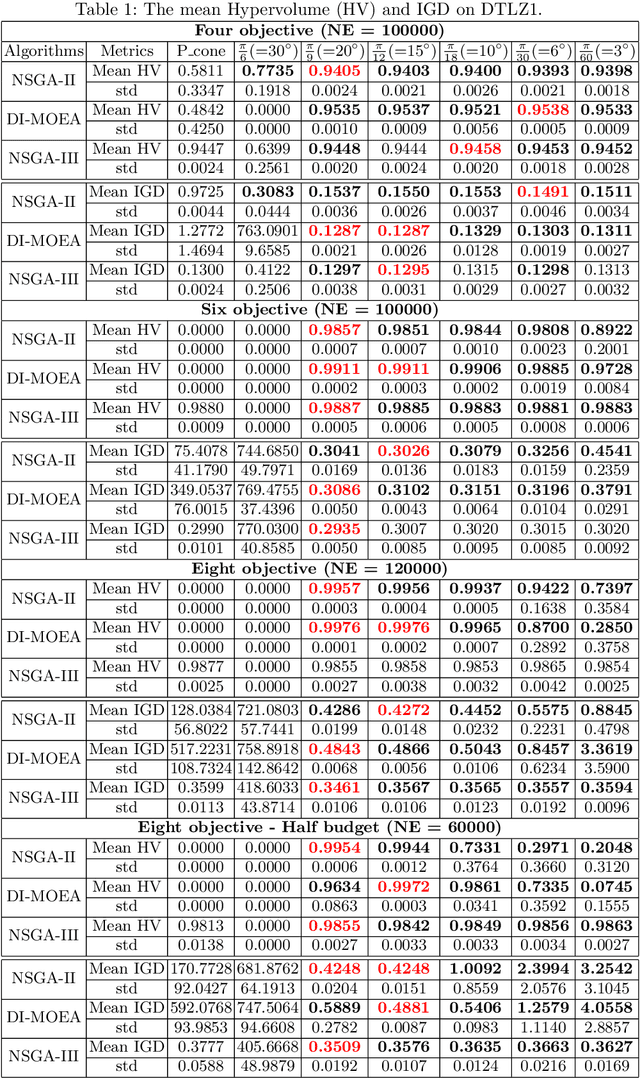
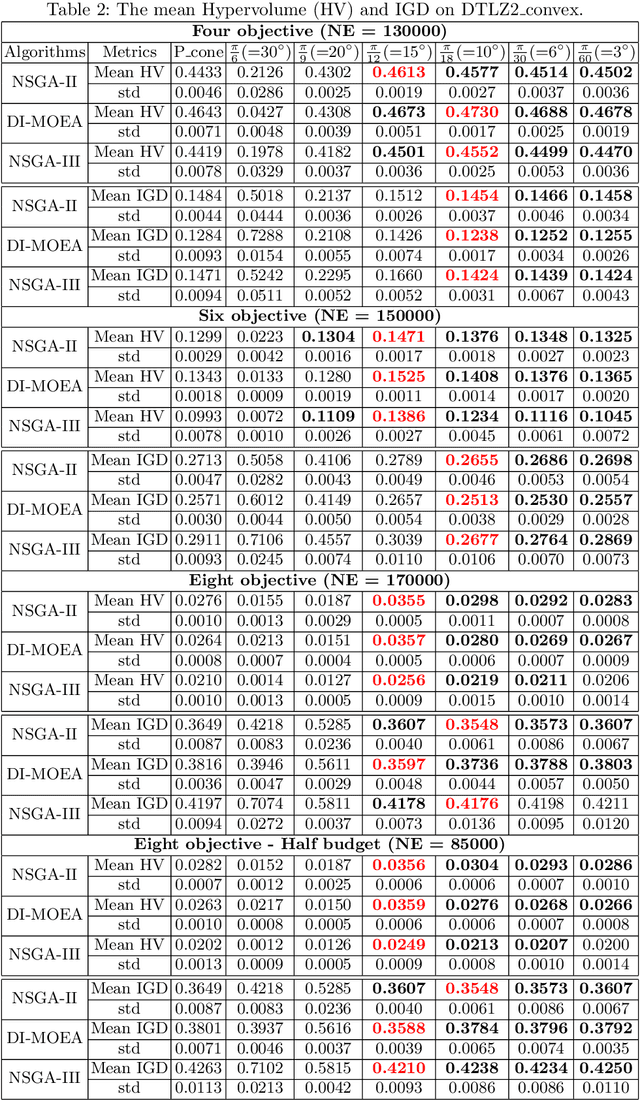
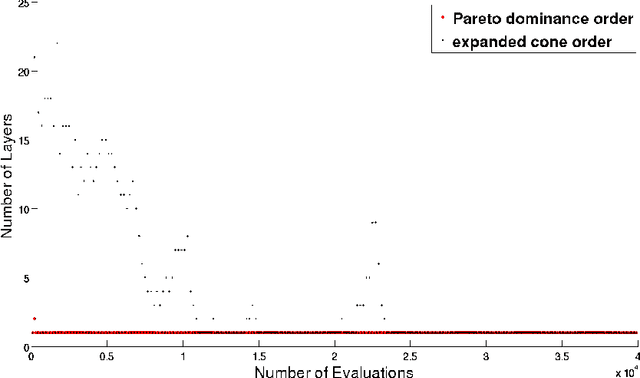
Given a point in m-dimensional objective space, the local environment of a point can be partitioned into the incomparable, the dominated and the dominating region. The ratio between the size of the incomparable region, and the dominated (and dominating) decreases proportionally to $1/2^{m-1}$. Due to this reason, it gets increasingly unlikely that dominating points can be found by random, isotropic mutations. As a remedy to stagnation of search in many objective optimization, in this paper, we suggest to enhance the Pareto dominance order by involving a convex obtuse dominance cone in the convergence phase of an evolutionary optimization algorithm. The approach is integrated in several state-of-the-art multi-objective evolutionary algorithms (MOEAs) and tested on benchmark problems with four, five, six and eight objectives. Computational experiments demonstrate the ability of the expanded cone technique to improve the performance of MOEAs on many-objective optimization problems.
A Tailored NSGA-III Instantiation for Flexible Job Shop Scheduling
Apr 14, 2020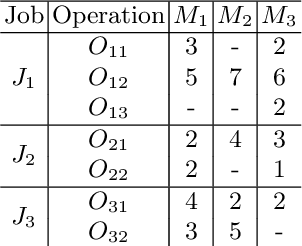
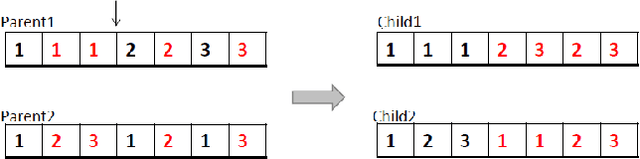
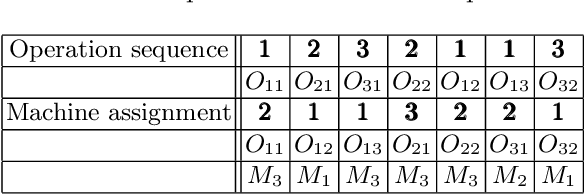
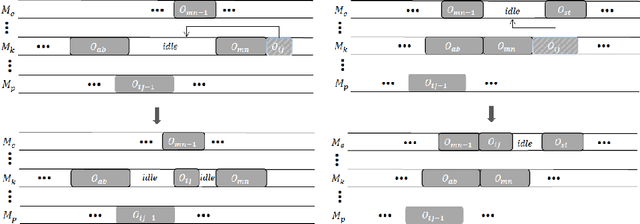
A customized multi-objective evolutionary algorithm (MOEA) is proposed for the multi-objective flexible job shop scheduling problem (FJSP). It uses smart initialization approaches to enrich the first generated population, and proposes various crossover operators to create a better diversity of offspring. Especially, the MIP-EGO configurator, which can tune algorithm parameters, is adopted to automatically tune operator probabilities. Furthermore, different local search strategies are employed to explore the neighborhood for better solutions. In general, the algorithm enhancement strategy can be integrated with any standard EMO algorithm. In this paper, it has been combined with NSGA-III to solve benchmark multi-objective FJSPs, whereas an off-the-shelf implementation of NSGA-III is not capable of solving the FJSP. The experimental results show excellent performance with less computing budget.
Multiobjective Optimization of Classifiers by Means of 3-D Convex Hull Based Evolutionary Algorithm
Dec 18, 2014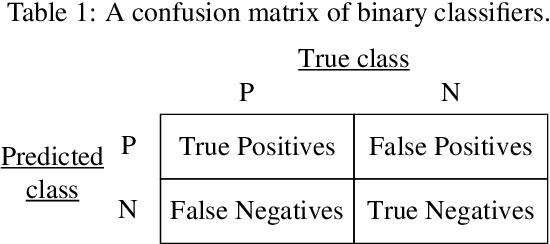
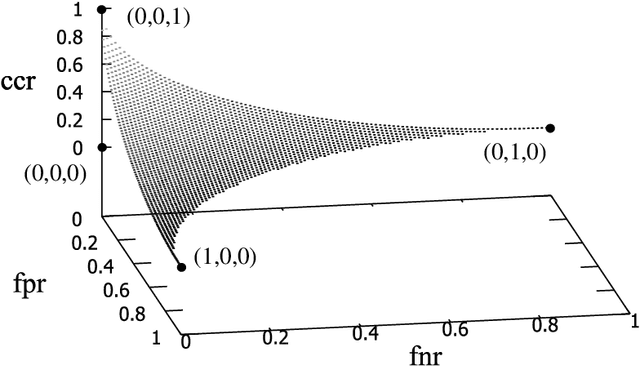
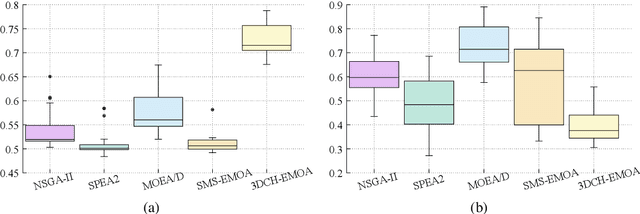
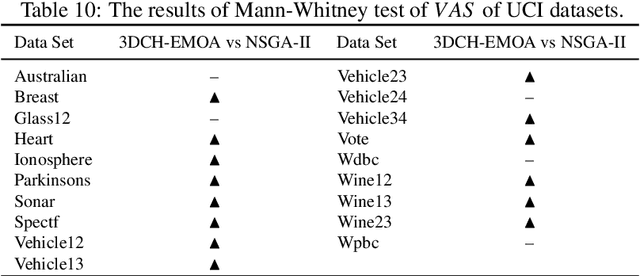
Finding a good classifier is a multiobjective optimization problem with different error rates and the costs to be minimized. The receiver operating characteristic is widely used in the machine learning community to analyze the performance of parametric classifiers or sets of Pareto optimal classifiers. In order to directly compare two sets of classifiers the area (or volume) under the convex hull can be used as a scalar indicator for the performance of a set of classifiers in receiver operating characteristic space. Recently, the convex hull based multiobjective genetic programming algorithm was proposed and successfully applied to maximize the convex hull area for binary classification problems. The contribution of this paper is to extend this algorithm for dealing with higher dimensional problem formulations. In particular, we discuss problems where parsimony (or classifier complexity) is stated as a third objective and multi-class classification with three different true classification rates to be maximized. The design of the algorithm proposed in this paper is inspired by indicator-based evolutionary algorithms, where first a performance indicator for a solution set is established and then a selection operator is designed that complies with the performance indicator. In this case, the performance indicator will be the volume under the convex hull. The algorithm is tested and analyzed in a proof of concept study on different benchmarks that are designed for measuring its capability to capture relevant parts of a convex hull. Further benchmark and application studies on email classification and feature selection round up the analysis and assess robustness and usefulness of the new algorithm in real world settings.